
モダンデータスタックの過去、現在、そして未来 by Tristan Handy

こんにちは、Salesforceでプロダクトマネージャーをしている深田です。
日本でも"モダンデータスタック"という言葉を耳にする機会が少しづつ出てきました。モダンデータスタックとは、これまでのレガシーなデータ統合処理の技術と比べて、現代のクラウド環境下にふさわしい設計と考え方に基づく柔軟で新しいテクノロジー/サービス群、その結果発生するデータをより活用するための考え方やアプローチ方法を表します。このデータ統合の根本的な新しいアプローチは、エンジニアとアナリストがより価値の高い活動を追求するために、エンジニアリング時間を節約することができます。また、これらのアプローチはデータ統合への技術的な参入障壁を低く、最新のデータスタックのコンポーネントは、アナリストやビジネスユーザーを念頭に置いて構築されています。つまり、あらゆる経歴のユーザーがこれらのツールを簡単に使用できるだけでなく、深い技術的知識がなくても管理できるようになります。

モダンデータスタックに関しては、以下のブログで概要を掴めます。
前回のnoteでは、こちらの記事を日本語化しています。
このモダンデータスタックはアメリカでは2、3年前からトレンドとなっており、様々なデータに関連するカンファレンスで取り上げられています。そのうちの一つ、Future DataでdbtのCEOであるTristan Handy(@jthandy)がこのトレンドの背景について話しており、とても面白い内容でした。
興味がある方は、ぜひ動画を見ていたただきたいのですが、動画の内容をまとめたBlog👇を公開していたので、時間がない&クイックに概要を掴みたい方のために、翻訳して展開しようと思います📝
The Modern Data Stack: Past, Present, and Future

先日、SisuのFuture Dataカンファレンスでこのタイトルの講演を行ったのですが、私はパワーポイントではなく散文で考えるので、スライドをまとめる前にブログ記事を書く必要がありました。最終的な推敲を重ね、世に送り出すまでに少し時間がかかってしまいましたが、貴重な情報としてご覧いただければ幸いです。講演の全文をご覧になりたい方は、こちらをご覧ください。
過去10年間、データプロダクトは多くの注目を集め、多くの資本を集め、多くのトラクションを生んできました。Stitch Fixは従来の衣料品小売業から100万マイルも離れているし、Airbnbは従来のホテル業とはまったく違う。また、データプロダクトは私たちデータプロフェッショナルのキャリアを根本的に変え、全く新しい職種のスペースを作り、かつては男性的な役割だったものを高度に戦略的なキャリアパスへと昇華させたのです。
🗓Coalesceでは、データプロダクトがどのようにキャリアやチームを変えたか、分析エンジニアリングチームの立ち上げ、データチームの構成、プロダクトマインドの採用など、いくつかの講演を予定しています(来週!)。
しかし、これだけ変化しているのに、ここ数年、ちょっとした停滞期に入ったような気がしています。私自身、2015年末から「モダンデータスタック」に携わるようになり、丸5年が経ちました。この間、このベストオブブリードのスタックを構成する一連の製品は、ある程度一貫しています(このリストは確かに網羅的なものではありません)。
インジェスチョン:Fivetran、Stitch
ウェアハウス:Snowflake、Bigquery、Redshift
トランスフォーメーション:dbt
BI:Looker、Mode、Periscope、Chartio、Metabase、Redash
さらに、この間、それぞれの製品に少しずつ進歩があったことは確かですが、コアとなるユーザー体験が根本的に変わったわけではありません。もしあなたが2016年にリップヴァンウィンクル風に眠ってしまい、今日目覚めたとしても、現代のデータスタックがどのように機能するかについて、あなたのメンタルモデルをそれほど更新する必要はないでしょう。より多くの統合、より優れたウィンドウ機能のサポート、より多くの設定オプション、より優れた信頼性...これらはすべて非常に良いことですが、ある種の成熟、ある種の停滞を示唆しています。2012年から2016年にかけて見られた大規模なイノベーションはどうなったのでしょうか?
