
「LAPRAS 公開パフォーマンスチューニング 」視聴後まとめ

正式なイベント名は『mizchiさんによる 「LAPRAS 公開パフォーマンスチューニング 」~調査編~』です。
エンジニアと人生 Advent Calendar 2024の3日目の記事として、備忘録的にまとめた内容を共有させていただきます。
mizchiさん、LAPRASの皆さん、Kawamata Ryoさん素晴らしいイベントをありがとうございました。
事前知識インプット
LAPRASさんの公式Youtubeに事前知識インプット勉強会の動画が上がっていたので視聴しました。
こちらも用語集的にまとめておきます。
Core Web Vitals
Googleがユーザーエクスペリエンスを測定・評価するために提供している重要な指標群のこと。
LCP(Largest Contentful Paint)
ページのメインコンテンツが画面に表示されるまでの時間を測定。
DevToolsのLighthouseレポート作成で何がLCPとして扱われているか確認できる。
CLS(Cumulative Layout Shift)
ページが読み込まれる際に要素が移動した量とその移動がユーザーに与える影響を組み合わせたスコア。
データ読み込みとかで遅れて描画された要素が既に描画されている要素の位置をズラしてしまうみたいなことが起きるとこのスコアに影響する。
INP
ユーザーがページとインタラクションを行った際に、次に画面が更新されるまでの時間を測定。
操作したらすぐに何らかの反応がほしいよねということ。
Lighthouseスコア
Googleが提供するオープンソースのツール「Lighthouse」を用いて、ウェブページのパフォーマンスやユーザーエクスペリエンスを測定し、改善点を提示する際に付与される評価スコアのこと。
LCPとCLS
上述のものと一緒。割愛。
FCP
