初心者がローカルLLM動作環境を構築してみた(Proxmox+Ubuntu+Python+llm-jp)

はじめに
概要
・インフラエンジニア(自称)がローカルLLMの動作環境を構築
・Pythonというプログラム言語でとりあえずLLMを動かした
・LLM初心者なので、とりあえず計算時間のみ確認した
想定読者
下記を満たす方を想定しています。
・Linuxの導入経験がある方
・何かしらのプログラム言語を書いたことがある方
・基本情報レベルのITの知識がある方
背景
ChatGPTやCopilotなどとても便利な生成AIがどんどん出てきていますが、セキュリティやカスタマイズ性を考えた際にはローカルLLMといった選択肢が出てくると思います。
また、パブリックな生成AIを使うにしても、仕組みを知っておいた方がきっと良いだろうと思い、LLMもPythonもよく分かっていない身ではありますが、とりあえず環境構築して動かしてみようと思います。
動かすモデルは、最近ニュースが出てきたのでNIIで作成されたものを使ってみようと思います。
このモデルは利用許諾契約を見ると、個人利用かつ公序良俗に反さない利用なら問題なさそうです。
また、パラメータ数が18億、37億、130億、1720億とバリエーションがあるので、計算時間の差を見ていきます。
llm-jp/llm-jp-3-1.8b-instruct
lllm-jp/lm-jp-3-3.7b-instruct
llm-jp/llm-jp-3-13b-instruct
llm-jp/llm-jp-3-172b-instruct3
使用方法や必要なライブラリは公式で丁寧に書かれているので、これに則って構築していきます。
目次
マシン構成
Minisforum MS-01のIntel® Core™ i9-12900H + NVIDIA RTX A1000の構成に、Proxmoxをハイパーバイザとして入れて、その上にUbuntuを導入しています。
物理マシン
・CPU:Intel® Core™ i9-12900H
・メモリ :DDR5-5200Mhz 64GB
・ストレージ:SSD 500GB
・グラボ:NVIDIA RTX A1000 8GB
・OS:Proxmox VE 8.3
仮想マシン
・OS:Ubuntu-24.04.1-live-server-amd64.iso
・CPU:20コア
・ディスクサイズ:448GiB
・メモリサイズ:60000MiB (約60GB)
注意事項
・様々なLLMを試す場合、ストレージはもっとあった方がよさそうです。
・グラボのブラケットを変える際は特殊ドライバー(T6)が必要でした。
解説
・LLMを扱う処理は並列処理となるため、CPUだけでなく、並列処理が得意なGPUやDPUを使った方が処理時間が早くなるそうです。
・DPUは調達が困難+物理的にMS-01には搭載が負荷+ノウハウがあまりないため、今回はおとなしくGPUにしました。
環境構築(Proxmox)
Ubuntuの仮想マシン(VM)の作成が終わったところからになります。
そのうえで、PCIパススルーを使ってVMからGPUを直接参照可能にします。
具体的には、NICやグラボなどPCIで拡張されているデバイスはPCIのIDを持つので、このIDを調べたうえで、VMにこのIDは直接参照するよう教えてあげます。
pveにてNVIDIAのPCIのIDを確認
lspciを実行。01:00.0であることが分かる。
@pve:~# lspci | grep NVIDIA
01:00.0 VGA compatible controller: NVIDIA Corporation GA107GL [RTX A1000] (rev a1)
01:00.1 Audio device: NVIDIA Corporation Device 2291 (rev a1)PCIパススルーの設定
VMからグラボを直接参照できるようにします。
ProxmoxのWebUIから「ハードウェア」→「追加」→「PCIデバイス」と選択。

その後、「Rawデバイス」を選択→「デバイス」から先ほど確認したID(01:00.0)を選択→「全機能」にチェックとします。

VMがGPUを認識しているか確認
VMにてlspciを実行。下記の通りグラボを認識している。
※もしlspciが無ければ利用しているLinuxにあわせてインストールが必要です。パッケージ名はpciutilsです。
$ lspci
(略)
00:10.0 VGA compatible controller: NVIDIA Corporation Device 25b0 (rev a1)
00:10.1 Audio device: NVIDIA Corporation Device 2291 (rev a1)全機能にチェックを入れたため、00:10.0のみでなく、00:10.1も追加されている。
余談だが、PCIパススルーをするとホストOS(Proxmox)から対応のPCIデバイス、つまりグラフィックボードが見えなくなる。そのため、グラボにケーブルをつないで画面出力していた場合は、マザボにケーブルをつなぎ変える必要がある。
環境構築(VM)
VMのセットアップをしていきます。
ストレージの拡張やpythonのインストールは、Linuxのディストリビューションによって対応有無が変わってくると思います。
ディストリビューション確認
$ cat /etc/issue
Ubuntu 24.04.1 LTS \n \lSSH接続可能にする
$ sudo apt install openssh-server
$ sudo systemctl enable ssh
$ sudo systemctl start sshストレージの拡張
446GB分のディスクをVMに割り当てているのに、約100Gしか利用できなかった。
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 5.8G 1.2M 5.8G 1% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 98G 85G 8.3G 92% /
tmpfs 29G 4.0K 29G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/sda2 2.0G 95M 1.7G 6% /boot
tmpfs 5.8G 12K 5.8G 1% /run/user/1000下記で拡張
$ sudo lvextend -l +100%FREE /dev/mapper/ubuntu--vg-ubuntu--lv
New size (114175 extents) matches existing size (114175 extents).
