
Amazon Rekognition カスタムラベル完全に理解した(と思ってる):モデル評価と運用編

noteの投稿で本題を考えるより前説を考えることに時間をかけがちな「ぎだじゅん」です。
ライフイズテックという会社でサービス開発部 インフラ/SREグループに所属しています。
世代的にテレビっ子な私ですが、すっかりテレビを見る機会が減ってきました。
その理由の一つに、最近のテレビを見ていてもタレントさんの顔がみんな同じ顔に見えてしまうというのがあります。
ドラマとか見ても、中盤で「あれっ?この人、悪役じゃなかったっけ?」と思ったら別の人だったってことがよくあります。
さらにグループ系のアーティストはみんな同じような顔の子(?)が複雑なフォーメーションで動いて歌うので、誰だかわからなくなり必然的に「単推し」ではなく「箱推し」しかできなくなってしまいます。

その「箱推し」でさえも、どのグループ所属の方なのかわからないぐらいにそれぞれのグループの方々も同じ顔に見えるので、もう自分には「推し活」たるものができないと悲しみに暮れることもありました。

単に記憶力が低下したのかなと思ったこともありましたが、今回のRekognitionカスタムラベルでの学習モデルのトレーニングを経験して、単純に見るものに対しての学習が足りないから判別できないのであって、ちゃんと興味をもって学習すれば識別できるようになるからあきらめちゃダメだと感じました。
(って勝手に解釈しています)
本題です。
■前編のおさらい
前回、こちらでAmazon Rekognition カスタムラベルについての説明や、学習モデルの構築について紹介しました。
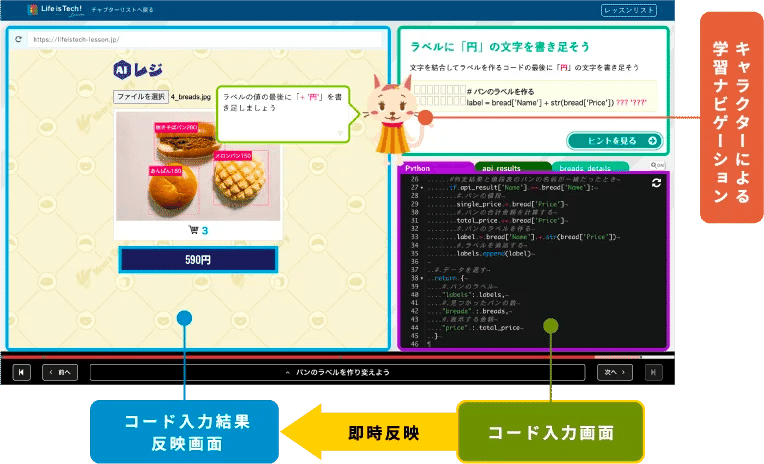
改めて紹介となりますが、ライフイズテックの中学校や高校などに提供しているデジタル学習教材「ライフイズテック レッスン」の中で、画像分析の機能を使ってパン屋さんなどのAIレジの集計部分がどのようにできているかを学習するレッスンがあります。
そして画像からパンの種類を判別する裏側の機能ではAmazon Rekognition のカスタムラベル を使用しています。
今回、このAmazon Rekognition カスタムラベルの環境を、改めて東京リージョンで作成する機会があり構築しました。
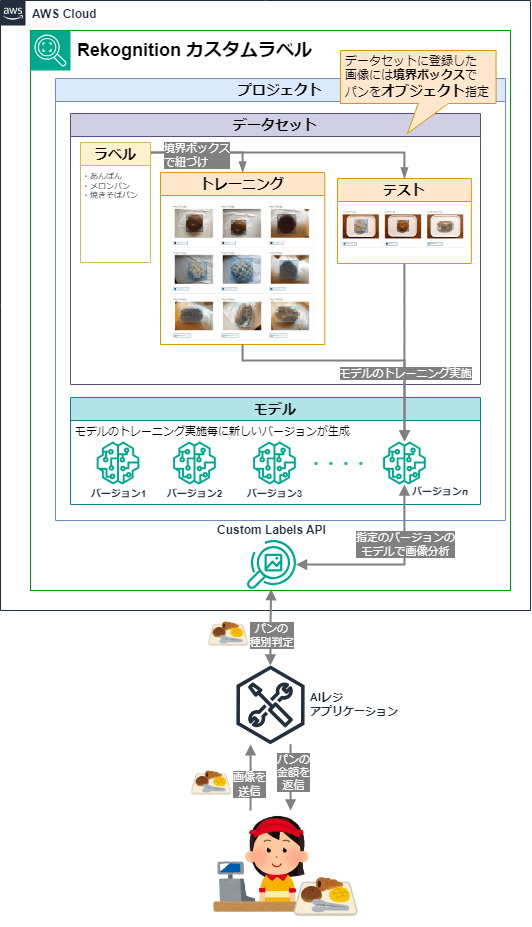
パン画像判別の裏側では、以下のような構成でAmazon Rekognition カスタムラベルの環境を構築しています。
前編では構築自体はうまくいったのですが、実際にパン画像を使って画像分析をして見たところ、想定していない結果が返ってきました・・・。
今回は、実際に画像を使った画像分析のリクエストとその結果の内容、誤判定の改善内容についてご紹介します。
Amazon Rekognition カスタムラベルについては前回の投稿やこちらを参考にしてください。
■テストデータセットの評価結果を振り返り
前回の環境構築編でテストデータセットによる評価結果(テスト結果)まで紹介しましたが、もう一度評価結果(テスト結果)を振り返ります。
評価結果(テスト結果)は「モデル」画面の「評価」タブ画面にある隠しボタンのような四角いボタンを押すと表示されます(コンソールの言語が「日本語」の場合)。
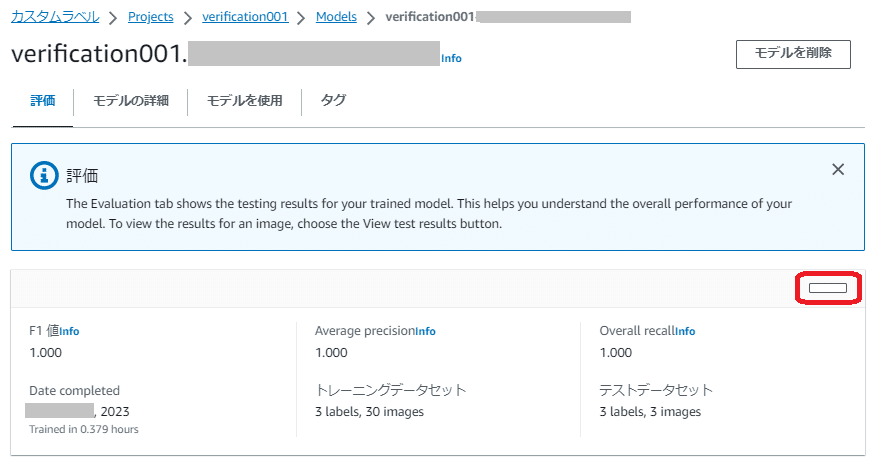
コンソールの言語を「English(US)」にするとボタン名が「View test results」と表示されます。
ここではトレーニングされた学習モデルでテストデータセットの画像を分析した結果を確認できます。
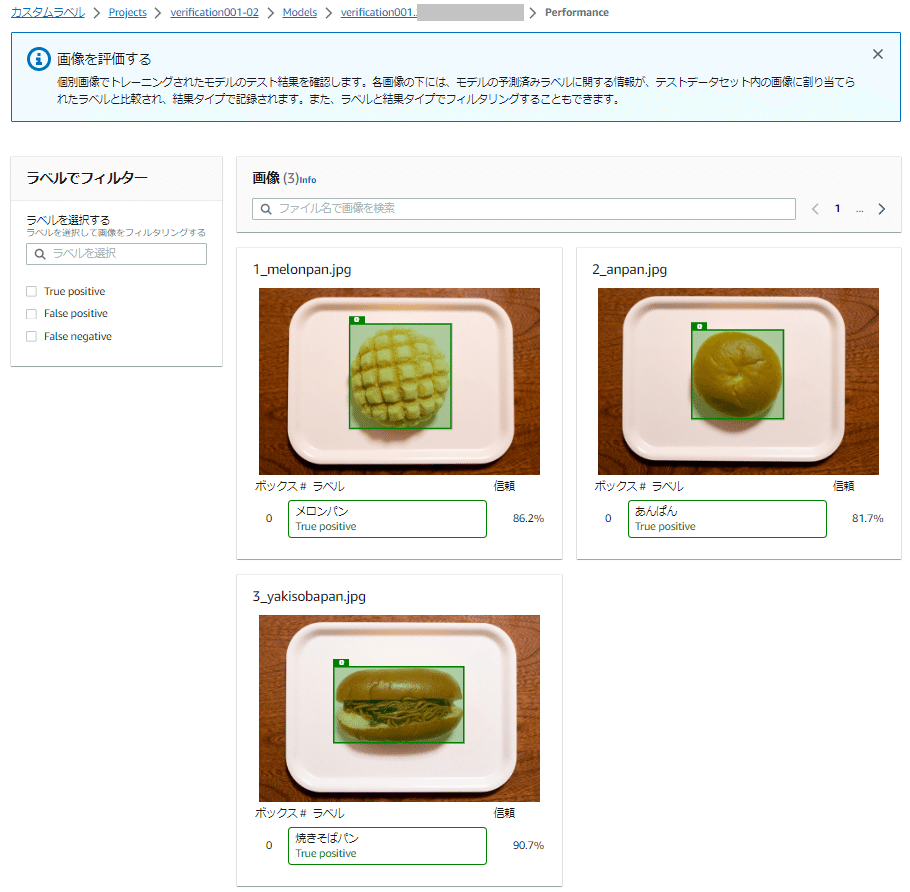
テスト画像の下には、テストデータセットのセットアップで指定した境界ボックスのラベルによる分析結果が表示されます。
テストデータセットの画像のオブジェクトでは、境界ボックスとラベル(ボックス# ラベル)で以下のような評価結果を返します。
True Positive(真陽性)
テストデータセットで割り当てられたラベルがモデルによって正しく識別されたことを示します
Palse Positive(偽陽性)
テスト画像にラベル付けしていないラベルがモデルで予測されたことを示します
False Negative(偽陰性)
テスト画像に存在するとマークしたラベルがモデルで予測されなかったことを示します。
「信頼」列で表示されている「Confidence(信頼度)」のスコアは、テスト画像のオブジェクトで検出されたラベルによる、モデルの予測の確実性を定量化する値です。
それぞれの画像のオブジェクトで検出されたラベルの「信頼度」のスコアは以下のようになりました。
あんぱん: 81.7% (0.817)
メロンパン: 86.2% (0.862)
焼きそばパン: 90.7% (0.907)
今回の結果だと、例えば「焼きそばパン」のテスト画像で検出されたオブジェクト(パン)は「焼きそばパン」である可能性が90.7%であるということになります。