最初のコンテンツが画面に描画されるまでの時間を指す。
Next.jsだとStaticレンダリングとかStreaming SSRとかで一部でもいいからとにかく早く画面を出すということをやる。
TBT
FCPとTime to Interactive(TTI)の間に発生するすべてのタスクがメインスレッドを50ms以上ブロックした時間の合計を測定。
ユーザーが入力を行ってもメインスレッドが長い時間ブロックされていると操作不能になってしまう。
Speed Index
ページが完全に表示されるまでの過程で、どれだけ速く画面が視覚的に埋められていくかを測定します。
他の指標の総計っぽい。
LighthouseのSI、たぶんWebPageTestか何か他の計測ツールからの移植で互換性のために存在しているという認識なんだけど、あれ結局他の視標の総計にしかならないからSIを考察しても得られるものがない。
— mizchi (@mizchi) November 25, 2024
他の指標の90点満点に比例する10点と思ったほうがいい。良ければ良くなる
はじめに
ブラウザにExtensionが入っていない状態で測定したい
mizchiさんのJsConfJPの発表資料
ブラウザもデスクトップアプリなので真因はCPU/Network/DiskIO
開発者のマシンは高性能
体験をそろえるためにCPU/Networkスロットリングする
先読み(preloadとか)してもリソースの上限は変わらないから安易に取り入れずに優先度を考えよう
やり過ぎるとサーバー負荷きつくなる
フロントエンドの計測は最終的なUXの計測
計測結果はサーバーの状態に依存する
同じページをロードし続けたらキャッシュされて再現しなくなる
ピークタイムタイムによって違う結果になる
調査開始
Devtoolsの各タブを見ながらボトルネックを探していく。
以降のスクショはこのnoteの記事ページを測定したものです。