$ sudo resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv
resize2fs 1.47.0 (5-Feb-2023)
Filesystem at /dev/mapper/ubuntu--vg-ubuntu--lv is mounted on /; on-line resizing required
old_desc_blocks = 13, new_desc_blocks = 56
The filesystem on /dev/mapper/ubuntu--vg-ubuntu--lv is now 116915200 (4k) blocks long.割り当てられた (/dev/mapper/…. が 98Gから439Gになった)
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 5.8G 1.2M 5.8G 1% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 439G 88G 333G 21% /
tmpfs 29G 4.0K 29G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/sda2 2.0G 95M 1.7G 6% /boot
tmpfs 5.8G 12K 5.8G 1% /run/user/1000パッケージ回り
$ sudo apt update
$ sudo apt upgradePythonのバージョン確認
Python3がインストール済みだった。
$ python3 -V
Python 3.12.3pipインストール
$ sudo apt install python3-pip
$ pip3 --version
pip 24.0 from /usr/lib/python3/dist-packages/pip (python 3.12)pythonのvenvをインストール
$ sudo apt install python3-venv環境構築(GPU向け)
GPUを有効化していきます。ディストリビューションと利用しているGPUによって手順は変わります。今回はUbuntu+RTX A1000の場合になります。
ドライバをインストール
$ sudo ubuntu-drivers install※下記サイト参照
再起動
$ sudo reboot確認
$ nvidia-smi
Tue Dec 31 22:18:05 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.120 Driver Version: 550.120 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA RTX A1000 Off | 00000000:00:10.0 Off | N/A |
| 31% 57C P8 N/A / 50W | 2MiB / 8188MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+環境構築(LLM向けライブラリ追加)
必要なライブラリとバージョン
公式サイトにある通り、次の5つのライブラリを入れていく
Required Libraries and Their Versions
torch>=2.3.0
transformers>=4.40.1
tokenizers>=0.19.1
accelerate>=0.29.3
flash-attn>=2.5.8
Pythonの仮想環境を作成
ライブラリを入れる前に仮想環境の準備をします。
myenvは他の文言でもOKです。
$ python3 -m venv myenvアクティベートを実施、完了するとプロンプトの先頭に(myenv)がつきます。
$source myenv/bin/activate
(myenv)$torchをインストール
torch>=2.3.0 なら良い
(myenv) $ pip3 install torch
(myenv) $ pip3 list | grep torch
torch 2.5.1transformersをインストール
transformers>=4.40.1 なら良い
(myenv) $ pip3 install transformers
(myenv) $ pip3 list | grep transformers
transformers 4.47.1tokenizersをインストール
tokenizers>=0.19.1 なら良い
(myenv) $ pip3 install tokenizers
(myenv) $ pip3 list | grep tokenizers
tokenizers 0.21.0accelerateをインストール
accelerate>=0.29.3 なら良い
(myenv) $ pip3 install accelerate
(myenv) $ pip3 list | grep accelerate
accelerate 1.2.1flash-attnをインストール
flash-attn>=2.5.8 なら良い
エラーが出たので苦戦した結果、実行したコマンドが下記。
(myenv) $ pip install -U pip
(myenv) $ python -m pip install -U pip
(myenv) $ pip install -U wheel
(myenv) $ pip install -U setuptools
(myenv) $ wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.0-1_all.deb