はっきり言って、上記の全ては上記の他の製品と同様にdbtに当てはまります。dbt-circa-2016とdbt-circa-2020を比較すると、最新版の方がはるかにパワフルである一方、コアなユーザー体験は非常に似ていることが分かるでしょう。私の目的は、中傷することではなく、私たち全員がキャリアを築いている製品のエコシステムのダイナミクスを理解しようとすることです。
これは、私にとって重要なことだと感じています。人間は道具を作り、道具を使う生き物です。私たちの道具は私たちの能力を定義し、種としての歴史全体を通じて定義してきました。そのため、この分野におけるツーリングの進歩は、実務家である私たちにとってこれ以上ないほど重要なことなのです。2015年に初めてRedshiftを使ったとき、私は超能力を与えられたような気がしました。私はいつ、より多くのものを手に入れることができるのでしょうか?
この記事では、私の目標は、3つの異なる時間枠で現代のデータスタックを見ることです。
カンブリア爆発I(2012年〜2016年
展開、2016年〜2020年まで
カンブリア爆発II、2020年〜2025年まで
この記事では、複数の帽子をかぶっているつもりです。20年以上データ分野でキャリアを積み、これらのツールの一つ一つに深い経験を持つアナリストが、私の第一の帽子です。また、今日のデータスタックの主要製品の1つを構築する機会を得た私の一部である、創設者の帽子も時折かぶることになるでしょう。どちらの帽子をかぶっていようと、私は未来に大きな期待を寄せています。
カンブリア紀の爆発 Ⅰ、2012年~2016年まで
2019年11月にフィッシュタウンアナリティクスが新オフィスに移転したとき、最初にやったことのひとつが、壁に絵を飾ることでした。Redshiftという70年代のモダンアートで、名前が気に入ったのでEverything But The Houseのオークションで購入したものです。私の考えでは、2012年10月にリリースされたAmazon Redshiftをきっかけに、モダンなデータスタックが登場し、その歴史的重要性を記念して、オフィスの入り口にこの巨大な絵画を飾りました。
他のデータスタックのレイヤーのコアプロダクトが誕生した日付を見てみましょう。
Chartio: 2010
Looker: 2011
Mode: 2012
Periscope: 2012
Fivetran: 2012
Metabase: 2014
Stitch: 2015
Redash: 2015
dbt: 2016
また、関連するデータセットとして、これらの企業のうち数社が調達した資金総額に関するコホートデータを別の角度から見てみましょう。2012年は、物事が本格的に動き出した年であることがわかります。

これらの製品のいくつかは、Redshiftの発売前に設立されたものですが、発売がきっかけで成長が加速しました。これらの製品をRedshiftと組み合わせて使うことで、ユーザーの生産性が劇的に向上したのです。Postgres上のLookerも良いが、Redshift上のLookerは素晴らしい。
この一昼夜の違いは、RedshiftのようなMPP(超並列処理)/OLAPシステムとPostgresのようなOLTPシステムの内部アーキテクチャの違いによってもたらされています。この内部構造の完全な議論はこの記事の範囲を超えていますが、もしあなたがよく知らないのであれば、今日のモダンなデータスタックのほぼすべてを形成しているため、このことについてもっと学ぶことを強くお勧めします。
要するに、Redshiftは巨大なデータセットの上で、多くの結合を処理する分析クエリに、OLTPデータベースの10~1000倍の速度で応答することができます。
