
【Bike Sharing Demand|レンタサイクルの需要予測】 自転車は何台レンタルされる?データ分析未経験者がKaggleに挑戦!

エスタイルのデータサイエンス事業部新入社員の「フィル」こと衣斐です。
入社時に研修の1つとしてKaggleコンペに挑戦しましたので、これから機械学習を学ぶ方はぜひ読んでみてください!
1.コンペ概要
このコンペは2015年〜2016年に開催されていました。Kaggleの概要を読んでみると次のようなことが分かります。
レンタサイクルは、
・入会、レンタル、返却が自動化されている
・レンタル時と違う場所に返すことができる
・世界中に500を超えるサービスがある
このコンペでは、ワシントンD.C.のレンタサイクルの過去の利用データと気象データを使って、需要予測をする。
僕もよくレンタサイクルを使うのですが、近所のコンビニで借りて乗り捨てできるので、とても重宝しています。
一方で、どこでも返せるというメリットが裏目に出て、近隣のステーションに自転車がなくて借りられなかったり、ステーションが満車で返却できなかったりということもあり、ぜひ機械学習を使った需要予測モデルで解決して欲しい問題です。
スコアの計算方法
最終的なスコアはRMSLE(対数平方平均二乗誤差)により計算されます。

予測値と実測値の対数差の二乗の総和の平均値のルートをとったものです。
RMSLEの特徴として、以下が挙げられます。
・予測値が実測値より小さい場合にペナルティが大きくなる
・予測値の振れ幅が大きい場合に有効
・誤差を幅ではなく、割合として見ている
レンタサイクルでは利用者数を少なく予測してしまうと、利用できない人が出て機会損失となってしまいます。logを使わないRMSE(二乗平均平方根誤差)もありますが、今回のケースではRMSLEが評価関数に適しています。
2.データセット
このコンペでは、以下の3つのデータが与えられます。
・train.csv:学習データ
・test.csv:テストデータ
・sampleSubmission.csv:提出ファイルのサンプル
学習データには1時間ごとのレンタサイクルの利用者数が入力されています。
提出ファイル(sampleSubmission.csv)を見てみると、列名がdatetimeとcountになっていることから、予測するのはcasualとregisteredの合計だけで良いことがわかります。
学習データ(train.csv)の内容
datetime:日付と時間
season:季節 (1:春、2:夏、3:秋、4:冬)
holiday:祝日
workingday:平日
weather:天気 (1:晴れ、2:曇り、3:雨、4:ひどい雨)
temp:気温
atemp:体感気温
humidity:相対湿度
windspeed:風速
casual:非登録ユーザー
registered:登録ユーザー
count:全体利用者数(casualとregisteredの合計:予測ターゲット)
学習データは12列、10886行
テストデータは9列、6493行(casual, registered, countが欠損)
となっています。
各月の1〜19日が学習データ、20日〜月末がテストデータです。
ほとんどのデータが数値データとして与えられているため、非常に処理しやすいデータセットとなっています。
3.データ分析
前処理
本コンペのデータは数値データがほとんどなので前処理はサクッと終わります。datetimeだけ「年-月-日-時」という形式になっているので、分解して新しい列を作ります。以下のように新しい列を追加しました。
・year:年
・month:月
・day:日
・hour:時間
可視化
データを利用できる形に処理したので、可視化をして分析を進めます。まずは利用者数を棒グラフで可視化してみます。

登録ユーザーの割合が多く、非登録ユーザーは全体の4分の1以下となっているようです。次に利用者数のヒストグラムを描画します。

横軸は利用者数、縦軸は相対頻度です。
casual(非登録ユーザー)は利用者10人以下のデータがかなりの割合を占めていますが、registered(登録ユーザー)では利用者200人程度のデータが多いです。count(利用者数)全体では、データの傾向は利用者数の多いregisteredに近くなっています。
続いて、各変数の相関を調べます。今回は量的データについて、相関係数が直感的にわかるヒートマップを使ってみたいと思います。

縦軸のcasual, registered, countに着目して右方向にグラフを見て行きます。明らかに正の相関があるのはtemp, atempです。弱い正の相関があるのはwindspeed、弱い負の相関があるのはhumidityのようです。
最後にカテゴリーデータについても可視化をします。
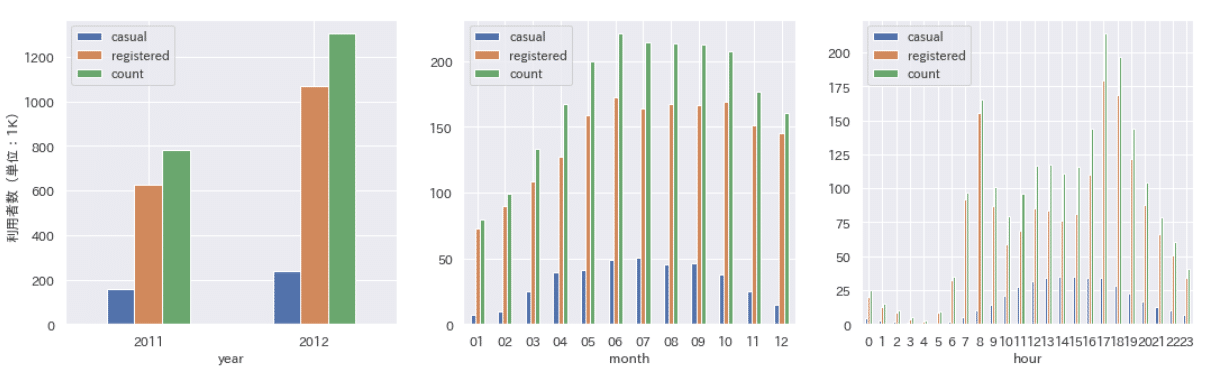
利用者は1年で1.5倍程度に伸びていることがわかります。月別では5月〜10月の利用者が多く、過ごしやすい気候が影響していそうです。時間帯別では8時と18〜19時の登録ユーザーが多く、通勤・通学目的の利用者と推測できます。