Lighthouseタブ
以下の設定で回す
Mode: Navigation
Device: Mobile
Category: Performance
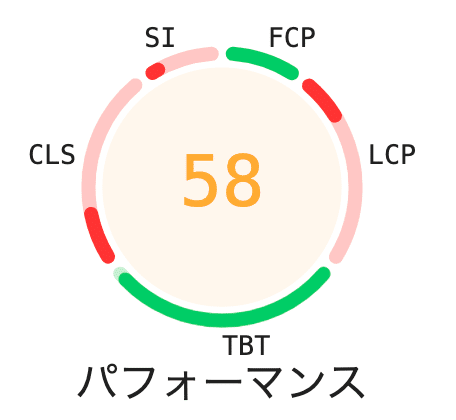
各指標には相関関係がある
ex. TBTが悪いとCLSも悪い傾向
診断(DIAGNOSTICS)は結構ファジーな内容が出力される
大まかに把握する
LCPが何かは見ておいた方がいい
Performanceタブ
ここを詳しく見ていく。
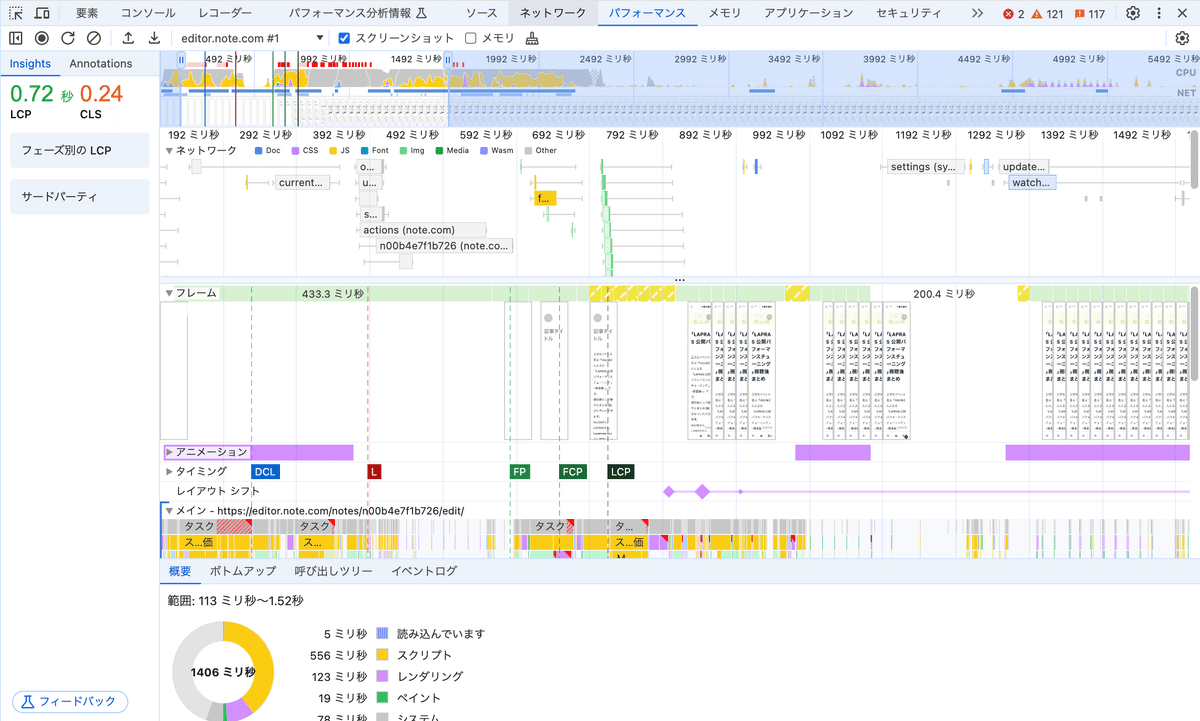
項目がいろいろある。
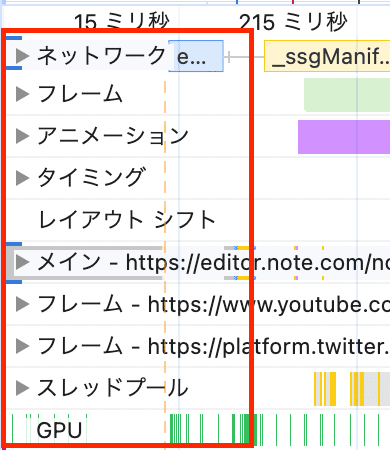
アニメーション
実行時間を確認しつつボトルネックを見極める。
得られるユーザー体験とパフォーマンスのトレードオフを考慮して改善すべきかの判断を行う。

ネットワーク
ページのネットワークリクエストに関する情報をタイムライン形式で提供する。
縦軸が個々のリソースのリクエスト。横軸が経過時間。

レイアウトシフト
ホバーするとどこでレイアウトシフトが起きているかアニメーションで可視化してくれる。

メイン
メインスレッド。
クリティカルパスを最適化するための情報を確認する。
クリティカルパス(Critical Rendering Path)
クリティカル レンダリング パスとは、ウェブページがブラウザでのレンダリングを開始するまでのステップを指します。ブラウザでページをレンダリングするには、HTML ドキュメント自体と、そのドキュメントのレンダリングに必要なすべての重要なリソースが必要です。
個々のタスクをクリックしてボトムアップタブを見ると、パフォーマンスデータを関数やタスクごとに集計し、合計時間の多い順にリスト化して表示してくれる
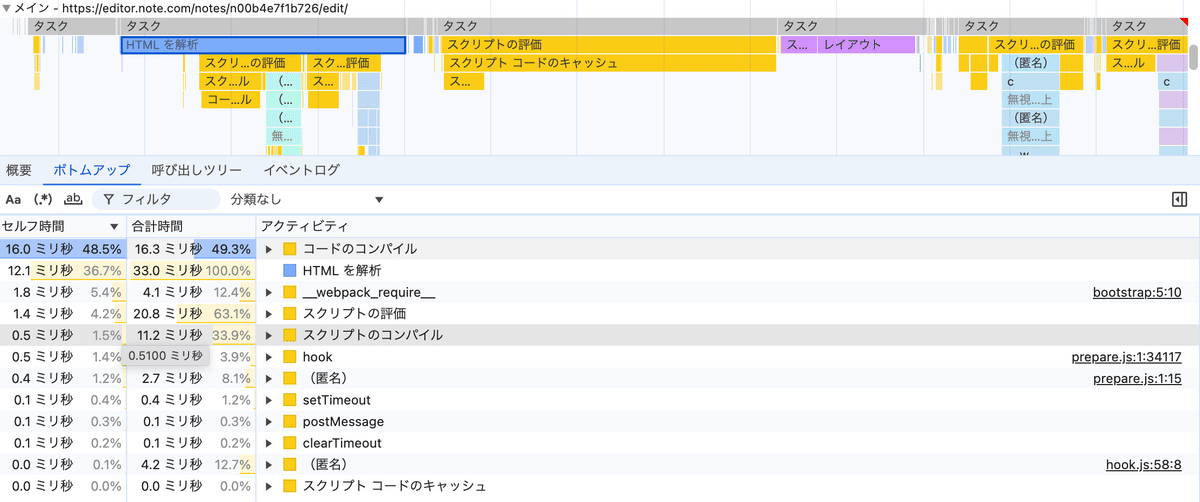