先ほどのモデルの「評価」タブで表示されていた「ラベルごとのパフォーマンス」欄の「Assumed threshold(想定しきい値)」の値を見てみると、テスト結果の「Confidence(信頼度)」スコアと同じ数値(パーセンテージを数値で表記)になっていることがわかります。
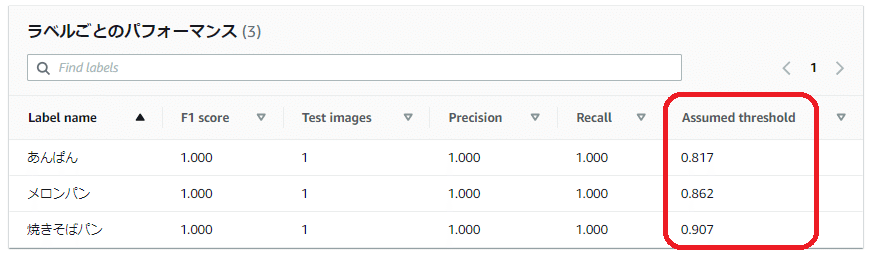
この「Assumed threshold(想定しきい値)」は、モデルトレーニング中にテストデータセットで達成された最高の F1 スコア(いずれも1.000)に基づいて自動で計算されます。
想定しきい値
Amazon Rekognition カスタムラベルは、各カスタムラベルの想定しきい値 (0-1) を自動的に計算します。カスタムラベルの想定しきい値を設定することはできません。各ラベルの想定しきい値は、この値を超えると予測が真陽性または偽陽性とカウントされます。テストデータセットに基づいて設定されます。想定される閾値は、モデルトレーニング中にテストデータセットで達成された最高の F1 スコアに基づいて計算されます。
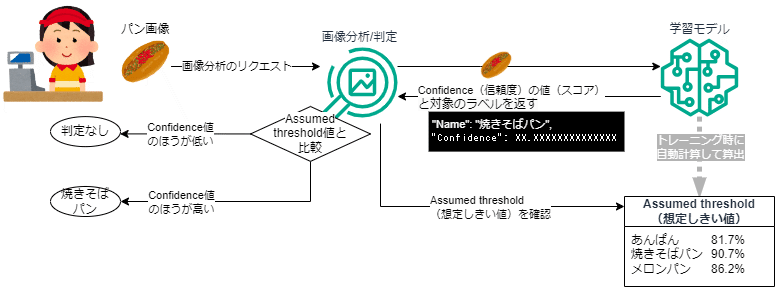
オブジェクトのラベル判定方法
Amazon Rekognition カスタムラベルの学習モデルでは、前述の「Assumed threshold(想定しきい値)」がラベル判定のしきい値となります。
この学習モデルで画像分析を行った際に、画像の中のオブジェクトに判定された Confidence(信頼度)のスコアが、各ラベルで設定された Assumed threshold(想定しきい値)を超えると、その想定しきい値のラベルに該当すると判定(予測)されるようです。
モデルのパフォーマンスの評価
テスト中、Amazon Rekognition カスタムラベルはテスト画像にカスタムラベルが含まれているかどうかを予測します。信頼スコアは、モデルの予測の確実性を定量化する値です。カスタムラベルの信頼スコアがしきい値を超える場合、モデル出力にはこのラベルが含まれます。
判定(予測)の結果は以下のように分類されるようです。
正解
Amazon Rekognition カスタムラベルモデルは、テスト画像内のカスタムラベルの存在を正しく予測します。つまり、予測されたラベルは、その画像の「グラウンドトゥルス」ラベルでもあります。
たとえば、Amazon Rekognition カスタムラベルは、画像にサッカーボールが含まれている場合にサッカーボールのラベルを正しく返します。
誤検知
Amazon Rekognition カスタムラベルモデルは、テスト画像内のカスタムラベルの存在を誤って予測します。つまり、予測ラベルは画像のグラウンドトゥルースラベルではありません。
たとえば、Amazon Rekognition Custom Labels はサッカーボールのラベルを返しますが、その画像のグラウンドトゥルースにはサッカーボールのラベルがありません。
誤検知
Amazon Rekognition Custom Labels モデルでは、画像にカスタムラベルが存在することは予測されませんが、その画像の「原理」にはこのラベルが含まれます。
たとえば、Amazon Rekognition カスタムラベルでは、サッカーボールを含む画像の「サッカーボール」カスタムラベルは返されません。
真否定
Amazon Rekognition カスタムラベルモデルは、カスタムラベルがテスト画像に存在しないことを正しく予測します。
たとえば、Amazon Rekognition カスタムラベルでは、サッカーボールが含まれていない画像のサッカーボールラベルは返されません。
例として焼きそばパンのオブジェクトを含む画像を分析した際に、オブジェクトに対して、
正しいラベル(焼きそばパン)の信頼度のスコアが想定しきい値を超えて判定(予測)されたら正解
正しくないラベル(焼きそばパン以外)の信頼度のスコアが想定しきい値を上回って判定(予測)されてしまったら誤検知
正しいラベル(焼きそばパン)の信頼度のスコアが想定しきい値を下回ったら正しいラベルは判定(予測)されず誤検知
正しいラベル(焼きそばパン)が検出されない場合は真否定
という感じで理解しましたが、少し違ってたらごめんなさい。
■Custom Labels APIへ画像分析のリクエストしてみよう
実際にトレーニングデータセットやテストデータセットで使った画像以外のパン画像で、Custom Labels APIに画像分析のリクエストを投げた結果を確認してみました。
今回は、AWSから提供されているCLIのコマンド「aws rekognition detect-custom-labels ~」を使ってCustom Labels APIへ画像分析を実行しました。
S3バケットにアップした画像ファイルに対して画像分析するようにAPIへリクエストを投げ、返ってきたレスポンスの結果から判定(予測)内容を確認します。
その前に、カスタムラベルの学習モデルを使用するには「モデルの開始」の処理をする必要があります。
(モデル作成直後は、該当のモデルは停止した状態になっています)
学習モデルを開始する
該当のプロジェクトのモデルを以下の流れで開始します。