Redshiftは非常に高性能なMPPデータベースですが、それが最初ではありません。MPPデータベースはその前の10年間に普及しており、それらの製品の多くは素晴らしい性能を持っていました(そして今も持っています)。しかし、Redshiftは初のクラウドネイティブのMPPデータベースであり、年間10万円以上ではなく、月額160円で購入できる初のMPPデータベースだったのです。そして、その価格帯の引き下げにより、突然、門戸が開かれたのです。Redshiftは当時、AWSで最も成長率の高いサービスでした。
10倍から1000倍の性能向上は、製品作りに対する考え方を変える傾向にあります。Redshiftが登場する以前、BIにおける最も困難な問題はスピードでした。比較的単純な分析を行おうとしても、中規模のデータセットの上では信じられないほど時間がかかり、この問題を軽減するためにエコシステム全体が構築されました。
データウェアハウスにロードする前にデータを変換していました。これは、ウェアハウスが遅すぎて(そして制約があって)この重い処理を自ら行うことができなかったためです。
BIツールは、倉庫のボトルネックを回避し、ユーザーが許容できる応答時間を実現するために、多くのローカルデータ処理を行いました。
データ処理は、エンドユーザーのリクエストが多すぎてウェアハウスに負担がかからないように、中央のチームによって厳しく管理されていました。
一夜にして、これらの問題はすべて解決しました。Redshiftは高速で、誰もが使えるほど安価だったのです。これは、それらを解決することでビジネスを構築してきたBIやETL製品がすぐにレガシーソフトウェアとなり、新しい世界に適した製品を構築する新しいベンダーが現れたことを意味します。起業家たちはチャンスと見てこの分野に集まり、これらの製品が今日の世界を大きく定義することになったのです。
このセクションを終える前に、Redshiftの歴史的な意義についての私の発言は、現在最高のデータウェアハウスはどれかというスタンスで受け止めるべきではないことだけは申し上げておきたいと思います。BigQueryが標準SQLをリリースしたのは2016年なのでそれ以前は広く採用されていませんでしたし、Snowflakeの製品が成熟したのは2017年から2018年の時期でした(IMHO)。実際、2016年頃の3製品の使用率の内訳を見ると、Redshiftの使用率が他の2つの合計の10倍になっていると思うんです。つまり、現代のデータスタックで製品を作っている私たちにとって、Redshiftは進化するための海だったのです。
2016年~2020年までの展開
Redshiftが2012年から2016年にかけてあれだけのイノベーションを起こしたのなら、なぜ事態はスローダウンし始めたのでしょうか?これは、この変化率の低下を直感的に感じ始めた2018年からずっと考え続けていることです。コンサルティングのお客様にお勧めしている製品のスタックが、Fishtown Analyticsを始めた当時から変わっていないことに気づき、とても気になったのです。画期的な新製品を見逃していたのだろうか?陳腐化しているのではないか?
しかし、このようなサイクルは業界ではよくあることなのです。主要な実現技術がリリースされると、その分野での技術革新に拍車がかかり、その製品が企業に採用され、展開されていくのです。このサイクルは、過去最大規模の技術シフトの中で起こっています。実際、「鉄道の累積走行距離」を検索してデータを取得したところ、S字カーブが現れました。
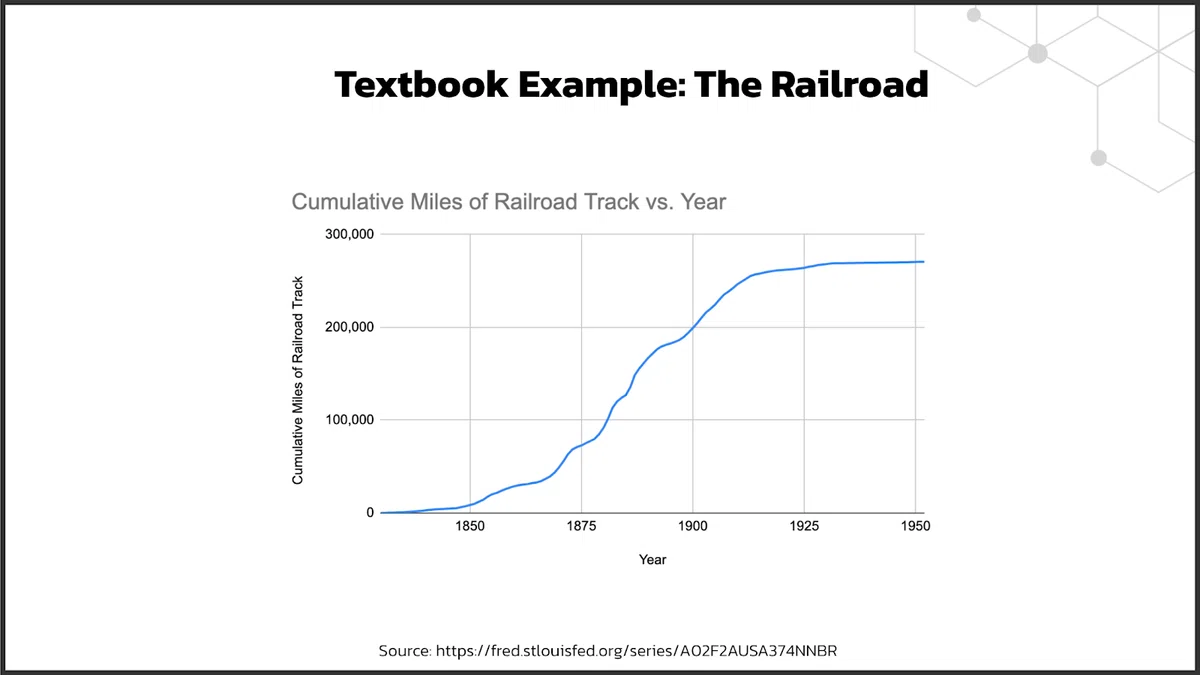
それぞれの技術は、開発から展開まで、それぞれ「S」カーブを描きながら進み、技術が成熟し始めると、新しい顧客を獲得し、技術的にも成熟していきます。
このプロセスは、Carlotta Perezが2010年に発表した基礎となる論文で最も効果的に説明されており、技術的な変化が世界に波及する中で、大小さまざまな形で何度も繰り返されています。
