
[機械学習]-東京 梅毒の流行状況を解析する

梅毒は、梅毒は性感染症の一つであり、Treponema pallidumという菌によって引き起こされます。主に性的接触を介して感染が広がりますが、妊娠中に胎児に感染することもあります。
梅毒の感染は主に性的接触によって広がるため、性行為による感染リスクが一般的な要因です。
東京は日本の人口密度の高い地域であり、都市の大きさと人口の多さから、性感染症の感染が広がるリスクが高まる可能性があります。都市部では、人々が多くの人と接触する機会が増え、性的なパートナーとの交流や性的な活動の頻度が高くなることが指摘されています。
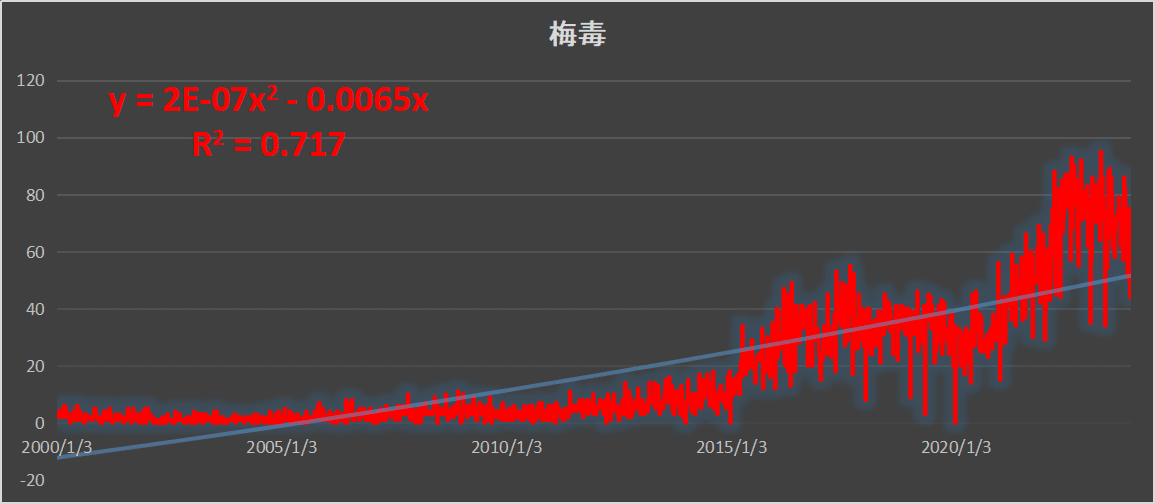
一般的には特別な特徴を持っていません、とされてますが、少なくとも東京では、明確にトレンド(trend)として、倍々ゲームで(ネズミ算で)増加傾向がある、といえることがわかりました。
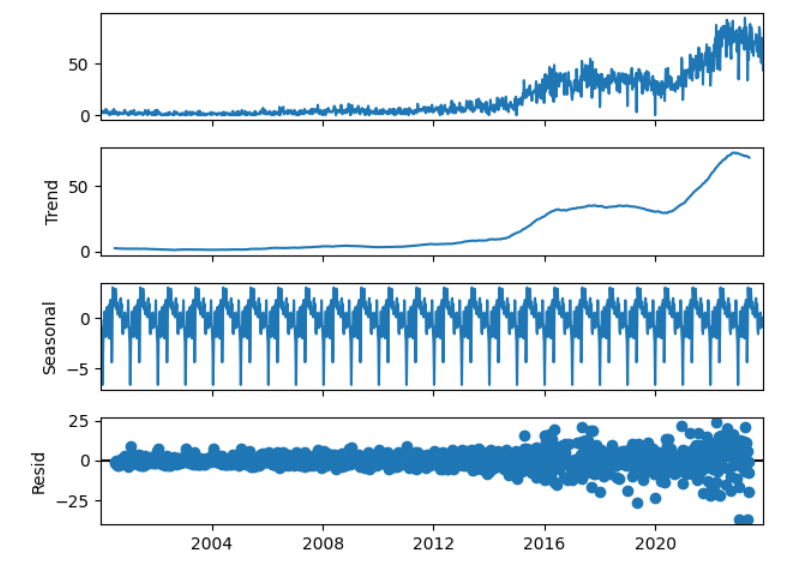
また、気になる点として、何らかの形による別の増加要因が明確にある、ということです。
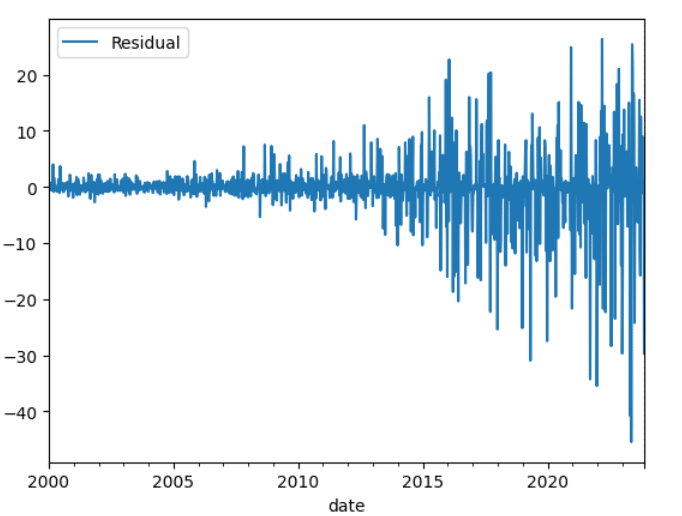
【STL分解の残差とは】
季節性とトレンドが除去された部分のことです。
STL分解では、元の時系列データから季節性とトレンド成分が分離されます。そのため、残差は季節性とトレンドが取り除かれた部分であり、これらの要素による影響を受けない変動成分を表しています。
STL分解の残差は、以下のような特徴を持つことが一般的です。
1.ランダムな変動やノイズ:
残差は、季節性やトレンドによって説明されず、予測が難しいランダムな変動やノイズの成分を含んでいます。これは、時系列データに含まれる他の要素や影響を表している可能性があります。
2.平均値がゼロであること:
残差は、季節性とトレンド成分が除去されたため、平均値がゼロになる傾向があります。
ただし、個別の時系列データによっては、完全にゼロではない場合もあります。
3.定常性を持つ場合がある:
STL分解の残差は、季節性やトレンドが除去された部分であるため、
定常性(時系列の統計的特性が時間に依存しないこと)を持つ場合があります。
ただし、特定の時系列データにおいては定常性がない場合もあります。
定点医療機関当たり患者報告数
このPythonプログラムは、感染症の流行状況を分析するためのツールです。分析は「STL分解」、季節およびトレンドの分解 (STL) は、多くの場合、経済および環境の解析に使用されるの確実な時系列分解の方法です。
これを感染症の流行状況分析に流用します。
このSTL 法は、回帰モデルを使用して時系列をトレンド、季節、および余剰の各コンポーネントに分解します。
(1)はじめに
機械学習と数理最適化 Advent Calendar 2023 チャレンジ の文書です。
の下図のとおり、機械学習の分、解析です。

STL(Seasonal-Trend decomposition using LOESS)解析は、時系列データを季節性、トレンド、残差の3つの成分に分解する手法です。この手法は、局所的に滑らかな変動を考慮することができ、季節性やトレンドの非線形性に対処するのに有用です。STL はどのデータセットでも適用可能ですが、繰り返しの時系列パターンがデータに存在する場合にのみ意味のある結果が返されます (たとえば、暖かい月の間に低下する大気環境など)。
(2)想定している一般的な活用シーン
健康教育と啓発活動: 予測データを活用して、感染事例を予測することで、一般の人々に対して関心を喚起するための健康教育や啓発活動を行うことができます。例えば、予測データをもとにした情報キャンペーンやメディアの特集などを通じて、予防接種の重要性や感染予防の方法について広く知識を提供することができます。