(開始完了までは上記の表示になります)

モデルを開始すると料金が発生するので、検証などで学習モデルを開始している場合は検証が完了したら必ずモデルの停止を忘れないようにしてください。
これで学習モデルが開始できたので、実際にAWSのCLIコマンドで画像分析をリクエストしてみます。
AWS CLIコマンドで画像判定してみる
今回、以下のような一つの画商に三種類のパンが映っている画像を用意しました。

この画像を任意のS3バケットへアップロードしておき、AWS CLIコマンドでS3バケットの画像を指定して画像分析のリクエストを行います。
AWS CLIコマンドを実行するには、実行するIAMユーザ(またはIAMロール)に、実行に必要な権限があらかじめ付与されている必要があります。
AWS CLIのセットアップについてはこちらを参考にしてください。
ちなみに該当のモデルの「モデルを使用」タブ画面にある「モデルを使用」欄では、AWS CLIコマンドやPythonでのコードで以下の処理を実行をするためのAPIコードを提示してくれます。
モデルを開始する
画像を分析する
モデルを停止する
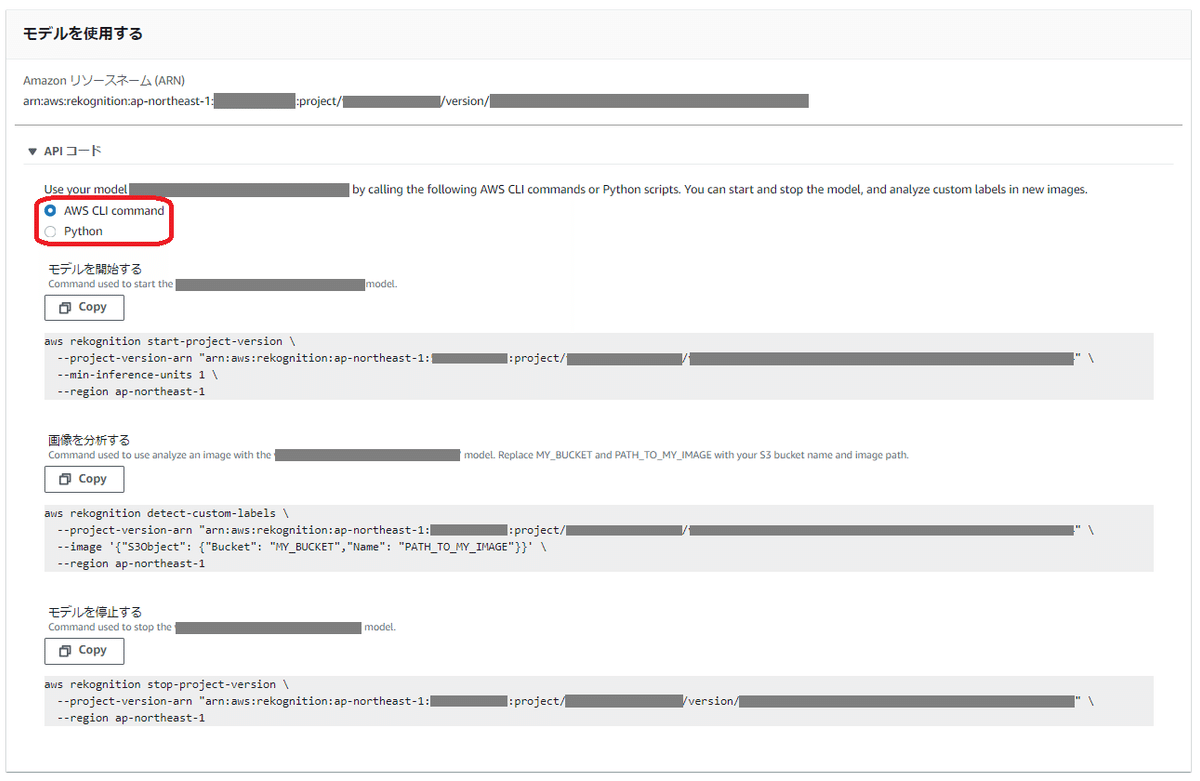
今回はこの画面に表示されているAWS CLIコマンドの「画像を分析する」のサンプルコード( aws rekognition detect-custom-labels ~ )を使って分析を行います。
aws rekognition detect-custom-labels \
--project-version-arn <model_arn> \
--image '{"S3Object":{"Bucket":"<bucket>","Name":"<image>"}}' \
--region ap-northeast-1「--project-version-arn」 の「<model_arn>」には、使用するモデルの「Amazon リソースネーム (ARN)」が指定されています
ここで指定するARNは「モデルを使用」タブ画面にある「モデルを使用する」で表記されている「Amazon リソースネーム (ARN)」でも確認できます
「--image」で指定しているS3ObjectのBucketの「<bucket>」には、分析対象の画像が置いてあるS3バケット名、Nameの「<image>」には分析対象の画像のPrefixとファイル名を記入してください
例としてS3バケット名の「chekimagebkt」のフォルダ(Prefix)「check」配下のファイル名「breads3.jpg」の場合は「--image '{"S3Object":{"Bucket":"chekimagebkt","Name":"check/breads3.jpg"}}'」と指定します
S3バケットではなくローカルにある画像ファイルを指定する場合は「--image 〜」ではなく、「--image-bytes fileb://<画像ファイルの場所>」で指定もできます
「--region」は東京リージョンにあるモデルのため「ap-northeast-1」と指定されています
AWS CLIコマンドの「detect-custom-labels」の他のオプションや詳細についてはこちらを参考にしてください
なお、今回はAWS CLIコマンドでCustom Labels APIに対して画像分析を行いましたが、AWSから提供されるSDKをアプリケーションに組み込んだり、LambdaのPytonでboto3を使ったりして、Custom Labels APIに画像分析をリクエストすることもできますので、AWS CLIコマンド以外での画像分析については以下を参考にしてください。
ということで、前述の画像を指定して画像分析をリクエストしてみました。
ところが・・・

判定結果(レスポンス)は以下のとおりでメロンパンしか判定してくれませんでした。
あんぱんと焼きそばパンは何処へ・・・
{
"CustomLabels": [
{
"Name": "メロンパン",
"Confidence": 88.00399780273438,
"Geometry": {
"BoundingBox": {
"Width": 0.31696000695228577,
"Height": 0.48267999291419983,
"Left": 0.5984500050544739,
"Top": 0.33976998925209045
}
}
}
]
}Name は検出されたラベル名になります
Confidence は前項でも説明した通り、分析対象の画像で検出されたオブジェクトのラベルの「信頼度」のスコアになります
Geometry の BoundingBox はラベルに対応する画像上で検出されたオブジェクトの位置を指しており、検出されたオブジェクトを囲む軸に合わせた境界ボックスの位置を示します
Height – 画像全体の高さの比率としての境界ボックスの高さ
Left – 画像全体の幅の比率としての境界ボックスの左座標
Top – 画像全体の高さの比率としての境界ボックスの上端座標
Width – 画像全体の幅の比率としての境界ボックスの幅
今回使用した学習モデルの Assumed threshold(想定しきい値) は以下のようになっています。
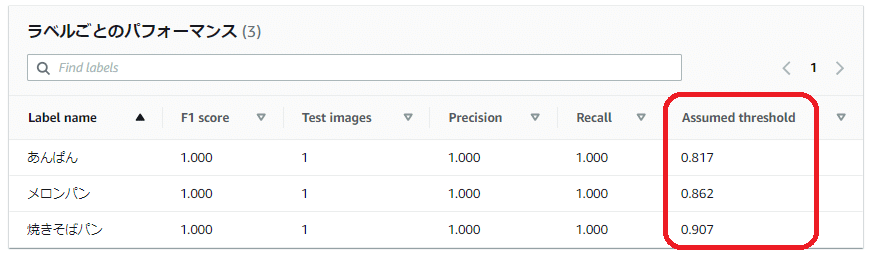
あんぱん: 81.7% (0.817)
メロンパン: 86.2% (0.862)
焼きそばパン: 90.7% (0.907)
メロンパンの Confidence (信頼度) の値が「88.00399780273438:だったので、おそらくメロンパン以外は Assumed threshold(想定しきい値) を下回ってラベル判定されなかったことが考えられますが、実際に Confidence (信頼度) がどれくらいだったかは判定結果のレスポンスに含まれていないのでわりません。
どうすればよいんでしょう・・・