Networkタブ
サイズで転送量、時間でリクエストタイムを確認する。
最下段に総計が表示されている。
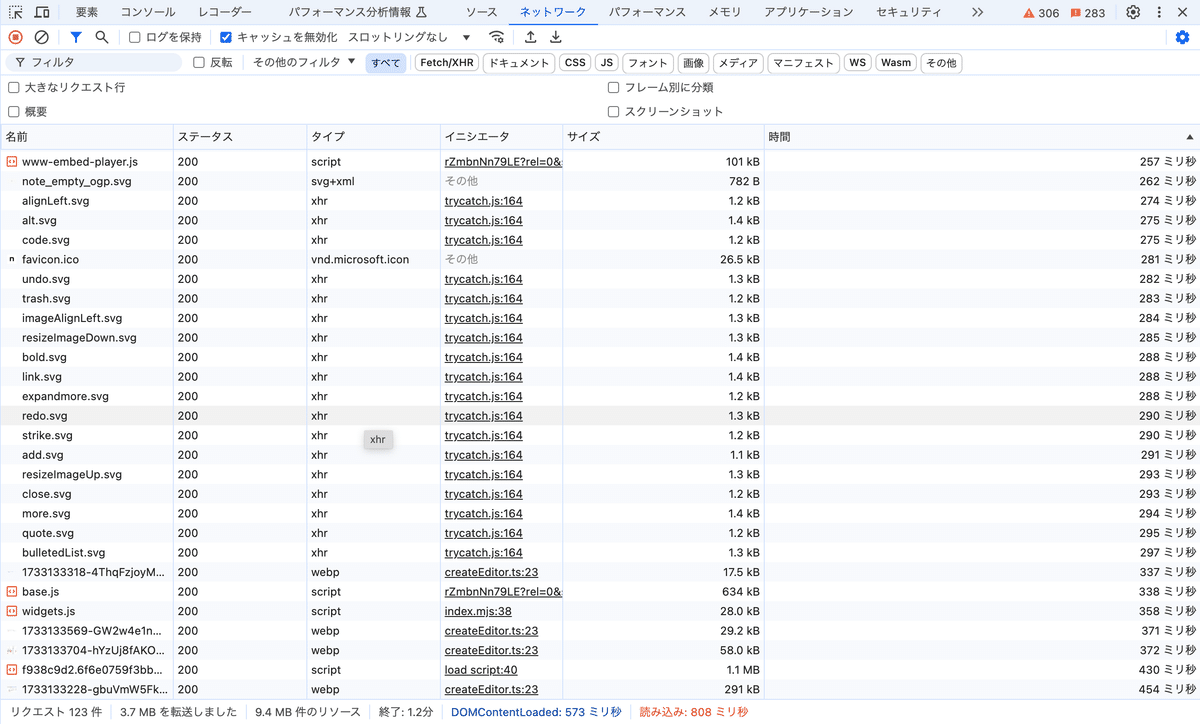
例えばYoutubeの埋め込みデータに関するリクエストをブロッキングしてみる(個々のリクエスト右クリック、"ブロック リクエストのURL"選択)。
Before
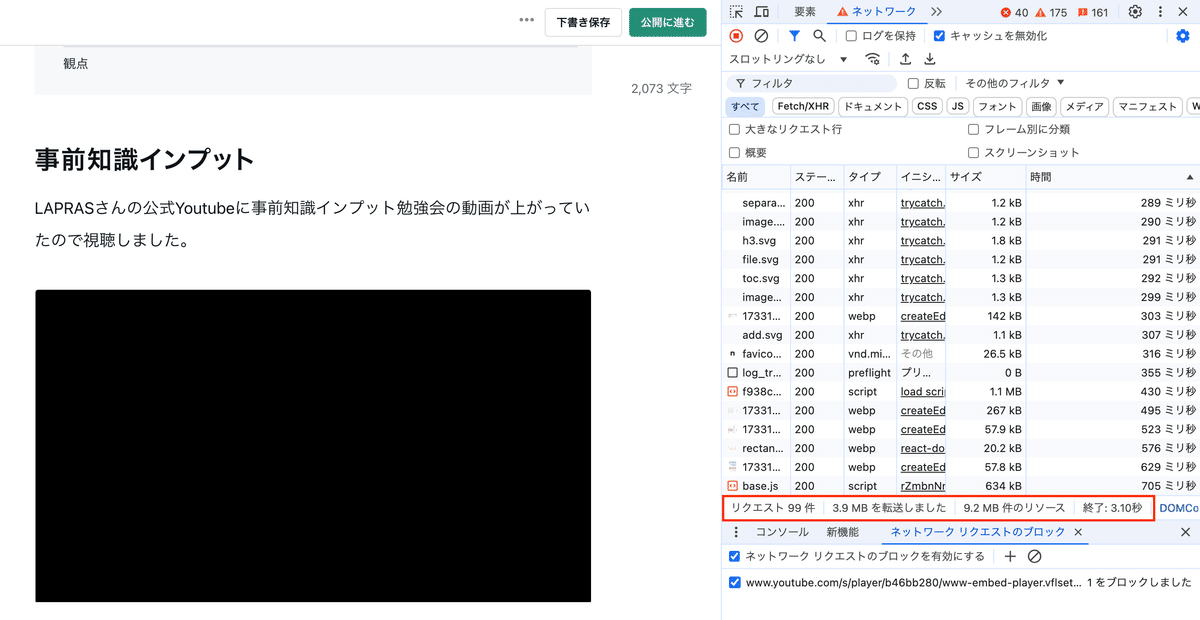
After
リクエスト数、転送量、リソース量が減少する。減り方でパフォーマンスに与えるインパクトを見極める。
観点
まずはネットワークで重そうなものを見繕う
gtmとかweb fontsとかRUMとか
それらのリクエストをブロッキングして計測し直してみる
ブロッキングしている処理がそのタイミングで実行されるべきか考える
先に読み込むべきリソースが無いか(後続の処理が依存しているようなものとか)
画面の下の方に表示されるデータは後の方で取ってもいい
全部のデータ取得を待ってレンダリングするとCLSのスコアは良くなるが早く見せれるはずのUIまで後でまとめて出すことになる
部分的なサーバーサイドレンダリングとか使ってみると良さそう
ライブラリ、フレームワークで出来ることは決まる
Performanceタブ上部の黄色とかグレーとか緑の帯を見てCPU負荷の高い処理を見てみる
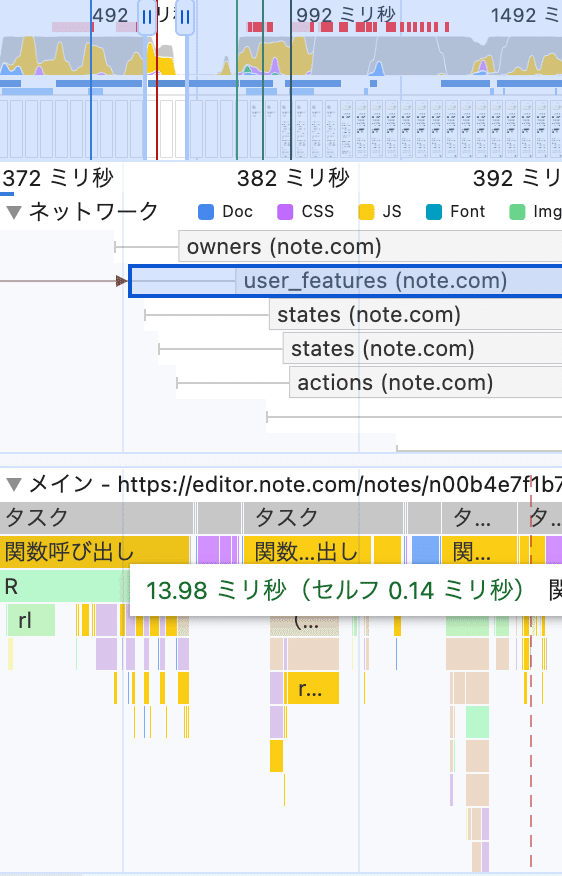
データ取得処理の対象と流れが見えるので重複したリクエストをしていないか、タイミングがそこであってるかみたいな確認ができる
計測→大きな問題をいくつか特定する→簡単に直せそうなものから直す
bundle analyzer
各チャンクのサイズが視覚的にわかる(DevToolsの機能ではないです。webpack-bundle-analyzer)