季節別で見ると夏と秋が多く、月別での結果と一致します。日付区分では平日に登録ユーザーが多く、週末や祝日は相対的に非登録ユーザーの割合が増えます。天気別では晴れの利用者が多く、雨が降ると利用者が激減することがわかります。
4.モデリング・予測
モデリング
今回はKaggleでかなりの実績をあげているLight GBMでモデリング・予測をしました。条件は以下の通りです。
目的変数:casual, registered(別々に予測し、合算)
説明変数:temp, holiday, workingday, weather, year, hour
ハイパーパラメーター:default

横軸が学習データの値、縦軸がモデルの予測値です。青い丸が赤い線上に近いほど精度の良いモデルといえます。予測値に負の値がありますが、そのまま提出するとエラーになるのでゼロにするという処理が必要でした。
特に工夫をしなくてもそこそこのスコアを出すことができましたが、±100程度のブレがあり低めの予測値が多いのでまだ改善できそうです!
5.モデル改善
目的変数の変換
一般に機械学習では、目的変数のヒストグラムが正規分布から離れていくと予測が難しくなります。
今回予測する利用者数は100人以下のボリュームが多い一方で、1000人に近いデータもあり予測が難しいデータであるといえます。予測値を大きく外すと評価関数の値が悪くなってしまうので数値の大きいデータにモデルはフィットしてしまいますが、一方で数値の小さいデータの精度が悪くなります。
こういったケースでよく使われる方法が変数変換です。今回は対数・ルート・逆数への変換を試してみた結果、ルート変換の精度が最もよくなりました。ルート変換した利用者数のヒストグラムを描いてみると、正規分布に近付いているのがわかります。

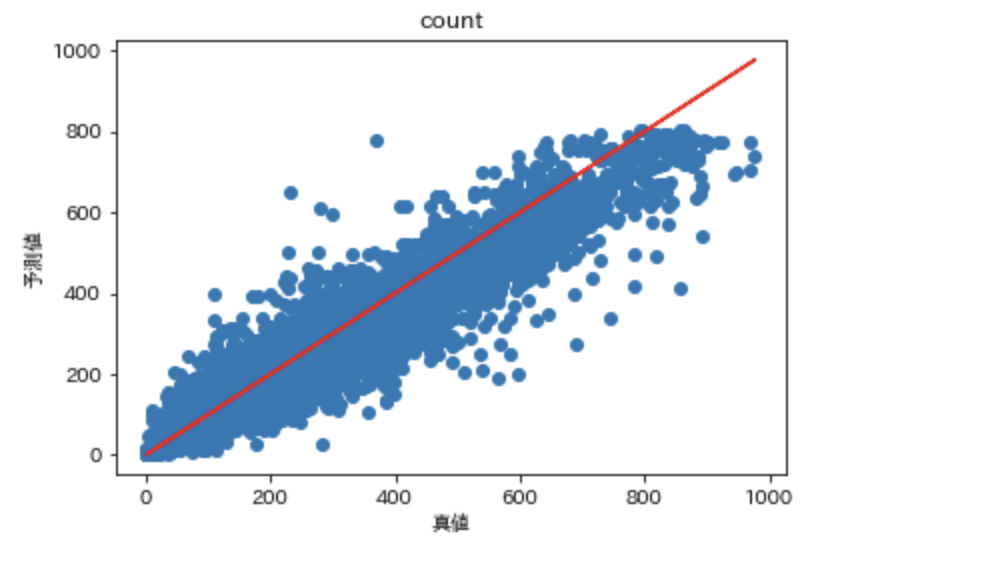
目的変数をルート変換したモデルでは予測誤差が全体的に小さくなっていることがわかります。また、負の値の予測値がなくなったことも大きな改善点です。リーダーボードでも700位程度となり、精度がかなりよくなりました。
散布図を見ると過小予測の傾向がありますが、ヒストグラムを見てもわかる通り利用者数の少ないデータに引っ張られている傾向があります。変数変換を工夫してヒストグラムをさらに正規分布に近付けたり、有用な特徴量を追加したりすればまだ精度改善できそうです!
まとめ
各月の20日以降のデータがないというデータセットでしたが、意外と精度良く予測することができ、機械学習の威力を実感しました。実は特徴量をいくつか作ってみたり、ハイパーパラメータチューニングをしてみたりもしたのですが、結局シンプルに変数変換をしたモデルが一番精度がよかったというのも新たな発見でした。
コンペ自体は終了しているものの、とても扱いやすいデータセットなのでみなさんもぜひトライしてみてください。
採用情報
ESTYLEは「コウキシンが世界をカクシンする」という理念のもと、企業のDXを推進中です。経験・知識を問わず、さまざまな強みを持ったエンジニアが活躍しています。
弊社では、スキルや経験よりも「データを使ってクライアントに貢献したい」「データ分析から社会を良くしていきたい」という、ご自身がお持ちのビジョンを重視しています。
ご応募・問い合わせはこちら。
この記事が気に入ったらサポートをしてみませんか?