■学習モデルの判定精度を改善するには
学習モデルの判定精度を改善するには、以下の方法を行うことになります。
誤判定した画像自体をトレーニングデータセットに追加して境界ボックスとラベルの紐づけをして追加トレーニングする
追加トレーニングすると新しいモデルのバージョンが生成されるので、画像分析のリクエスト元で指定しているAPIのパラメータのARN(--project-version-arn)を新しいモデルのバージョンのARNに指定変更する必要があります。
リクエストのパラメータで MinConfidence(最小の信頼度) を利用
MinConfidenceの値をAssumed threshold(想定しきい値)よりも少し小さい値で指定してリクエストする
(--min-confidenceで値を0~100の範囲から指定)「Assumed threshold(想定しきい値)」に関係なく、MinConfidenceで指定された値よりも高いConfidence(信頼度)を持つラベルはレスポンスに判定(予測)できたラベルとして返す
MinConfidenceの数値を下げ過ぎると、一つのオブジェクトで複数のラベルを検出するなどの誤検出が発生する場合もあるので指定する数値には要注意
トレーニングデータセットのラベル設定に誤りがないか確認する
ラベル設定に誤りがあれば修正してトレーニングしなおす
境界ボックスを調整してトレーニングしなおす
詳しくはこちらを参考にしてください。
今回、3. については問題ないことを確認しました。
1. の方法で、正解とならなかった画像をトレーニングデータセットの画像として追加登録して境界ボックスと該当のラベルを紐づけして、再度モデルのトレーニングをすれば判定精度は上がると思いますが、実際のところ「メロンパン」以外がどれくらいの Confidence(信頼度) のスコアだったのかを知っておきたいです。
判定されなかったラベルの信頼度スコアを確認する
ついては、一度 2. の方法でリクエストのパラメータで MinConfidence(最小の信頼度レベル)を使用し、「メロンパン」以外がどれくらいの Confidence(信頼度) スコアになっているかを確認してみました。
ちなみにMinConfidence(最小の信頼度レベル)を指定しないリクエストと指定したリクエストでは以下のように判定方法が変わる想定です。
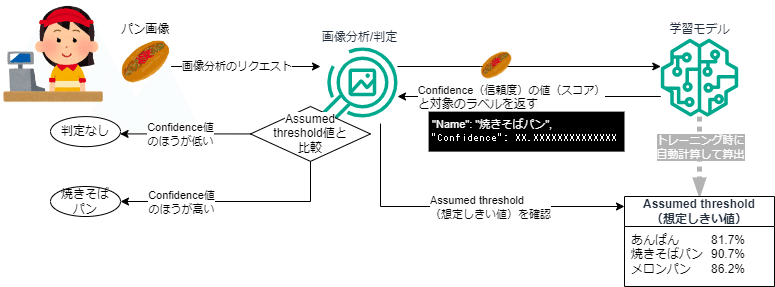
ConfidenceとAssumed thresholdを比較して判別する
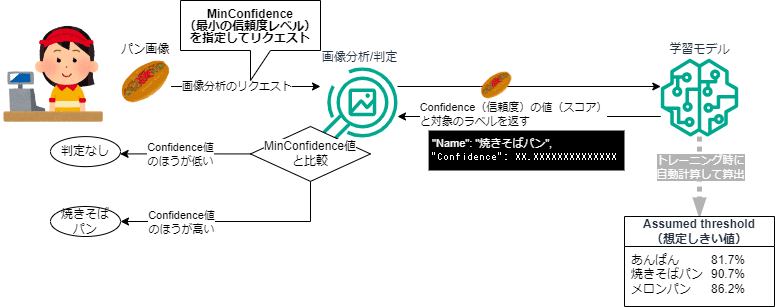
ConfidenceとMinConfidenceを比較して判別する
(Assumed threshold では判定しない)
今回のラベルの中で一番低い Assumed threshold(想定しきい値) は「あんぱん」の 81.7% (0.817) なので、MinConfidence(最小の信頼度レベル)を一旦「80」で指定してリクエストを投げてみました。
aws rekognition detect-custom-labels \
--project-version-arn <model_arn> \
--image '{"S3Object":{"Bucket":"<bucket>","Name":"<image>"}}' \
--min-confidence 80 \
--region ap-northeast-1「--min-confidence」で最小の信頼度レベルを「80」で指定
すると以下のようなレスポンス結果になり、「焼きそばパン」は判定結果で返ってくるようになりました。
{
"CustomLabels": [
{
"Name": "焼きそばパン",
"Confidence": 90.44999694824219,
"Geometry": {
"BoundingBox": {
"Width": 0.41152000427246094,
"Height": 0.34727999567985535,
"Left": 0.23639999330043793,
"Top": 0.08641000092029572
}
}
},
{
"Name": "メロンパン",
"Confidence": 88.00399780273438,
"Geometry": {
"BoundingBox": {
"Width": 0.31696000695228577,
"Height": 0.48267999291419983,
"Left": 0.5984500050544739,
"Top": 0.33976998925209045
}
}
}
]
}「焼きそばパン」のラベルでは Assumed threshold(想定しきい値)が 90.7%で、今回判定されているConfidence(信頼度) を見ると 90.5% なので、1回目のリクエストでは「焼きそばパン」のラベル判定がされなかったことが考えられます。
1回目の MinConfidence(最小の信頼度レベル)を指定しないリクエストではConfidence(信頼度) がしきい値を下回るのでラベル判定されなかった
2回目のMinConfidence(最小の信頼度レベル)を指定したリクエストではConfidence(信頼度) がMinConfidence(最小の信頼度レベル)で指定した 80 を上回ったのでラベル判定された
そうなると検出されていない「あんぱん」はConfidence(信頼度)が80以下と考えられるのでMinConfidence(最小の信頼度レベル)を一旦「75」で指定してリクエストを投げてみました。
aws rekognition detect-custom-labels \
--project-version-arn <model_arn> \
--image '{"S3Object":{"Bucket":"<bucket>","Name":"<image>"}}' \
--min-confidence 75 \
--region ap-northeast-1「--min-confidence」で最小の信頼度レベルを「75」で指定
すると、やっと画像に写っている3種類のパンすべてのラベル判定が返ってきました。
以下のようなレスポンス結果になりました。
{
"CustomLabels": [
{
"Name": "焼きそばパン",
"Confidence": 90.44999694824219,
"Geometry": {
"BoundingBox": {
"Width": 0.41152000427246094,
"Height": 0.34727999567985535,
"Left": 0.23639999330043793,
"Top": 0.08641000092029572
}
}
},
{
"Name": "メロンパン",
"Confidence": 88.00399780273438,
"Geometry": {
"BoundingBox": {
"Width": 0.31696000695228577,
"Height": 0.48267999291419983,
"Left": 0.5984500050544739,
"Top": 0.33976998925209045
}
}
},
{
"Name": "あんぱん",
"Confidence": 77.53700256347656,
"Geometry": {
"BoundingBox": {
"Width": 0.3001199960708618,
"Height": 0.4251999855041504,
"Left": 0.1973399966955185,
"Top": 0.468860000371933
}
}
}
]
}「あんぱん」のラベルでは Assumed threshold(想定しきい値)が 81.7% で、今回「あんぱん」でラベル判定されている Confidence(信頼度)を見ると 77.5% なので、1回目のリクエストではラベル判定されなかったことが考えられます。
2回目のリクエストでもMinConfidence(最小の信頼度レベル)が 80 でまだConfidence(信頼度) が下回っているのでラベル判定されず、3回目のリクエストでMinConfidence(最小の信頼度レベル)が 75 でConfidence(信頼度) が上回ったのでラベル判定されたと考えられます。
最終的な改善策
今回、パンの種類を「メロンパン」、「焼きそばパン」、「あんぱん」で画像分析を行いました。
今回の判定結果を踏まえてそれぞれのパンの見た目の特性を考えてみると、「メロンパン」についてはあの網状の模様が特徴をとらえやすくて安定した判定がされたのかなと思います。

逆に「あんぱん」はおへそとなる部分以外の特徴がなく、おへその位置や深さ(に伴う色合い)もパンの出来具合で変わってきそうなので、「あんぱん」についてはもう少しいろんなおへその位置や形のパターンの画像を用意して追加でトレーニングすることで精度を上げれるのかなと思いました。

(おへそのある「あんぱん」とははちょっと違うデザインだけど)
「焼きそばパン」については特徴的な見た目なのでConfidence(信頼度)のスコアが他のパンと比べても高く判定されるものの、 「焼きそばパン」のAssumed threshold(想定しきい値)自体も90%を超えていて高いため、リクエストのMinConfidence(最小の信頼度レベル)で調整する必要があるかなと思いました。

これらを踏まえて今回の学習モデルでの判定を改善するには、以下の二つで対応することになると考えました。
画像分析のリクエスト時にMinConfidence(最小の信頼度レベル)のパラメータを設定し、数値を調整してラベル判定結果を調整する
MinConfidence(最小の信頼度レベル)のパラメータはラベルごとに値の指定はできず、すべてのラベル判定に共通で適用されます
MinConfidence(最小の信頼度レベル)は85以上で指定
誤判定やラベル判定されないオブジェクトの画像があったら、その画像をトレーニングデータセットに追加してラベルと境界ボックスを紐づけて追加トレーニングする
追加トレーニングした場合は、新しいモデルのバージョンが生成されるので、新しいバージョンのモデルで画像分析するには、リクエストする側でのモデル指定のARN(--project-version-arn)を新しいバージョンのモデルのARNに変更してリクエストさせる必要があります
MinConfidence(最小の信頼度レベル)の値は、低すぎると複数の境界ボックスで同じラベル検出してしまうなどの不都合もあったので、MinConfidence(最小の信頼度レベル)は低くても85以上で指定し、Confidence(信頼度)が85未満でラベル判別されないオブジェクトについては、いろんなパターンの画像で追加トレーニングしてConfidence(信頼度)の判定精度を上げていくのが良いかなと思いました。
■学習モデルの開始と停止の自動化
Amazon Rekognition カスタムラベルの料金については、前回の投稿でも触れたので割愛しますが、トレーニング時に発生する料金以外に学習モデルを「RUNNING」の状態にしている間にも料金が発生します。
カスタムモデルをトレーニングした各時間に対して、画像処理のために利用できるコストがあります。1 時間に処理できる画像の数は、多くの要素に応じて決まります。たとえば、処理される画像のサイズやカスタムモデルの複雑さなどです。Amazon Rekognition カスタムラベルでは、画像をより迅速に処理するために並行して複数のコンピューティングリソースを実行する場合があります。つまり、請求される時間数はカスタムモデルのトレーニングに費やす実際の経過時間数よりも多い場合があります。
たとえば、午後 2:00 にカスタムモデルの推論を開始し、午後 5:00 に終了し、画像を処理するのに、並行して 2 つのリソースをプロビジョニングするために使用したとします。請求される合計の推論時間は、6 時間 (3 時間の経過時間 x 2 個のリソース) になります。
画像をバッチで処理する場合 (1日1週間または1週間に1回、または日中の予定時刻に)、予定時刻にカスタムモデルをプロビジョニングし、すべての画像を処理してからリソースのプロビジョニングを解除する必要があります。リソースのプロビジョニングを解除しない場合、画像が処理されなくても引き続き請求されます。
Amazon Rekognition カスタムラベルの「推論時間」の金額は以下の通りです。
推論:4.00USD/時間(1推論ユニットあたり)
1 分単位での課金で最低 1 分から課金されます
推論ユニットについてはこちらを参照ください。
学習モデルを「RUNNING」の状態にすることで、分析に必要な画像処理のためにコンピューティングリソースを準備しておくので、画像分析のリクエストを受けるために常にリソースが稼働した状態で待ち受けるため、その間は実際に画像処理されなくても料金が発生します。
また、画像処理のリクエストが多い環境での利用の場合には、画像をより迅速に処理するためなど処理のスループットを上げるために並行して複数のコンピューティングリソースを実行することもでき、その場合にはモデルの開始時に「推論単位の数」で使用したい推論ユニットの数(inference units)を指定できますが、この推論ユニット数も料金に影響します。

パン屋さんでのレジの稼働を考える
トレーニングを除くランニング費用として、学習モデルを1か月間(30日)「RUNNING」の状態で稼働させておくとなると、推論ユニットが1としても 24時間 × 30日 × 4USD ×1ユニットで 2,880USD (日本円にして約40万円/月ぐらい)の料金がかかります。
しかし一般的なパン屋さんが(店にもよるのであくまで参考値で)7:00~19:00だとしたら、だいたい12時間ぐらいの営業時間の店が多いかなと予想します。
ということであれば、学習モデルは毎日営業時間だけ稼働させればおおよそ半分もコスト削減できます。
では、毎日、出勤時にAWSコンソールにログインして「開始」ボタンをポチ。あっ、昨日の退勤時に「停止」し忘れてた!!!!

