
結局コピー機学習ってなんなの?

コピー機という言葉がひとり歩きしている気がするので、ふわっとした理解の人間がふわっとした表現で書きます。
嘘を書くつもりはないですが、正確性を欠く可能性はあるので、大目に見てください。
通常のLoRAにおける"差分"
胸のサイズを小さくするLoRAを作成すると仮定する。
この場合、「胸のサイズが小さい絵」を素材として用意して学習させることになる。
よくあるパターンとして、キャラクターのみを切り抜いて背景を白にした素材を用意したとする。
キャプショニング(タグ付け)は「1girl, solo, white background」とする。
この条件で学習を行うとざっくり言って下記のようになる。
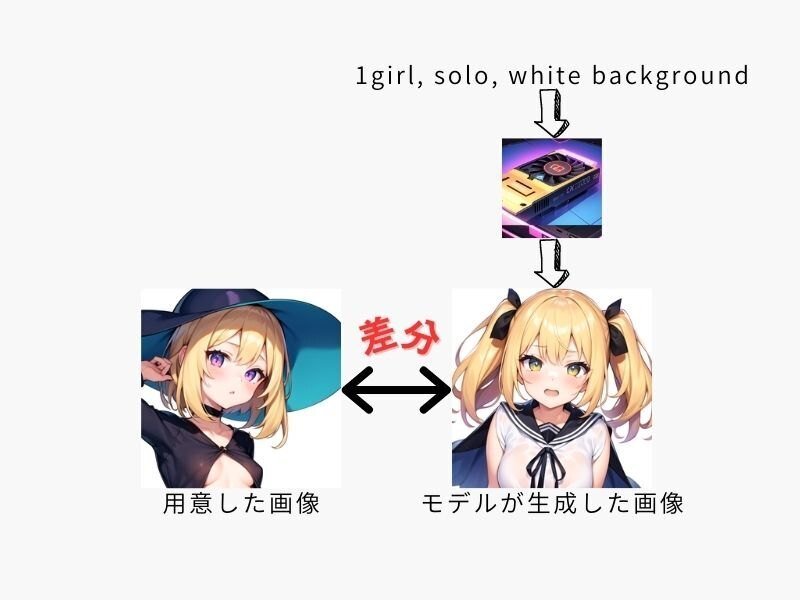
この差分を集めたものが学習内容になる。
すぐに気づくと思うが、一つだけ見ると「胸が小さい」以外にも多くの"差分"(髪型、服、目の色、etc…)があり、胸を小さくするという目的が果たせないように見える。
それでも物量(素材数という意味だけでなくステップ数の意味でもある)で押せば「胸が小さい」という差分が発生した回数が多くなって、胸を小さくするLoRAになる(実際には他の影響も出てしまうので胸のサイズ"だけ"を変更するLoRAを作ることは困難)
モデルの出力を制限する
コピー機という表現にそもそも幅があるのだが、目的はモデルの出力を制限することにある。
以下、実例を用いて説明する。
どんなPromptを入力しても同じ絵を出力するモデルであれば先程の図解は下記のようになる。

ここまで来るとどう考えても"差分"は「頭のサイズが小さい」しかありえんだろ!となって、すんなり学習してくれるという話である(実はライティングの問題で影に差異があるのだが一旦棚上げする)
どんなPromptを入力しても同じ画像になるのでキャプショニングも不要。
要するにモデルの出力を制限することで、"差分"を意図したものに限定できることがコピー機学習と呼ばれるもののメリットである。
「特定部位のサイズ変更」のような使い方であれば完全に1種しか出ないモデル、ないし、画角だけバリエーションが出る程度のモデルが良いだろう。
その他にも「特定の画風しか出ない」モデルを作ることで、当該画風のキャラクターを画風の影響無しに学習させるのような使い方もある。
このあたりは過去の記事で書いたのでここでは割愛する。
というか、そもそもはKohya氏が1月時点で示唆している内容なんですよね、やはり格が違う。
アニメのスタイルをfine tuneしたモデルを元に、「学ばせたいキャラを学習用画像」に「それ以外のキャラを正則化画像」にしてLoRAを学習すれば、画風から独立したキャラの特徴だけ学べるかな、と思ったんだけどどうもうまく行かなかった(;・∀・)
— Kohya Tech (@kohya_tech) January 25, 2023
以上、ふわふわ解説でした。おわり。