2005年(Verticaのリリース)から2012年(Redshiftのリリース)にかけて私たちが見たものは、MPPデータベースの初期開発段階、つまりS字カーブの始まりでした。そしてそこから、ウェアハウス >> BI >> インジェスチョン >> トランスフォーメーションと推移しています。なお、私たちはまだこのデプロイメントカーブの初期にいますよ。

この理論をユーザーとして検証してみると、チェックが入るのです。上に挙げた製品の文字通り一つ一つの使用感が、この4年間で劇的に向上していることを、私は実体験として伝えることができます。確かにFivetranやStitchは、今でもA点からB点へデータを移動させますが、その信頼性は飛躍的に向上し、コネクタのカバー率も上がりました。私がよく知るdbtは、2016年以降、よりモジュール化され、より高性能になり、より拡張性が高くなりました-すべて基本的なUXを変えることなく。
これが、S字カーブを上るということです。アーリーアダプターは寛容ですが、テクノロジーはより多くのオーディエンスに採用されるよう改善する必要があります。トーマス・エジソンは1874年に電信多重化装置を発明し、Western Unionが既存の回線のスループットを4倍にすることを可能にしました。同じ電信機で、より多くのスループットを実現したのである。

このフレームで見ると、実はとてもエキサイティングなことなのです。私たちは、これらの基盤技術が成熟し、より多くのユースケースをカバーするようになり、より信頼性が高まっているのを目の当たりにしているのです。これらはまさに、現代のデータスタックに次のイノベーションの波を起こすために必要なことであり、現在の基礎的なテクノロジーによってその波が解き放たれることになるのです。
カンブリア爆発 II、2021年~2025年まで
簡単にまとめましょう。2012年にRedshiftが発表された直後、私たちは非常に多くのイノベーションを経験し、全く新しいレベルのパフォーマンス、効率性、そして新しい行動を解き放ちました。その後、これらの初期製品が市場に導入され、技術を改善し、機能セットを充実させていく過程で、成熟期が訪れました。そして今、これらの製品は、次なるイノベーションを生み出すための土台となる準備が整っているのです。
つまり、カンブリア紀の爆発的なイノベーションの波がまたやってくるということです。どんなイノベーションが起こるのでしょうか。
私は予言者ではありませんが、このようなことを考えるのに多くの時間を費やし、この分野の製品を作り、投資している興味深い人たちとたくさん会話しています。私は、今日の世界の状況から、良いことも悪いことも含めて、有益なヒントを得ることができると思います。良い面は強さを表すものであり、私たちの強固な基礎となるものであり、悪い面は機会を表すものです。

このような変化の多くは、すでにその芽が見え始めているのではないでしょうか。では、見ていきましょう。
ガバナンス
ガバナンスは、今こそ必要な製品分野です。この製品カテゴリは、データ資産の発見、リネージ情報の閲覧、データ利用者がデータ先進企業内の膨大なデータフットプリントをナビゲートするのに必要なコンテキストの提供など、幅広いユースケースを包含している。この問題は、最新のデータスタックによって、より多くのデータを取り込み、モデル化し、分析することがますます容易になっているため、さらに困難になっています。
良いガバナンスがなければ、データの増加=混沌=信頼低下となります。
この分野では以前から商用製品がありましたが(CollibraとAlationが最もよく引用されます)、それらは企業の購入者に焦点を当てる傾向があり、最新のデータスタックの他の部分に当てはまるような幅広い採用は見られません。そのため、ほとんどの企業は現在、ガバナンス製品を使用していません。
dbtには、非常に軽量なガバナンスインターフェースであるdbt Docsがあり、今後数年間はこの既存の機能を拡張するために多くの作業を行うことが予想されます。