・・・といったことがないように学習モデルを定時に自動で開始/停止できたら、効率的にコスト削減ができます。
学習モデルの開始/停止を自動化してみる
学習モデルの開始や停止は画像分析と同じようにRekognitonのCustom Labels APIへのリクエストでも実行できます。
このAPIへのリクエストを、Amazon EventBridge Schedulerで決めた時間に実施させることで、例えばお店の営業開始時間前に学習モデルの開始を実施し、営業終了後の時間に学習モデルを停止するようにすることで、営業時間中にのみ学習モデルを稼働させることができます。
今回、Amazon EventBridge Scheduler を使った学習モデルの開始/停止の自動化をセットアップしてみました。
図のように開始と停止のそれぞれで EventBridge Schedulerでリクエストを実行する日時を設定して、開始では「rekognition:StartProjectVersion」、停止では「rekognition:StopProjectVersion」を実行するようにセットアップします。
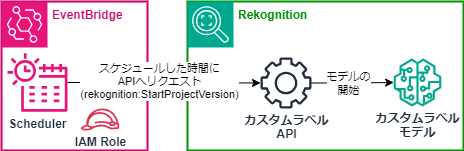
(rekognition:StartProjectVersionをリクエスト)
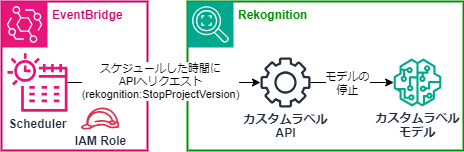
(rekognition:StopProjectVersionをリクエスト)
①IAMポリシー/ロールの用意
最初にEventBridge SchedulerでCustom Labels APIへリクエストを実行するにあたって必要なIAMポリシーとIAMロールを事前に作成しておきます。
Rekognitionカスタムラベルの指定のバージョンの学習モデルの開始(StartProjectVersion)と停止(StopProjectVersion)、ステータス確認(DescribeProjectVersions)を実行する権限を付与するためのポリシーを作成し、そのポリシーをアタッチするIAMロールを作成して、今回のAWSアカウント上でサービス「scheduler.amazonaws.com」よりロールを引き受けれるよう信頼されたエンティティとして設定します。
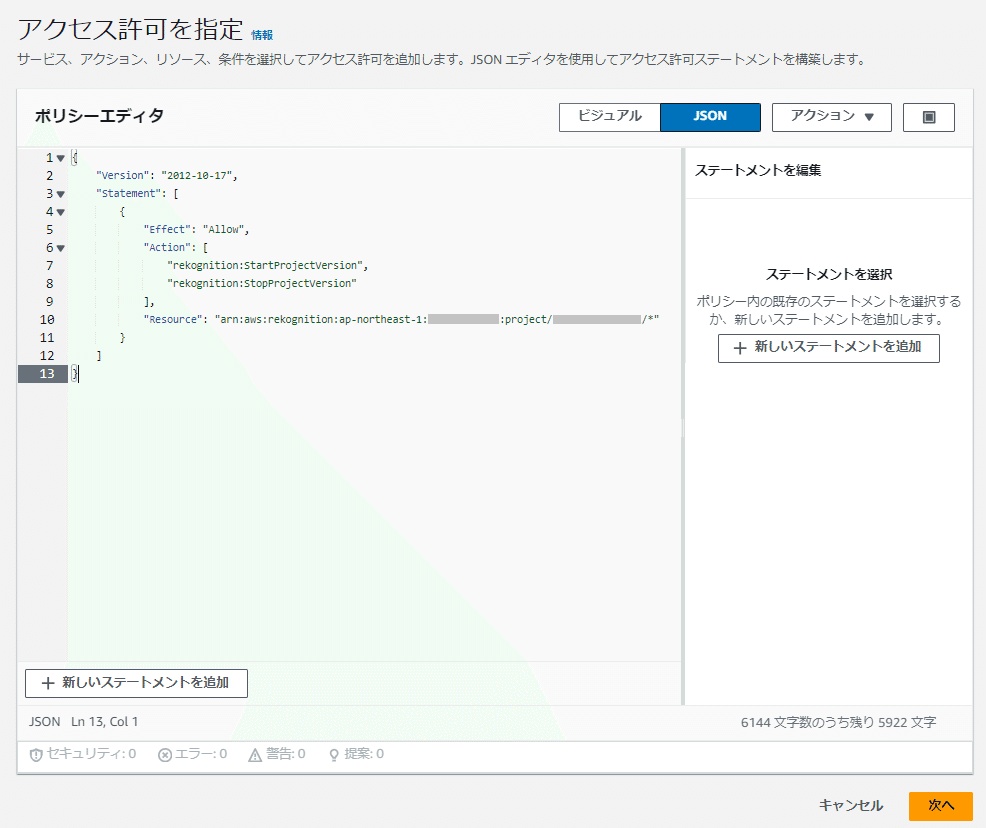
まず、IAMポリシーを作成します。以下のようなポリシーを設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"rekognition:DescribeProjectVersions",
"rekognition:StartProjectVersion",
"rekognition:StopProjectVersion"
],
"Resource": "arn:aws:rekognition:ap-northeast-1:<AWSアカウントID>:project/<プロジェクト名>/*"
}
]
}Resourceには、RekognitionカスタムラベルのプロジェクトARNを「arn:aws:rekognition:ap-northeast-1:<AWSアカウントID>:project/<プロジェクト名>/*」の形式で末尾をワイルドカード指定し、該当プロジェクトのすべての学習モデルのバージョンを対象とします
対象のバージョンの学習モデルのARNを指定してもよいのですが、運用の工程で追加トレーニングにより新しいバージョンのモデルに切り替わった都度、IAMポリシーの「Resource」のARNを修正するのは効率的ではないので、<プロジェクト名>以降はワイルドカード指定にしました