旅行者の健康管理: 予測データを活用して、流行地域や感染リスクの高い地域への旅行や移住者に対して、感染予防のための適切なアドバイスや予防接種の提供をすることができます。これにより、感染の持ち込みや広がりを防止することができます。
(2)当コードについて
このPythonプログラムは、時系列データに対する分析と可視化を行うものです
(3)コードの概要
時系列データ(特に期間ごとのデータ)の長期的な傾向、周期的な変動、季節性、および残差を分析するためのコードです。
以下に、コードの概要と詳細な説明を示します。
概要:
環境設定:必要なライブラリ(pandas、matplotlib、statsmodels)をインポートしています。
データ設定:Webサイトから時系列データを読み込んでいます。データの可視化を行い、時系列データの全体的な傾向を把握します。
一般解析:自己相関を確認するために、自己相関関数(ACF)をプロットしています。季節性の検定を行い、元データから長期トレンド、周期変動、残差を分解しています。
STL解析:Seasonal and Trend decomposition using Loess(STL)分解を実施しています。※この手法は外れ値に頑健であり、より正確に季節成分とトレンドを分離できます。STL分解の結果をグラフ化し、オリジナルデータ、トレンド、季節性、残差をそれぞれ表示しています。
(4)コード詳細説明
データ読み込みと可視化:
pd.read_csvを使用してCSVファイルを読み込み、日付を解釈し、日付をインデックスとして設定しています。
データを可視化するためにMatplotlibを使用し、日付ごとのデータの変化をプロットしています。
一般解析:
sm.graphics.tsa.plot_acfを使用して、データの自己相関をラグごとに可視化しています。
sm.tsa.seasonal_decomposeを使用して、データをトレンド、周期変動、残差に分解し、それぞれの成分をプロットしています。
STL解析:
sm.tsa.STLを使用してSTL分解を実行し、外れ値に対して頑健な結果を得ています。
STL分解の結果をグラフにプロットし、オリジナルデータ、トレンド、季節性、残差を一度に確認できるようにしています。
これにより、時系列データの長期的な傾向や季節的な変動、外れ値に対する頑健な分析が行われています。
Google Colaboratory(通称Colab)は、Googleが提供するクラウドベースのJupyterノートブック環境で動作するようにしてあります。
元データを設定して、自社環境に合う形で使ってください。
内容表示まで
# **********************
# [0] 環境設定 *********
# **********************
# 必要なライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
# **********************
# [1] データ設定 *******
# **********************
#個人のGITHUB環境です
# データの読み込みと可視化
data = pd.read_csv('https://miraimeisatu.github.io/covid19_2021/Tokyo-baidoku.csv', parse_dates=['date'], index_col='date')
#データ表示
plt.figure(figsize=(10, 6))
plt.plot(data)
plt.xlabel('Date')
plt.ylabel('Y')
plt.title('Seasonal Variation')
plt.show()
#実際の処理はここから
