データ周り(ETL, dbt, Snowflake, モデリング)調べた際のメモ

はじめに
①:👇️の記事を見つけてなんとなく読み出し、
②:👇️のdbtの話題に遷移し、
③:dbt及びデータモデリングの👇️の記事にたどり着いた
③:モダンデータスタック
Data Vault
DWHの歴史周りの話や、最新動向などの話がされているが、その中に「Data Vault」の話があった。
リレーショナルモデルやディメンショナルモデルを古典的とするなら、今どきの方法論の一つとして「Data Vault」という方法論、アーキテクチャ、ベストプラクティスがあるらしい。
詳細指向、正規系テーブルの履歴追跡と一意なリンクセットでビジネス領域を機能的にサポートするらしい。
モデルは下記で構成されるらしい。
Hub:ビジネスキーを持つ
Link:Hub同士をつなげる
Satellite(Sat):Hubにくっつき、データの詳細を持つ
Sat
Satは通常のディメンションと異なり時系列(履歴)を持っている
Hub:Sat=1 : 多 の関係で、Hubキー+日時でSatは位置位になる
HASH値(レコードデータの同一性比較用)や源泉システム情報をメタ情報的に管理する
Hub
独自のHubキーを持ち、このキーでSatとは結合
そのレコードの生成・ロード日時、源泉システム情報をメタ情報的に管理する
Link
Hub同士のコネクター
独自のLinkキーを持つ(他テーブルとの結合キーと言うよりは一意性情報)
Hub : Link : Hub = 1 : 多 : 1 の関係になる
イメージ
リレーショナルモデルからData Vaultへ変換


Data Vaultのいいところ


機械的な変換ができ、過去のデータに対する上書きがないのが良いところ、らしい。
Data Vault の良くないところ

だと思った。
管理対象オブジェクトも増えるし、オブジェクトが増えることの手間もあるだろうし、アドホックな分析に向かないし、めんどくさそうな印象が正直ある。
→分析時の手間については、Viewなどを作って対処すべき、とのこと。
一旦そのまま取り込んだ一次データ(Stagingデータ)と、Data Vault化する層?(Raw Vault)でデータ量が2倍に膨らむのも確かに。
実際、ディメンションやファクトを時系列で管理して「とある時点で切り出して」分析するようなことはある。
経験上、そういうときはその時点データを切り抜いて加工・集計して分析用データを作るプロセスを設けていた。
データ量が膨大で、Viewだなんだでは性能面で非現実的だったので。
つまり何かしらの形で時系列データでの管理は必要、というのはある。
Data Vaultがハマるのか、別の方法論がいいのかは、ケースバイケースで検討が必要。
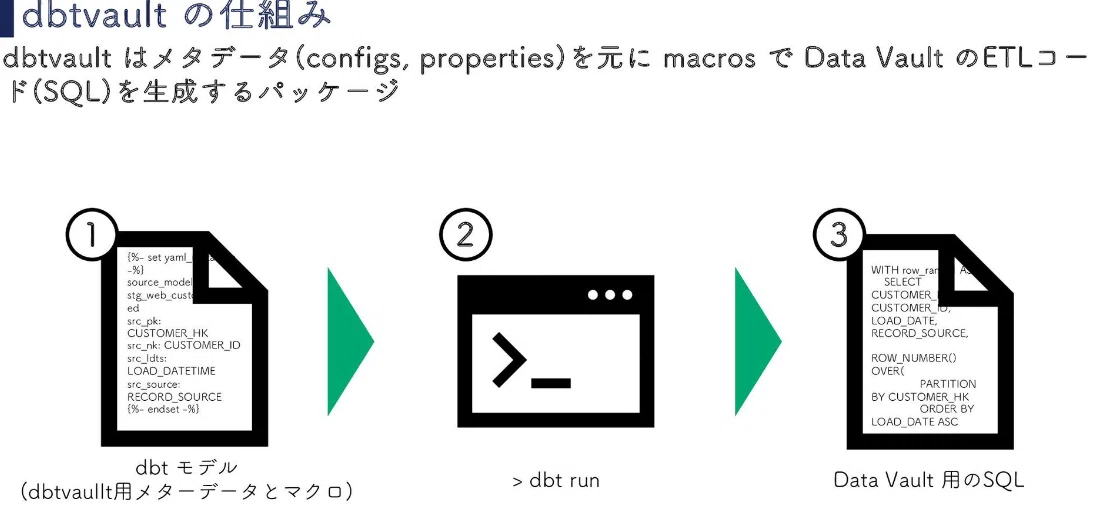
Data Vault * dbt=dbtvault
dbtvaultの狙い
標準化された変換を多用するData Vault 2.0 の実装において、SQLを手書きする必要性を減らす
Data Vault 2.0
スケーラブルEDW(Enterprise Data Warehouse)に使えるアジャイル手法

仕組み
プロコン

最新情報
今はdbtのパッケージの一つとして automate_dvtという名前になっている?
②:Snowflake × dbt で構築する ELT アーキテクチャ
ETL処理を、AWS StepFunctions、Glue、Lambda、dbtを用いて実装する事例。
Snowflake側でファイル監視・取り込み・二次加工を一貫して行う事もできる(taskやsnowpipe, ストアドを利用すればできる)が、他のサービスを組み合わせるほうが複雑なことが容易・効率的にやれるということだろうか。
保守性や開発効率は確かに良くなる場合がある気もするし、一方でいろんなサービスを組み合わせたりつなぎ込んだりする面倒くささも感じる…

そして、そろそろマジでdbtはちゃんと入門しないといけなさそう。
かなりデータ界隈ではデファクトスタンダード化しているようで(そんな気配は感じつつ見ないふりをしていた)、置いてきぼりを食らっている感じがある。