Actionには、モデルの開始(StartProjectVersion)と停止(StopProjectVersion)の実行を許可(Allow)するように指定
IAMの「ポリシー」画面で「ポリシーの作成」ボタンを押して以下の流れで作成します。
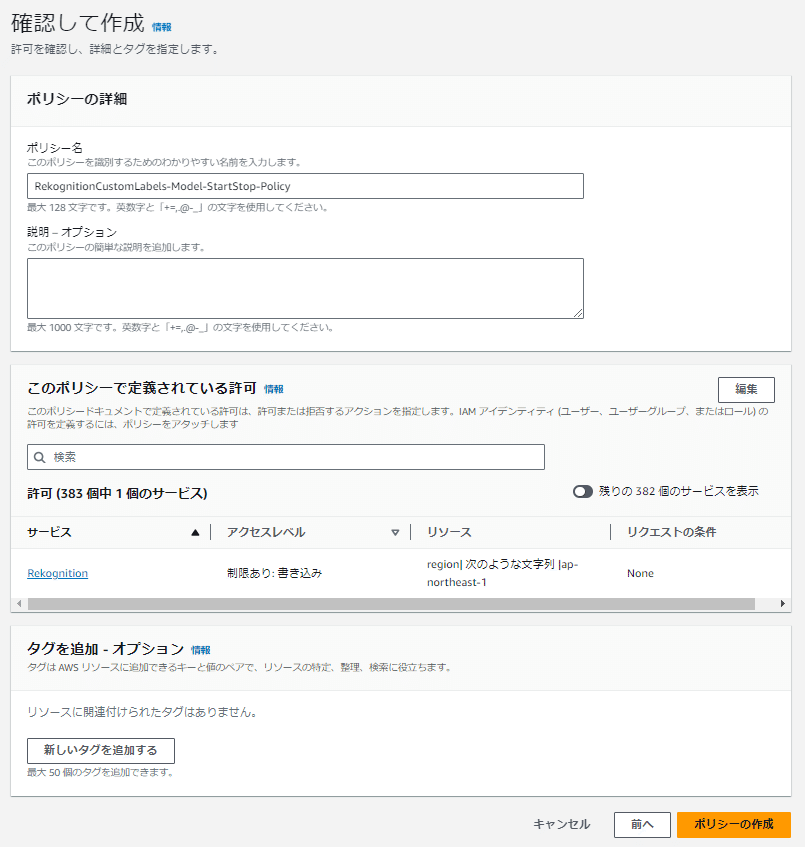
(例ではポリシー名は「RekognitionCustomLabels-Model-StartStop-Policy」で記入)
IAMポリシーの用意ができたらIAMロールを作成します。
IAMの「ロール」画面で「ロールを作成」ボタンを押して以下の流れで作成します。
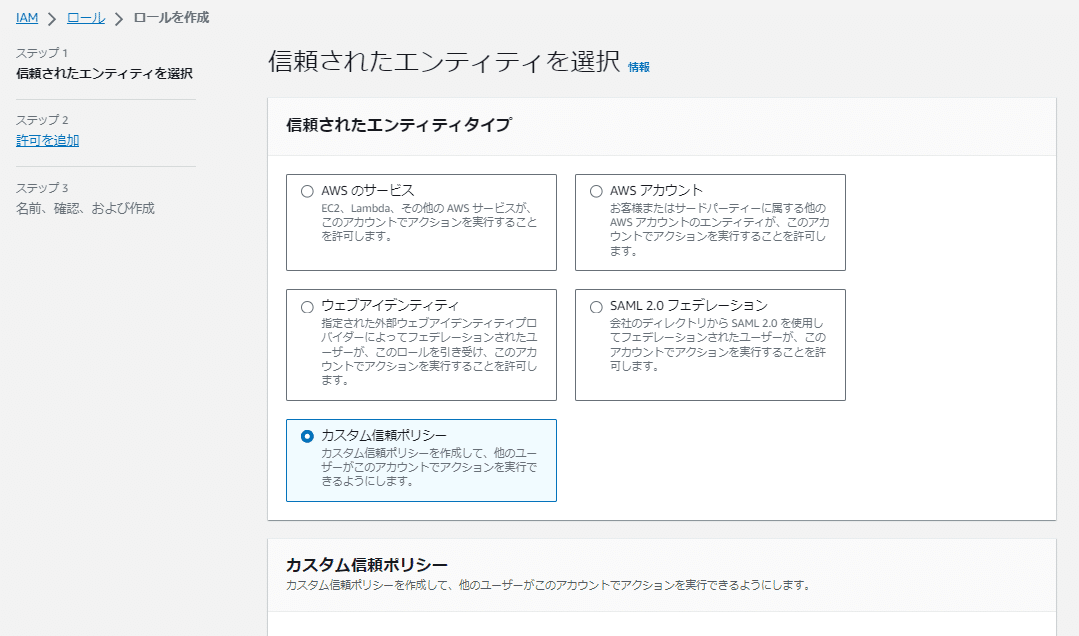
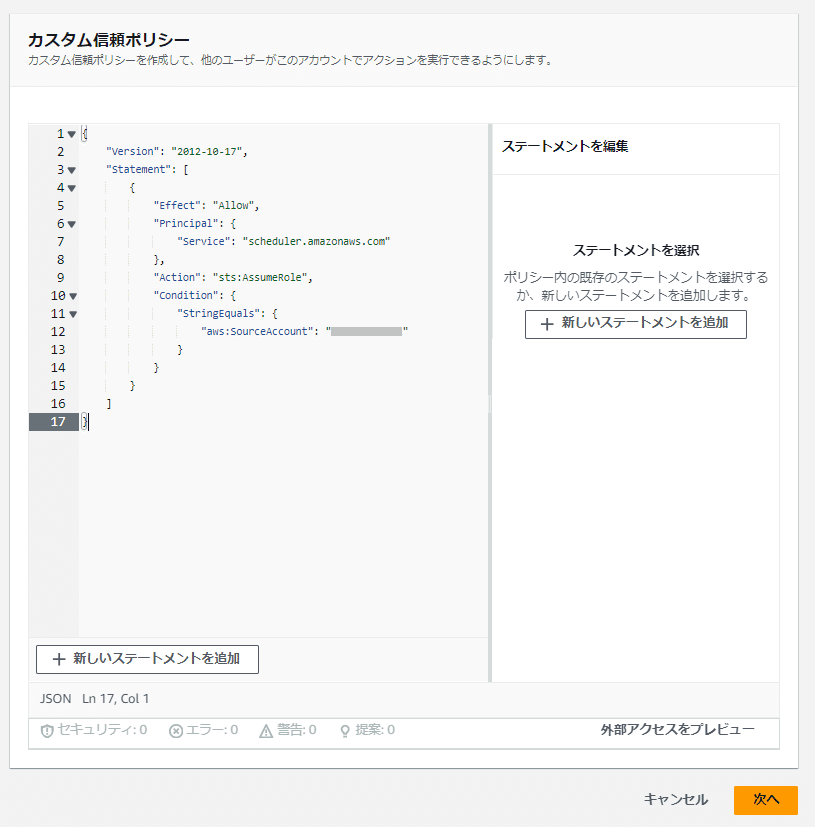
「カスタム信頼ポリシー」では以下のカスタム信頼ポリシーを記載します。
「<AWSアカウントID>」には設定対象のAWSアカウントIDが入ります。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "scheduler.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<AWSアカウントID>"
}
}
}
]
}
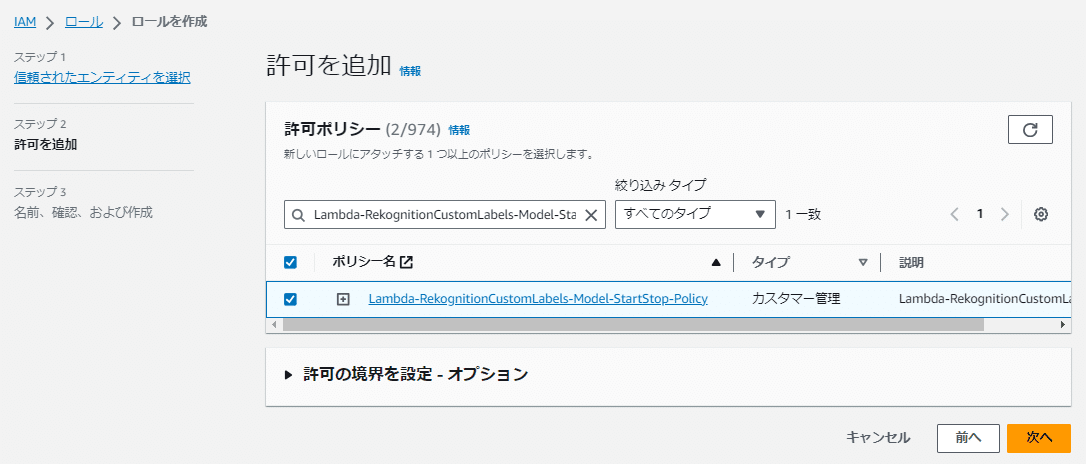
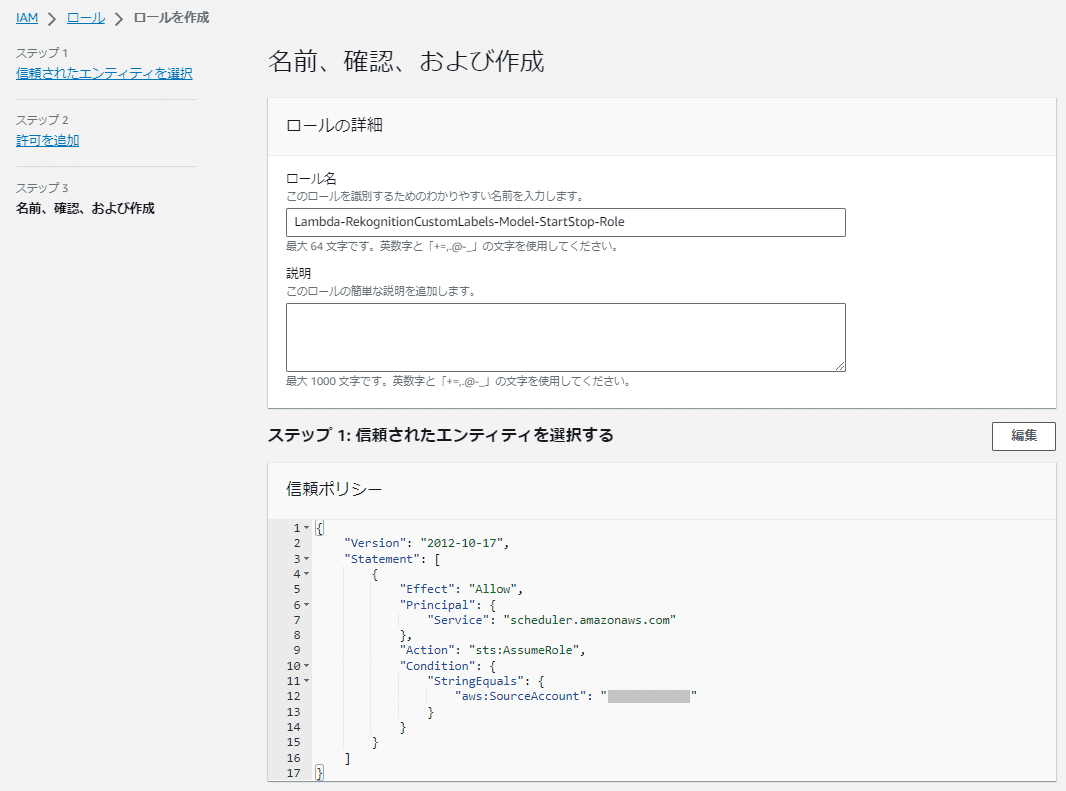
(例ではロール名は「RekognitionCustomLabels-Model-StartStop-Role」で記入)
これでEventBridge Schedulerに割り当てるIAMロールの完成です。
②EventBridge Schedulerの設定
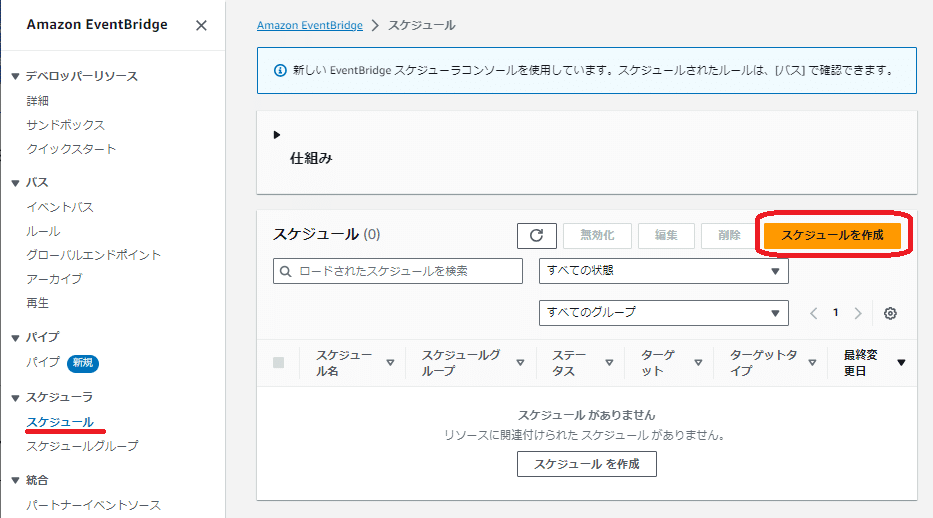
「Amazon EventBridge Scheduler」で学習モデルの「開始用」と「停止用」のそれぞれのスケジュールを作成します。
スケジュールは以下のを想定して設定します。
毎曜日営業の想定(定休日はなし)
学習モデルの開始については、開始まで最大30分かかることを想定して営業開始時刻(AM7:00)の30分前であるAM6:30開始で実施
学習モデルの停止については、店舗終了直前の駆け込み購入を想定して営業終了時刻(PM7:00)の30分後であるPM7:30停止で実施
例として以下のスケジュール名でそれぞれのスケジュールを作成します。
開始のスケジュール名:rekognition-model-start
停止のスケジュール名:rekognition-model-stop
Amazon EventBridgeのスケジューラの「スケジュール」画面から「スケジュールを作成」を押して作成します。
まずは「スケジュールの詳細の指定」を設定します。
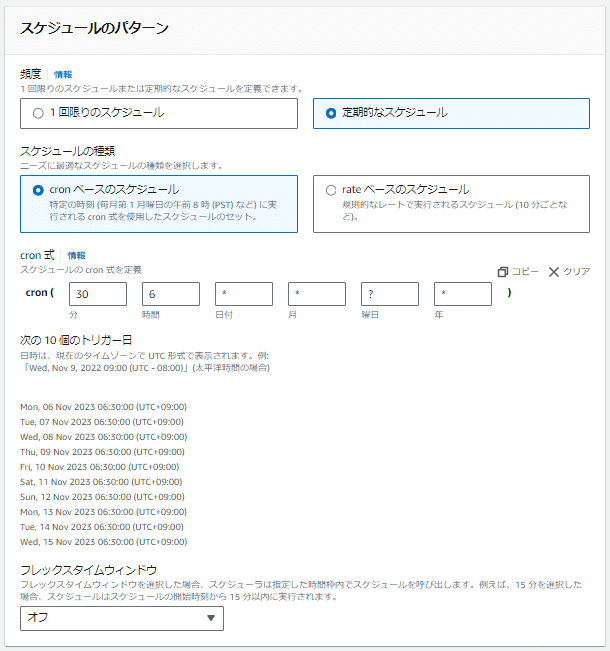
開始の場合:毎曜日に営業開始7:00の30分前で指定(30 6 * * ? *)、
停止の場合:毎曜日に営業終了19:00の30分後で指定(30 19 * * ? *)、
フレックスタイムウィンドウはオフ
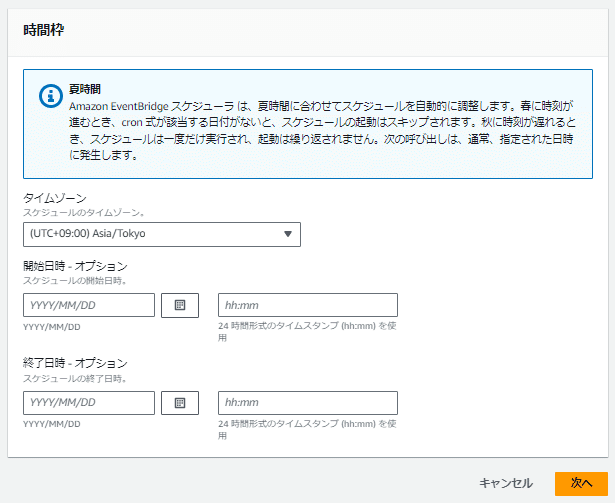
オプションの開始日時と終了日時は選択なし(記入なし)のまま
次に「ターゲットの選択」を設定します。