私たちがこの分野に興味を持ったのは、ビッグテックの内部で行われている仕事に大いに触発されたからです。多くの大手ハイテク企業は、非常に優れたデータガバナンス製品を社内で構築しています。
Linkedin: DataHub
Lyft: Amundsen
WeWork: Marquez
Airbnb: Dataportal
Spotify: Lexikon
Netflix: Metacat
Uber: Databook
(ここで見逃しているものもあると思うので、私が名前を挙げていないプロジェクトに所属している人がいたら申し訳ない)
これらのプロジェクトに関わった人々のうち、何人かは、その後、自分の仕事を商業化するために、ビッグテックの雇用主のもとを去っています。また、この傾向に対して、ベンチャーキャピタルの熱意が広く伝わっています。この組み合わせは、イノベーションのレシピと言えるでしょう。
このトピックをもっと深く知りたい方は、Drewが来週のCoalesceでメタデータに関するディスカッションをリードします。
リアルタイム
ダッシュボードを作成して分析的な質問をするだけであれば、データのリアルタイム性は気にならないかもしれません。実際、収益、コホート行動、アクティブ・ユーザーの傾向に関する質問に答えるには、1日に1回新しいデータを取得すれば十分かもしれません。しかし、私たちが最新のデータスタックの一部として構築しているデータインフラには、一般的に「データ分析」と考えられているものをはるかに超える、多くの潜在的な使用事例があります。ここでは、そのいくつかをご紹介します。
製品内分析
自社製品の内部にダッシュボードを構築し、ユーザーにとって有用なレポートを作成したい場合があります。オペレーショナルインテリジェンス
ビジネスの中核となる業務を担当する社員が、今、世の中の状況を知る必要がある場合があります。この領域では、在庫やロジスティクスが非常に一般的なニーズです。これはJetBlueにとって重要な要素であり、AshleyがCoalesceの講演でこれを取り上げるのを聞くか、Slackのスピーカー・オフィス・アワーで彼女に聞いてみるとよいでしょう。https://coalesce.getdbt.com/talks/the-operational-data-warehouse/プロセスの自動化
アナリティクスのための高度なデータパイプラインはすでに構築されていますが、そのデータをCRMやメッセージングプラットフォームにパイプバックし、その上で下流イベントをトリガーできるとしたらどうでしょう。これは非常に大きな可能性を秘めた領域です。次のセクションで詳しく説明します。
しかし、パイプライン全体のレイテンシーを15秒から60秒に短縮することで、この技術の新たな活用事例が生まれるかもしれません。最終的には、業務報告書を動かす神経系は、他のユースケースを動かしている神経系と同じであるべきなのです。
そして、この技術が手の届くところにあることを示す信号が届き始めているのです。主要なデータウェアハウスはそれぞれ、よりリアルタイムなフローを実現するための構造を初期にサポートしています。Snowflakeはストリーム機能に重点を置き、BigqueryとRedshiftはマテリアライズド・ビューに重点を置いている。どちらのアプローチも正しい方向に進むものですが、私の知る限りでは、どちらも今日そこに到達するまでには至らないようです。この点については、3つのプロバイダーとも革新的な取り組みを続けています。
もう1つ興味深いのは、Kafkaの上にストリーミングSQLを構築するKSQLだ。これは確かに興味深く有望なのですが、実行可能なSQLにいくつかの制限があるため(特に結合に関して)、私にとっては「まだそこまでには至っていない」というのが正直なところです。
