
こどもGPTのリリース〜アレクサ(Alexa)で子供がChatGPTを使えるようにする

1. はじめに
現在、こどもGPTというalexaスキルの公開を申請中です。
承認が降りれば、子供がアレクサを呼び出してchatGPTと会話できるようになります。
個人的には、需要あるかと思い、ポケットマネーで実現しようとしています。
なお、開発方式の記事についても、いったん公開させていただきます。
まだスクショ添付など、少しずつ加筆修正して、読みやすくしていきます。
具体的には、Alexaスキルの開発について、高校生でも理解できるような初心者向けに解説します。
大人だけでなく子供でも簡単にChatGPTを利用できるようなAlexaスキル(今回リリースしたこどもGPTの中身)の作成方法を紹介します。
開発の背景としては、AlexaスキルやAWSの設定は通常、個々のユーザーが自身で行います。しかし、プログラミングやシステム開発の経験がない多くの人にとって、これは高いハードルとなります。そのため、私がこのスキルを公開することで、多くの人が容易に利用できるようにしました。また、ネット上には同様のスキルがほとんど公開されておらず、公開されているものでも技術的な素養が必要だったり、実際には動作しないものが多かったことから、このスキルを作成し、公開することにしました。
一方で、公開したAlexaスキルを利用するのではなく、自分でイチから、自分の子供のためにカスタマイズされたスキルを作成する方法を学びたいという方のために、この記事やYouTubeを通じて設定方法の解説を試みています。
2. Alexa側の設定
2.1 Alexa Developer Consoleのアカウント作成
まず、Alexaスキルを作成するためには、Alexa Developer Consoleのアカウントが必要です。詳細な手順は他の多くの記事で既に書かれていますので、ここでは省略します。詳細が必要な場合は、それらの記事を参照してください。
2.2 スキルの作成
次に、Alexaスキルを作成します。ここでは、スキルの基本情報、インテント、スロット、エンドポイントの設定方法を説明します。具体的には、インテント名として「ChatGPTIntent」を作成し、サンプル発話として「{question}」を、このスロットタイプとして「AMAZON.Language」を設定します。そして、エンドポイントの設定で、「デフォルトの地域(必須)」には作成したLambda関数のARNを設定し、その他の地域設定がある場合は削除します。
(ここにスキル作成の手順とスクリーンショットを挿入予定)
3. AWS側の設定
3.1 AWS マネジメントConsoleのアカウント作成
次に、AWS マネジメントConsoleのアカウントを作成します。ここでは、Lambda関数を作成し、ChatGPTと連携するための設定を行います。詳細な手順は他の多くの記事で既に書かれていますので、ここでは省略します。詳細が必要な場合は、それらの記事を参照してください。
3.2 Lambda関数の設定
Lambda関数は、Alexaスキルのバックエンドとして機能します。ここでは、Lambda関数の作成と設定方法を説明します。特に、一般設定でのタイムアウトの設定、トリガーでのスキルIDの登録、そしてアクセス権限でのIAMサービスのロール設定について詳しく説明します。
タイムアウトはデフォルトの3秒から1分に変更します。これは、ChatGPTからのレスポンスを待つ時間が10秒を超える可能性があるためです。
トリガーでは、作成したAlexaスキルのIDを登録します。
環境変数として、[キー]に「API_Key」という文字列を、[値]に「ご自身のOpenAIのAPIキー」を登録します。
アクセス権限では、事前にIAMサービスで設定した以下の3つのポリシーを許可したロールを使用します。
AmazonDynamoDBFullAccess
AWSLambdaRole
AWSLambdaBasicExecutionRole
「lambda_function.py」をGitHub(こちら)からダウンロードして使用します。また、同じGitHubから4つのzipファイルをダウンロードしてレイヤーに登録します。
ランタイム設定では、「Python 3.9」を設定します。