ターゲットAPIは「すべてのAPI」を選択し、検索欄に「Rekognition」と記入して検索すると、「Amazon Rekognition」のみ表示されるので、それをクリックします。
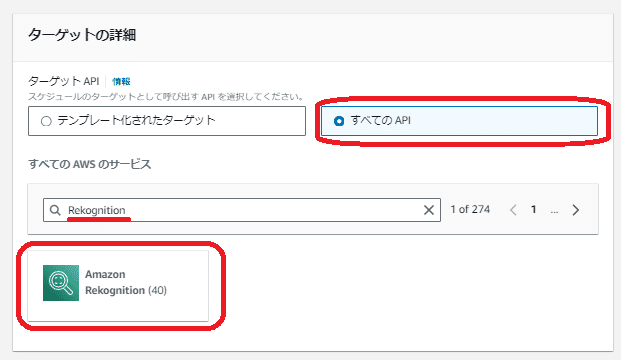
「Amazon Rekognition」をクリックすると、「Amazon Rekognition」のAPIがリストアップされるので、学習モデルの「開始」と「停止」のそれぞれのスケジューラーで以下のように設定してください。
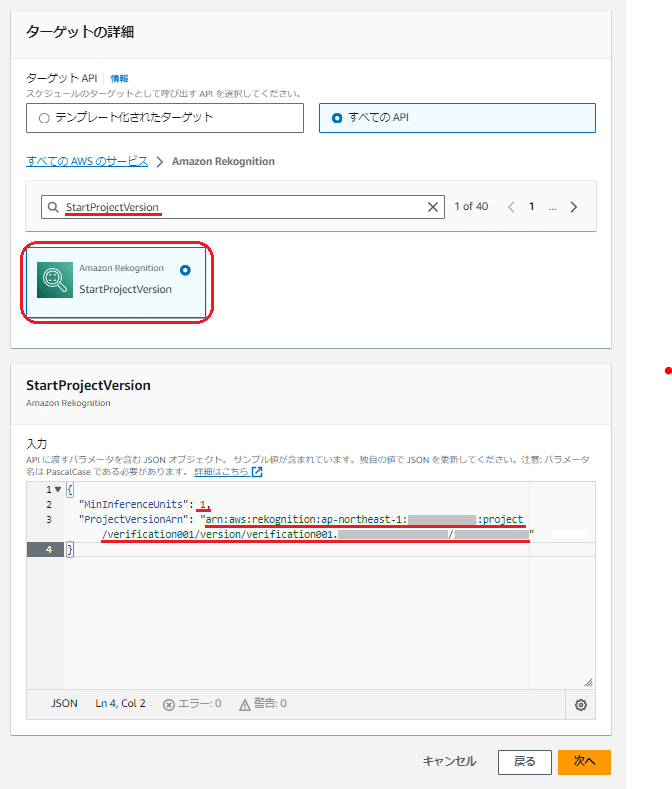
<学習モデルの「開始」の場合>
検索欄に「StartProjectVersion」を記入して検索
表示された「StartProjectVersion」をクリック
下に表示した「StartProjectVersion」の入力欄で以下のパラメータの値を設定
「MinInferenceUnits」は「1」を指定
「ProjectVersionArn」は該当のバージョンの学習モデルのARNを指定
Rekognitionカスタムラベルの該当のモデルのバージョンの「モデルを使用」タブ画面の「モデルを使用する」に表示されている「Amazon リソースネーム (ARN)」を記入してください。
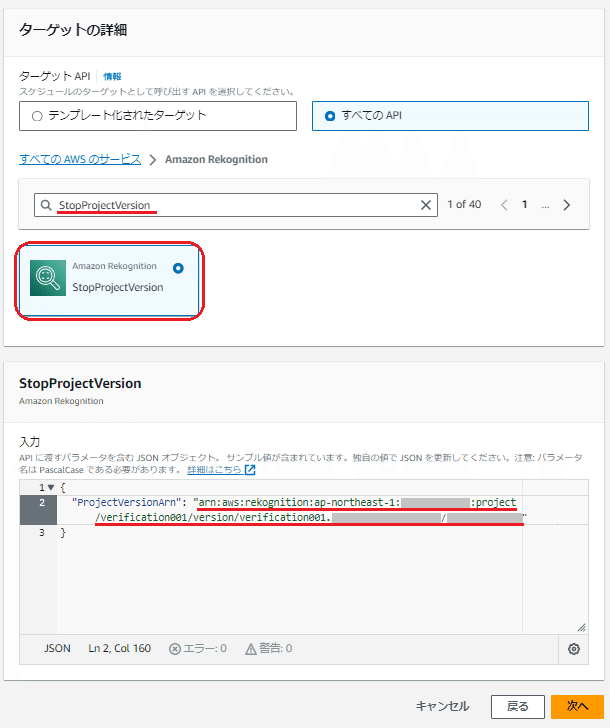
<学習モデルの「停止」の場合>
検索欄に「StopProjectVersion」を記入して検索
表示された「StopProjectVersion」をクリック
下に表示した「StopProjectVersion」の入力欄で以下のパラメータの値を設定
「ProjectVersionArn」は該当のバージョンの学習モデルのARNを指定
Rekognitionカスタムラベルの該当のモデルのバージョンの「モデルを使用」タブ画面の「モデルを使用する」に表示されている「Amazon リソースネーム (ARN)」を記入してください。
次に残りの「設定」をします。
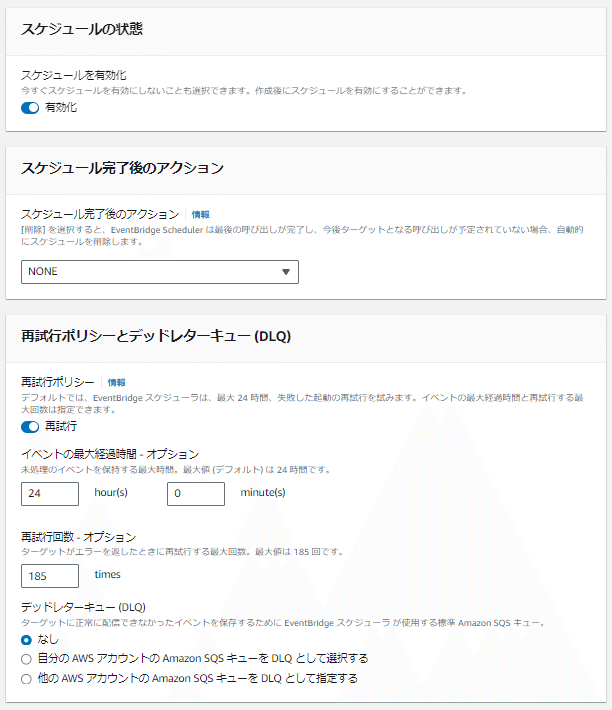
スケジュールは「有効化」のまま
スケジュール完了後のアクションは「NONE」を選択
再試行ポリシーとデッドレターキュー(DLQ)はデフォルトのまま変更なし
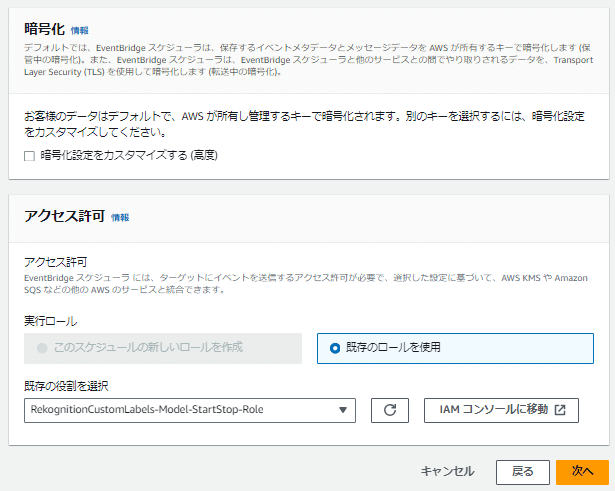
暗号化設定をカスタマイズする(高度)はチェックしない
アクセス許可では「既存のロールを使用」が選択されている状態で、既存の役割を設定から先ほど作成したIAMロールを選択
例では「RekognitionCustomLabels-Model-StartStop-Role」を選択
最後に「スケジュールの確認と保存」にて設定する内容を確認して、問題なければ「スケジュールを保存」ボタンを押して設定が完了です。
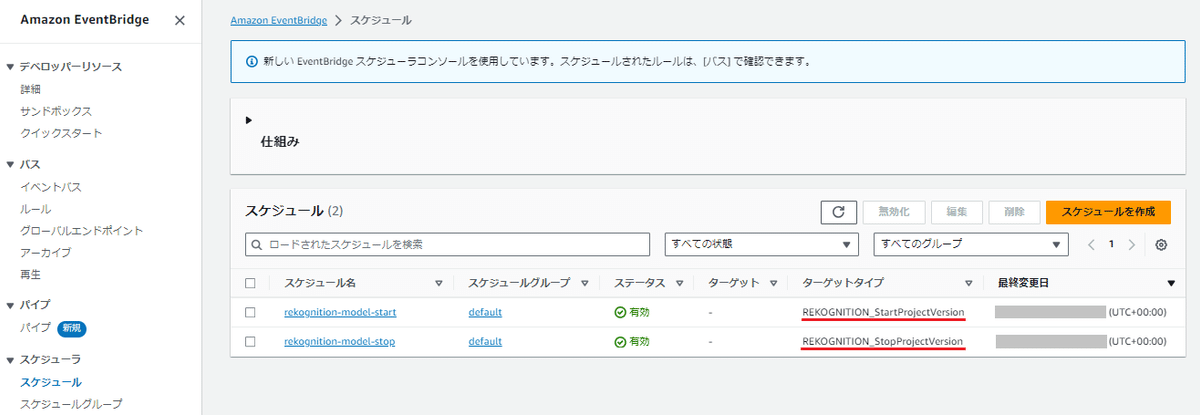
開始には「REKOGNITION_StartProjectVersion 」、
停止には「REKOGNITION_StopProjectVersion」
が設定されていることが確認できます。
③EventBridge Schedulerの実施確認
設定ができたら、スケジュールで設定した時間に学習モデルが開始または停止しているかを確認します。
学習モデルの稼働の状態は、Rekognitionカスタムラベルの該当のバージョンの学習モデルの「モデルを使用」タブ画面の「モデルの開始または停止」の箇所で確認ができます。