新製品の分野では、「Materialize」という製品に期待しています。これはPostgres互換のデータストアで、ほぼリアルタイムのマテリアライズド・ビューをネイティブにサポートし、ストリーム処理構造の上に一から構築されたものです。
最後に、データベース自体がリアルタイム処理をサポートしていても、インジェストもリアルタイムである必要があります。Meroxaは、リレーショナルデータストアとウェブフックからCDCをプラグアンドプレイで提供する製品です。このような製品は、私たちがストリーミングの世界に到達するための重要な鍵になるでしょう。誰もDebeziumを立ち上げて管理したくはないでしょう。
私たちはまだそこに到達していませんが、壁に書かれた文字を見始めることができます。これから数年の間に、このようなことが起こり始め、素晴らしいものになるでしょう。
フィードバックループの完成
今日、データは業務システムから最新のデータスタックに流れ込み、そこで分析されます。しかし、そのデータが何らかのアクションを起こすためには、人間が主体的にデータを収集し、アクションを起こさなければなりません。もし、最新のデータスタックが単にデータ分析を支援するだけでなく、実際に運用システムに直接提供されるとしたらどうでしょうか。
ここには、膨大な数の潜在的なユースケースがあります。ここでは、ごく基本的なものをいくつか挙げてみます。
カスタマー・サポートのスタッフは、会社で使用しているヘルプデスク製品の中ですべての時間を過ごしています。倉庫から直接ヘルプデスク製品に主要なユーザー行動データを取り込み、エージェントが顧客をサポートする際に利用できるようにします。
同様に、営業担当者は、すべての時間をCRMの中で過ごします。製品のユーザー行動データをCRMのインターフェイスに直接入力することで、よりコンテキストに富んだ会話ができるようになります。
無数のイベントトラッキングを実装するよりも、コア製品のクリックストリームをメッセージング製品に直接フィードして、自動メッセージングフローをトリガーすることができます。
このような使用例は氷山の一角に過ぎないと思います。このトレンドが実際に解き放つのは、データ/ビジネスアナリストがビジネス全体をプログラムできるようになることです。リアルタイム性はこのトレンドのすべてを強力にしますが、数時間のエンド・ツー・エンドのレイテンシーでも、これらのユースケースの多くには十分なのです。
私は2014年以来、この種のデータ移動を促進するためのハッキリとしたスクリプトを書いてきましたが、ようやくこの分野のツールが牽引され始めているのを目にするようになりました。CensusとTrayは私が最もよく知るものですが、他にも私が知らないものがあるはずです。
もしあなたが今dbtのコードを書いているなら、かなり近い将来、このコードは社内の分析だけでなく、本番のビジネスシステムにも力を発揮するようになると思ってください。そうなれば、あなたの仕事はもっとやりがいのあるものになり、もっとエキサイティングなものになるはずです。
これはすぐに実現することです。
このトピックをもっと深く知りたい方は、来週Coalesceで開催されるThe Future of the Data Warehouseにご参加ください。
データ探索の民主化
ここで、議論を呼びそうな意見があります。私は、意思決定者、つまりデータがもたらす業務上の意思決定に実際に責任を負う人々は、最新のデータスタックでは十分なサービスを受けていないと考えています。エグゼクティブはどうでしょう?もちろん、彼らは素晴らしいダッシュボードを手に入れることができます。アナリストは?もちろんです。しかし、Excelを主な仕事道具としている人は非常に多く(数億人)、最新のデータスタックの登場により、彼らのデータ体験は実際に悪化していると私は考えています。彼らは突然、参加できなくなったのです。