# **********************
# [2] 一般解析 *********
# **********************
# 自己相関の確認
acf = sm.graphics.tsa.plot_acf(data, lags=52)
plt.xlabel('Rug')
plt.ylabel('Autocorrelation')
plt.title('Auto-Fun')
plt.show()
# 季節性の検定
res = sm.tsa.seasonal_decompose(data, model='additive')
res.plot()
plt.show()
# **********************
# [3] STL解析 **********
# **********************
# STL分解
stl_output = sm.tsa.STL(data['Y'], period=7, robust=True).fit()
# 4つのグラフを重ねてSTL分解の結果を表示
data['Y'].plot(label='Original')
stl_output.trend.plot(label='trend')
stl_output.seasonal.plot(label='Season-Variation')
stl_output.resid.plot(label='Residual')
plt.legend()
plt.show()
# **********************
# [3] 結果T解析 *********
# **********************
# 残差だけ表示
stl_output.resid.plot(label='Residual')
plt.legend()
plt.show()Colabについてわかりやすく説明します。
無料で利用可能: Colabは無料で利用できます。Googleアカウントを持っていれば、ブラウザ上で簡単に利用できます。GPUやTPUも利用でき、機械学習やディープラーニングのトレーニングなどに便利です。
Jupyterノートブック形式: ColabはJupyterノートブック形式を採用しています。コードセルとテキストセルを組み合わせ、コードの実行と説明文を同じ場所で管理できます。
クラウドベース: Colabはクラウド上で動作するため、自分のマシンに環境を構築する必要がありません。また、Google Driveとの連携も容易で、ノートブックを保存し、共有することができます。
豊富なライブラリとハードウェアアクセラレーション: Colabには多くの機械学習やデータサイエンスに使用されるライブラリが事前にインストールされています。また、GPUやTPUなどのハードウェアアクセラレーションも利用可能で、大規模な計算を高速に行うことができます。
共有と協力: ノートブックはGoogle Driveに保存され、他のユーザーと共有しやすいです。また、リアルタイムで共同作業も可能です。
データの可視化と解析: Colabにはデータの可視化や解析に役立つツールが豊富に組み込まれています。例えば、MatplotlibやSeabornなどのライブラリを使ってグラフを描画することができます。
Colabは教育、研究、プロトタイピング、データ解析、機械学習のトレーニングなど、さまざまな目的に利用されています。無料で使えるため、手軽に始めることができ、Googleのクラウドリソースを利用できる点が魅力です。
追記:
機械学習と数理最適化について
機械学習と数理最適化 Advent Calendar 2023 チャレンジ している理由
#機械学習 ,#ChatGPT,#量子コンピューター,#AI,
#クリスマス ,#AIとやってみた,#アドベントカレンダー,#量子コンピューター,#数理最適化,#量子アニーリング
いいなと思ったら応援しよう!