重複したパッケージ利用とか意外とある(本体にあるのに個別に取ってるとか。ex. lodash.orderbyはlodashにある)
yarn whyとかで特定の依存関係がどのようにインストールされたのか、どのパッケージがそれを要求しているのかを確認する
標準APIで実装できるものはなるべくライブラリに頼らない
監視ツールとかは巨大なので軽量サーバー(Cloudflare Workersとか)でデータを受けて動かすことでバンドルサイズを減らすみたいなこともできる
Markdown Compilerとかも大きいのでWeb Workerで動かすといい
チャンクを削ればTBTのスコア改善につながる
改善ポイントとスコアの関連性
LCP: JSロジック
FCP: サーバーレスポンス
TBT: package.jsonのメンテ。Web Worker使い所で使えてるか
まとめ
Dev ToolsのPerformance, Lighthouse, Networkといったタブを活用してソースコードを読まずにパフォーマンス上のボトルネックを探すという手法を実際に画面を見ながら学べるというのはかなり貴重な経験でした。
mizchiさん自身我流でやっているとのことだったので普通は誰かに教えてもらえる機会を持てることはなかなか無いと思います。
私自身Streaming SSRによるFCPの改善やスケルトンによるCLSの改善といった画面で見て効果が分かりやすい項目については取り組んでいるつもりでしたが、実際に計測したことはほとんどなく、知らない/よく分かっていない指標もありました。
自社サービスのパフォーマンスを公開で調査するという稀有な場を設けていただいたLAPRASさん、仕事に直結するノウハウを惜しげもなく披露していただいたmizchさんに感謝いたします。
集中力が切れて聞き流してしまった所が多々あるので、気になった方は是非動画本編をご視聴ください。