非エンジニアがBigQueryの勉強をはじめた話

こんにちは。
前回のnoteを書いたのが2018/07/26で書いてる現在が2019/11/27と相当経ってしまいました。当時はFinTech関連の話とかPM関連の話を書いていこうと思っていたのに...(遠い目)
上の空白の間なんと1回転職をし、現在Kanmuという会社でバンドルカードというサービスの運営と新規事業の立ち上げをしています。
紆余曲折あり、ずっと大好きだったFinTechについに携われてとても楽しい時間を過ごしています。
今回参加するのが夢だったアドベントカレンダーを自ら発起して社内メンバーを巻き込んでみました🤗(なんと社員全員参加!!!)
前前職とかでもアドベントカレンダーはあったりしたのですがエンジニアだけのものだったので全職域のメンバーでも垣根なく関わり合える弊社だからこそできることだなと思っているので来年もできたら嬉しいな〜というお気持ちです🎅

勉強し始めた経緯
ここ近年、非エンジニアでもSQLを書くことは主流になっていっていることは肌で感じています。私もラクマ時代、都度エンジニアさん等にデータ出しをお願いすることが申し訳なく感じるようになり、社内でredashを利用していたので保存されていた他の人の書いているクエリを元に見よう見まねで勉強するところから始めて、出したいデータはざっくり抽出後、window関数とかは特に勉強せずスプレッドシートに"=IMPORTDATA"で吐き出して加工するような形でなんとかやってきました。
ところが現職には「スパルタンSQL」という毎週勉強会をする制度があり、自分のできるクエリの幅が広がっていきました。今ではまさに毛嫌いしてきたサブクエリに始まり(サブクエリ使うようなクエリはスプシでゴリっとしてきた人生)、window関数の演習問題も進めて実務に生かしています。
そのマスターした先にBigQueryはあるものだとずっと思っていたのですが、カンムのプロマネとしてKPIを達成していく上でどうしても避けられない道にBigQueryは立ちはだかっていたのです。
現在バンドルカードのアプリ上の行動データはFirebase × BigQuery × Redashで分析することができます。
どう勉強を始めたのか
以前バンドルカードのプロマネを担当していたメンバーが退職前にBigQuery勉強会を実施して触れたのが最初になります。
以下勉強会で共有された情報の引用になります。
## bigquery とは?
- Google Cloud Platform (GCP) が提供するデータストレージサービス
- われわれの使ってるPostgreSQLのようなデータベースの一種
- ちゃんと設計しなくても、とりあえず全部突っ込んどけ!が可能&高速にスキャンできる
- カラム型データストアとか、ツリーアーキテクトとかいろいろ特徴があるらしいけど今回は関係ないので割愛します!!
- GCP のBigQueryコンソールから誰でもデータを入れたり、クエリを書いて結果を見たりできる
- カンムではRedashからも使える
## バンドルでの活用
- アプリログ(アプリを開く、チャージタブをタップ…とか)をBigQueryに連携して保存している
## bigquery 基本
### 構造
https://www.apps-gcp.com/bigquery-introduction/#BigQuery-4
### 従量課金
- スキャンしたデータ量に応じて課金される:5ドル / 1TB
- 現在は1日20TB(1万円ぐらい、閾値は変更可)で制限してくれている
- ふつうに使う分には全然1万も行かないので、気軽に触って問題なし
### 特徴
- 基本的にはPostgreSQLと同じ感じで書けるが、2つ大きな特徴がある
#### データがネストされている
- ネストされている = 1つのカラム内にテーブルが入っているイメージ
- event_params カラムには key, value の2つのカラムがある
- key カラムには複数の値が入っている
- value カラムには int_value, float_value, double_value の3つのカラムがある
- それぞれのカラムには複数の値が入っている
- テーブルが日別に作られている
- event_YYYYMMDD テーブルが毎日作られている
- 1日以上の期間を指定したい場合は、必ず複数テーブルをまたぐ必要がある
(正確にいうと、ネストされた構造といったようなスキーマに関しての話はBigQueryというよりもfirebase側の都合によるもの。BigQueryでそういうことができるよ、というのは正しいけれど特に強要されるものではない)
## BigQueryでよく使う関数
- UNNEST()
- 同一レコードに入っている複数の値を1カラムずつに分割できる
-どのレコードにどんな値が入っているかはスキーマ・プレビューで確認
- UNNEST したカラムの中身は WHERE で .xx で中身に応じてフィルタできる
- _table_suffix
- 日付は _table_suffix で指定できる
こちらを元に1時間口頭での説明と演習問題を参加者で4問ほどを解いて基礎を把握しました。
実務での活用方法
まず抽出したかったこととしては弊社では重要なKPIとしてみている「ポチッとチャージ」までの遷移の中でバケツに穴が空いていないか確認するところでした。以下手順で例を記載してみたので参考になれば。。。!
(例は登録完了までを記載しています。)
1. 自分が離脱を防ぎたいと考えている遷移のスクショを取りながらスプレッドシートにステップを記載していきます。