(開始リクエストを実行直後は「開始中」の場合もあります)
もし、開始時刻を過ぎても開始や停止をしていない場合は以下などを確認してください。
CloudWatchのメトリクスやCloudTrailのログからEventBridg Schedulerでのアクティビティを確認
EventBridge Schedulerの「ターゲットの選択」の際に指定したAPIに間違いがないか確認
「ターゲットの選択」で選択したAPIのパラメータで指定した値に誤りがないか確認
特に「ProjectVersionArn」で指定した「Amazon リソースネーム (ARN)」が間違っていないか
別のバージョンの学習モデルを開始または停止していないか確認
特に学習モデルが開始したままの状態になっていると、稼働分の料金が発生するので注意してください。
学習モデルのバージョンにおける注意点
Rekognitionカスタムラベルの運用の工程で、モデルの改善等で学習モデルを追加トレーニングした場合は、新しいバージョンの学習モデルが作成され、追加トレーニングされた内容は新しいバージョンの学習モデルに適用されます。
そのため、以下でカスタムラベルAPIへリクエストを実施する環境側では、新しいバージョンの学習モデルへリクエストを行うように「ProjectVersionArn」などのパラメータで指定している学習モデルのバージョンのAmazon リソースネーム(ARN)を新しいバージョンの学習モデルのARNに変更する必要があるのでご注意ください。
画像分析を行うリクエスト元の環境(AWS CLIやSDK)のAPIのパラメータで指定している学習モデルのARN
EventBridge Schedulerでの学習モデルの開始/停止で指定するAPIのパラメータで指定している学習モデルのARN
また、新しい学習モデルへ切り替える際には、古い学習モデルの稼働の停止を忘れないように注意してください。
■最後に
今回は実際にRekognitionカスタムラベルを使った運用を、デジタル学習教材「ライフイズテック レッスン」の中にあるパン屋さんのAIレジをイメージして考えてみました。
実際に運用目線で考えると、他にも学習モデルがちゃんと定時に開始や停止ができているかやリクエストエラーやレスポンス時間などのメトリクス監視、画像分析環境の障害時のレジ側での代替運用方法の策定、誤判定の画像の追加トレーニングの運用方法などもちゃんと考えておく必要があり、環境の構築は(ある程度)簡単にできても、実際の運用ではいろいろな工夫が必要になります。
そう、企業でのサービス提供は画期的で斬新なプロダクトを企画開発してリリースすることがゴールではなく、これらを継続的に安定運用し続けることがとても大事で、サービスにはゴールなんてものはないのかもしれません。
みなさまに「推し」ていただけるようなサービスを安心して利用いただけるように、引き続き試行錯誤しながら学習を続けていきたいと思います。

そんな「推し」ていただけるようなサービスを目指す今の会社はとてもいい会社なので、興味のある方はこちらも是非見てみてください。