(myenv) $ sudo dpkg -i cuda-keyring_1.0-1_all.deb
(myenv) $ sudo apt-get update
(myenv) $ sudo apt-get -y install cuda最終的にうまくいきました。
(myenv) $ pip3 install flash-attn
(myenv) $ pip3 list | grep flash-attn
flash-attn 2.7.2.post1コードの作成と実行
コードの作成
公式サイトのコード(https://huggingface.co/llm-jp/llm-jp-3-172b-instruct3)を基に微修正を実施。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import datetime # 時間計測用
print(datetime.datetime.now()) # 開始時間
model_name = "llm-jp/llm-jp-3-1.8b-instruct"
#model_name = "llm-jp/llm-jp-3-3.7b-instruct"
#model_name = "llm-jp/llm-jp-3-13b-instruct"
#model_name = "llm-jp/llm-jp-3-172b-instruct3"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.bfloat16
)
chat = [
{"role": "system", "content": "以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。"},
{"role": "user", "content": "自然言語処理とは何か"},
]
tokenized_input = tokenizer.apply_chat_template(
chat,
add_generation_prompt=True,
tokenize=True,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
repetition_penalty=1.05,
pad_token_id=tokenizer.pad_token_id # この行を追加
)[0]
print(tokenizer.decode(output))
print(datetime.datetime.now()) # 完了時間修正内容は下記の通り
・token_idに関するエラーの対処
・処理時間測定を追加
・モデルをコメントアウトで切り替えられるように変更
モデル名はHuggingFaceから拾ってくることも可能です。(赤枠をクリック)

コードの実行
最も小さい1.8bで試したところ下記のようになりました。
出力結果は毎回変わります。
(myenv) $ python3 llm-test.py
2025-01-01 16:34:25.082106
<s> 以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。
### 指示:
自然言語処理とは何か
### 応答:
自然言語処理(Natural Language Processing, NLP)は、人間の言葉(自然言語)をコンピュータが理解、解釈、生成できる能力を研究す る分野です。NLPの目的は、コンピュータが人間と自然な形でコミュニケーションを取り、情報を取得したり処理したりできるようにすることです。
NLPの主な目標は、以下のようなものがあります:
1. 言語理解: テキストや音声を解析し、意味や意図を抽出すること。
2. 言語生成: 新しい言語を生成すること。
2025-01-01 16:34:32.266641文章が短いのは 「max_new_tokens=100」により、出力token数の最大が100のためです。※tokenは単語や文字のことです。
また、1回目の実行はLLMのダウンロードから始まるため処理に数分~数時間かります。2回目以降はダウンロード済みのモデルを利用するので数秒程度の読込時間で済みます。
この文章の確からしさの評価もいずれしていきますが、今回は割愛します。
実行結果まとめ
パラメータ数と処理時間の表
文章の精度の確認は割愛します。
今回は処理時間に関して整理しました。
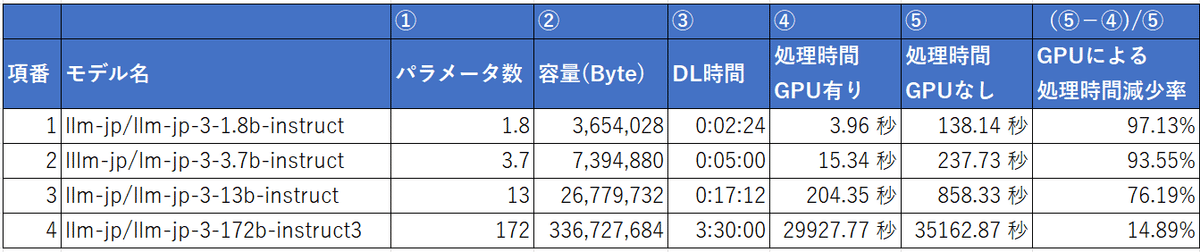
※容量は「~/.cache/huggingface/hub/」内のファイルサイズを基に算出
1回目の実行のDL時間
初回のみかかる時間なのであまり意識する必要はないですが、172bは3時間半かかるため、寝る前や出かける前に処理を走らせる等、注意が必要です。
処理時間について
パラメータ数が大きいほどもちろん時間がかかるのですが、パラメータ数が大きいほど、パラメータ数の割に時間がかかるようになっていきます。
(GPU有りだと、概ね1.2×①^2の時間がかかっていますが、サンプル数4なので何とも言えないです。おそらく偶々かと)
GPU有無について
GPU有無で処理時間が大きく変わることが分かります。
パラメータ数が小さいほど高速化されています。理由はわかりませんがスワッピング有無と予想しています。
おわりに
とりあえず動かすことはできました。
今後の予定としては下記をしていきたいと思います。
・CPU/メモリ、GPU/VRAMの利用状況の確認
・今回使ったコードの理解
・パラメータのチューニング
・RAG
・UIの改善(webUIにしたい)
・他のLLMを試す
・AI同士を対話させてみる