2. BigQuery上でそれぞれのステップがどのevent_name、event_params.key、event_params.value.string_valueに含まれているか調査します。

3. ファネル分析用のクエリを書いていきます
今回活用させて頂いたのがこちらのブログです!
FirebaseAnalytics x BigQuery でSQLからクローズドファネルを作る by @osapiii
こちらで用意されているサンプルクエリを確認しながら自分のだしたデータに変更しつつ完了させていきます。
4. redashのVisualizationで見やすくする
redashは本当に便利。もともとファネル分析が簡単にわかるVisualizationが用意されています。

データは公開できませんが、、このようにVisualization機能 > Visualization Type [Funnel]で簡単にファネル分析のグラフを作ることができます。
5. データ分析完
残りは得たデータを元に画面のどこがわかりづらいのか、離脱ポイントなのかをより詳細に仮説をたて、検証を進め改善を進める流れとなります。
難しかったところ
基礎の勉強会を1度のみしたところからファネル分析をするにあたり、勘違いしていた点などがあり、変なデータが出たりすることがありました。
例えば、UNNEST関数の使い方を最初都度条件を書くごとに使わないといけないと勘違いしており不可解なコードを書いておりました。ざっくり書くとこん感じ。
SELECT
count(distinct user_id)
FROM `hogehoge.analytics_150843293.events_*` ,
unnest(event_params) as e_params,
unnest(event_params.key) as e_key,
unnest(event_params.value.string_value) as e_string_value....これでまわしたらエラーばっかりでるのでスパルタンSQLタイムで先輩に質問してUNNESTを1回書くのみでOKということがわかったり、自分である程度ググったりしてもわからなかったり腑に落ちなかった時にはすぐに質問して解決できる環境があるのは本当に最高だなと思っています。
また、BigQueryはスキャンしたデータ量に応じて課金されてしまうので気づかずにチャリンチャリン無駄遣いをして大変なことになるかも!という恐怖もありますが社内で1日で利用できるデータ量の閾値が設定されているので初心者でもゴリゴリクエリを書きつつ勉強できるのも良いと感じています。
仲間募集してます
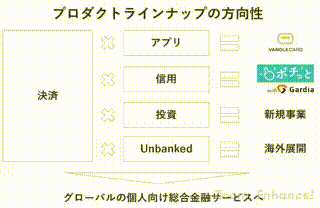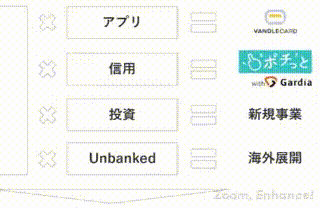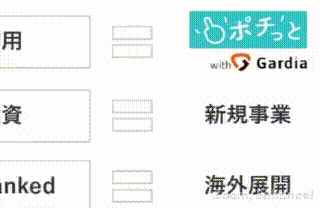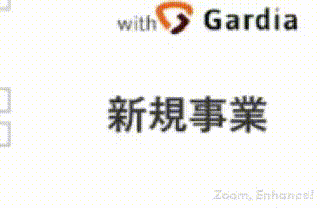
安定のオチ感がありますが、現在バンドルカードではたくさんの人たちを募集しています!!
特に新規事業では投資分野のプロダクトを考えており、法的な制約を受けつつUX設計、UI設計、ユーザーインタビュー等を黙々と進めているような状況です。
現在リードエンジニアを全力大募集中です。募集要件はこちら
この記事が参加している募集
もしよければよろしくお願いします! 最初は退職エントリですがFinTech関連の話とかPM関連の話を書いていこうと思っています👀