(ここにLambda関数の設定の手順とスクリーンショットを挿入予定)
3.3 CloudWatchの設定
CloudWatchは、システムの監視とログの確認に使います。ここでは、基本的な設定方法を説明します。具体的には、ロググループを作成することで監視の対象となります。ロググループ名を「/aws/lambda/○○○○」(○○○○はlambda関数名)として作成ボタンを押すだけです。
(ここにCloudWatchの設定の手順とスクリーンショットを挿入予定)
3.4 必要に応じてDynamoDBの設定
DynamoDBは、スキルの永続的なデータストレージとして使います。必要に応じて、DynamoDBの設定を行います。具体的には、テーブルを2つ作成します。1つ目は「RateLimiter」(パーティションキー:user_id)、2つ目は「QuestionRecord」(パーティションキー:user_id、ソートキー:asked_at)。これだけです。項目はLambda関数から呼び出された時に自動的に作成されます。
(ここにDynamoDBの設定の手順とスクリーンショットを挿入予定)
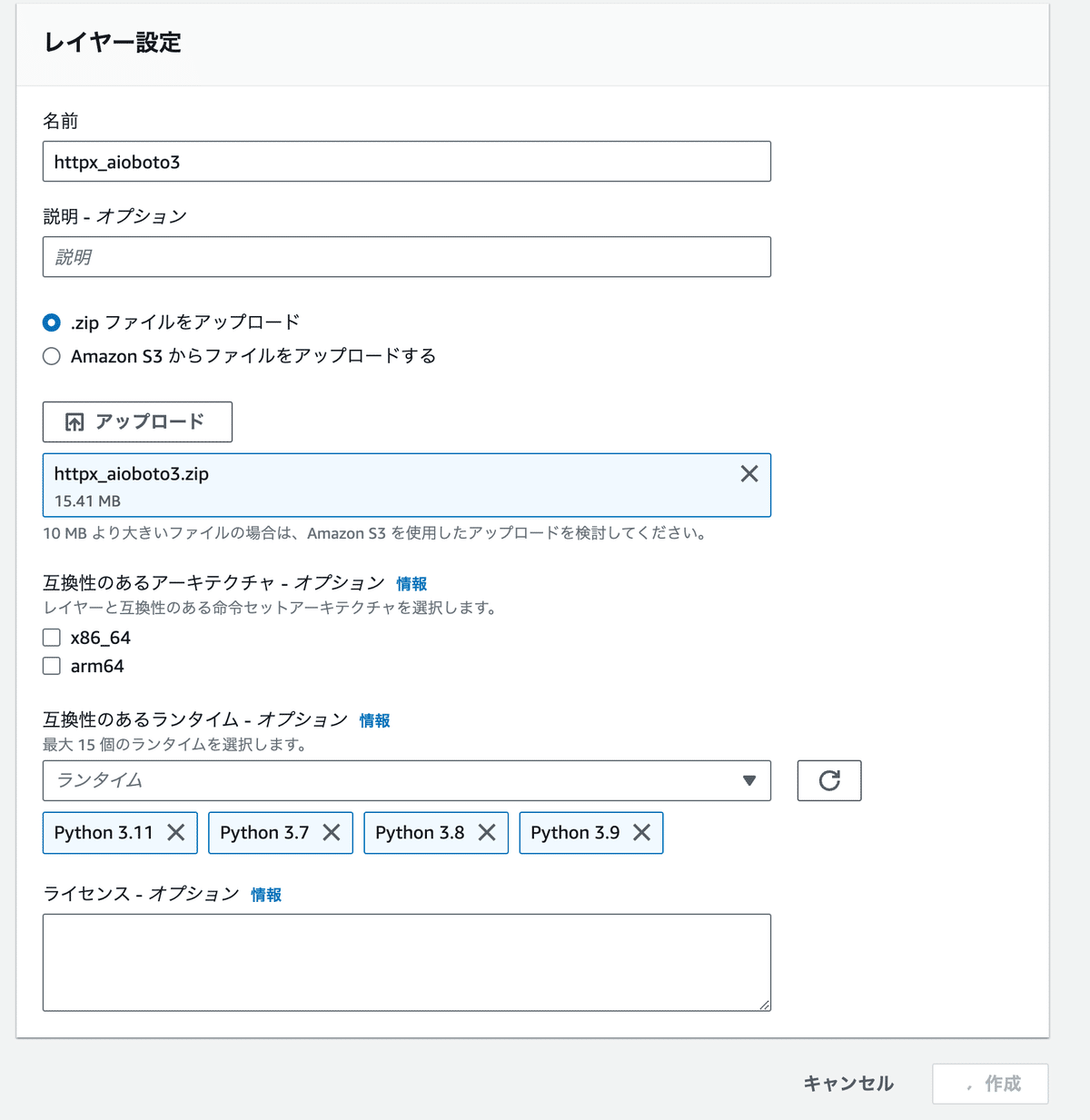
4. 番外編: レイヤーの設定方法
今回の alexaスキル開発のために直接は関係しません。
そのため、読み飛ばしてもらって大丈夫です。
しかし、私が開発した際に一番苦労した箇所なので、備忘録の意味も込めて記録いたしました。
通常なら、pyファイルと一緒にインストールされたライブラリはコードとしてアップするべきなのですが、awsのlambda関数の場合、アップロードの要領が大きいと、コードエディターにより表示されず、編集ができなくなります。
このため、アップするのはpyファイルのみとし、ライブラリはレイヤー(layers)に登録します。
ここでは、その設定方法を説明します。
ローカル環境で新規ディレクトリを作成します。例えば、インストールしたいライブラリ名でrequestsという名前のディレクトリを作成します。
そのディレクトリにpythonという名前のサブディレクトリを作成します。
ライブラリを新しく作成したpythonディレクトリにインストールします。
ディレクトリをzipファイルにパッケージ化します。
AWS Management Consoleにログインし、Lambdaの画面に移動します。
左側のメニューで「Layers」を選択します。
「Create layer」をクリックします。
「Name」にレイヤーの名前を入力します。
「Upload」をクリックして、先ほど作成したzipファイルをアップロードします。
「Compatible runtimes」にPythonのバージョンを選択します。
「Create」をクリックします。
これで、新しく作成したレイヤーをLambda関数に追加することができます。Lambda関数の設定画面で「Layers」を選択し、作成したレイヤーを追加してください。
書いてみると、簡単なようですが、そもそもaws側のライブラリのディレクトリ構造に合わせて、pythonライブラリを作成しなければ読み込めないということが分かるまでに私は苦労しました。
下記具体例の場合、ライブラリ階層は下記の通り
layers
∟ httpx_aioboto3 ←下記例ではここでコマンドを叩いている
∟ httpx_aioboto3.zip
∟ python
∟ httpx_aioboto3 ←これが作成・更新される

pip install xxx -t python
zip -r xxx.zip python
5. テスト
スキルの作成が完了したら、テストを行います。
想定どおりに動くかを、alexa開発コンソールのテストタブで、非公開から開発中に変更して確認して下さい。
私の場合、テストを行う中で、各ユーザーごとに呼び出しの回数制限を設けることを想起できました。
6. まとめ
以上がこどもGPTのAlexaスキルの開発方法となります。誰でも再現できるように、意図したつもりですが、動かないとか細かな質問など何でも、ご相談いただけたらと思います。
こどもGPTの承認がおりましたら、Twitterでも報告させて頂きますので、よろしければフォローお願いします!