奇妙に聞こえるかもしれませんが、かつてExcelは生産用でした。ネットワークドライブ上で、あるワークブックを別のワークブックから参照することができ、最終的には強力なデータシステムを構築することができたのです。もちろん、それは信じられないほど脆弱で、安全でなく、エラーを起こしやすいものでしたから、それを再現しろと言っているのではありませんよ。しかし、そのような環境では、非常に多くのデータ消費者が、現在の環境よりもより多くの力を発揮していたと私は信じています。
確かに、SQLを使用しないデータ利用者には、今日、多くの選択肢があります。主要なBIツールはすべて、SQLを使わずにデータを探索できるような何らかのインターフェースを持っています。しかし、そのどれもが(悲しいかなLookMLも含めて)Excelのように広く普及し、創造的な柔軟性を発揮するレベルには到底及んでいない。このパラダイムが定着していることを示すように、データ利用者はBIツールからExcelワークブックにデータをエクスポートし、そこでデータをいじり続けているのをよく見かける(データチームの同僚が悔しがるほどだ)。
ここでの課題は、自明ではありません。データ利用者がセルフサービスできる強力で柔軟なツールがなければ、現代のデータスタックは永遠に一部の人たちのものでしかないでしょう。これは悪い結果です。
ここでまた物議を醸す発言があります。スプレッドシートが実は正しい答えだとしたらどうでしょう?スプレッドシートは、データを探索するための、よく理解された、強力で柔軟なユーザーインターフェイスです。問題は、スプレッドシートのUIがまだ最新のデータスタックに持ち込まれていないことです。それはどのようなものでしょうか。
私は2つの有望なアイデアを見たことがあります。まず、データをスプレッドシートに持ってくることです。ほとんどすべてのBI製品は、これの悪いバージョンを行うことができます。「Excelとしてダウンロードする」のだ。しかし、これは良い解決策ではない。スプレッドシートをデータ基盤の他の部分から即座に切り離してしまうからだ。前にも述べたように、スプレッドシートの相互リンクとライブアップデートは、Excelベースの現状では常に重要な要素でした。
スプレッドシートとデータソースのリンクを維持し、定期的にデータを更新することで、「Google Sheetsと同期」することができます。ユーザーは、追加のタブでソースデータの上に構築することができます。私が見た中で、このアプローチの最良の実装は、SeekWellと呼ばれる製品です。これは有望です。
2つ目のアイデアは、表計算ソフトで計算式を作成し、それをSQLにコンパイルしてデータベースに対して実行することです。基本的に、スプレッドシートのインターフェースは、ウェアハウス内のデータを直接照会するためのUIに過ぎず、データ利用者がより広く理解できるものでなければなりません。このアプローチは、Sigma Computingという製品で最もよく例証されています。最終的には、1列につき1つの数式という非常に制約の多いパラダイムに固執することになるため、完全なスプレッドシートらしさは実現できませんが、それでもこの問題に対する興味深い取り組みだと思います。
このように、私はデータ消費者探索の正しい答えがスプレッドシートであると確信しているわけではありません。しかし、私が非常に自信を持っているのは、データ消費者のセルフサービスによるデータ探索は、今後数年のうちに解決されるということです。なぜなら、この問題はあまりにも明白であり、ビジネスチャンスがあまりにも大きいからです。
技術的なハードルはなく、構成要素はすべて揃っています。難しいのは、UXをどうするかということです。
垂直的な分析体験
Google Analytics、Mixpanel、KissMetricsが唯一のゲームであった2012年のウェブ解析の世界には、大きな目立った問題がありました:それらはデータサイロでした。これらのツールのデータにアクセスする方法はGUIだけで、他の場所にあるデータと一緒にすることはできませんでした。他のシステムからデータを取り込む場合は、イベントとして取り込む必要があったため、データの重複が発生していました。少しでも成熟したデータ組織を運営したことのある人なら、これがどんなクラスターになるかを知っているはずだ。
この時代には、さまざまなデータストアが垂直統合され、それぞれ独自のデータのコピーを持ち、独自のインターフェースの中に閉じこめていました。しかし、私たちは赤ん坊を風呂の水と一緒に捨ててしまったようなものです。
垂直化された分析体験には、非常に大きな価値があります。データを一連のウェブイベントとして捉える分析ツールは、行や列を見るだけのツールよりも、よりスマートなオプションを提示することができるだろう。Google Analyticsは、ウェブトラフィックデータの分析において、最新のデータスタックに含まれるどのBIツールよりも強力なツールである。これは驚くべきことではありません。
では、すべてのデータを行と列として扱う水平型のツールと、特定の種類のデータを分析するために構築された垂直型のツールでは、どちらが優れているのだろうか。答えは、「両方が必要」です。しかし、今、私たちに欠けているのは、最新のデータスタック上に構築された垂直型の分析インターフェースです。Google Analyticsのように、Google独自のバックエンドに接続するのではなく、自社のデータウェアハウスに接続する製品が必要なのです。イベントテーブルの場所を指示し、キーフィールド(ユーザーID、タイムスタンプ、セッションIDなど)を呼び出すと、インターフェースとのすべてのインタラクションをSQLにまとめ、それを探索することができます。
しかし現在では、高速なウェアハウス、標準化された取り込みツール、パッケージ管理が組み込まれたオープンソースのモデリングがあり、ユーザーに「ウェブ解析データを見せてください」と言えば、実際にデータを見せてもらえることが現実的に想像できるようになりました。そうすれば、サイロで作業することも、最適とは言えない探索的な体験に悩まされることもなくなり、両方の世界を手に入れることができるのです。
私は、最新のデータスタックを使用する企業が増えるにつれて、このような軽量で垂直化された新しいアプリケーションを構築する機会が大幅に増加すると考えています。これは、Lookerのアプリマーケットプレイスですでに見られる方向性ですが、この機会はLookerのユーザーだけでなく、はるかに大きなものだと思います。私の推測では、以前の時代のGoogle Analyticsのように、この方法で構築された単一の製品を中心に企業が作られるようになると思います。
役に立つストーリー?
このテーマについて丸2年考えた末にたどり着いたのが、上記のようなストーリーです。確かに、私が立てた特定の予測が必ず当たるとは思っていませんが、全体的なシナリオとしては方向性が正しく、有用だと考えています。
この業界は開発と展開の波を経験しており、その波はこの分野のすべての実務者に影響を与えるので、この地図を頭の中に入れておくことは方向性を定めるのに良い方法です。急速な変化の時期は、個人にとっても企業にとっても可能性を秘めた時期であり、今まさにその時期が始まろうとしているのです。
最後まで読んでいただきありがとうございました。
面白かった人はnoteのスキとTwitterのフォローをお願いします!
今後もnoteとTwitterでプロダクトマネジメントやデータ分析に関して情報を発信していくのでよろしくお願いします🙌
⚡️ “プロダクトマネージャーとしてのつぶやき。” by @fkohe1 https://t.co/crXAQYGHlK
— ふかだこうへい | Salesforce PM ☁ (@fkohe1) November 28, 2021