
Colaboratory+janome+wordcloudでテキストマイニングしてみる

テキストマイニングとは?
テキストマイニングとは、テキストデータから必要な情報を抽出することの総称です。
テキストマイニングで有名なサービスだとユーザーローカルがあります。
直接フォームに入力したり、ファイルをアップロードしたりすると、簡単にワードクラウドを作ってくれます。
ただ、ユーザー登録しないと10,000語の上限があります。
調子に乗って使っていると上限に達してしまいました。
Pythonライブラリを使ってテキストマイニング
Pythonのライブラリを使って自分でできないだろうかと思って調べてみると、janomeとwordcloudでできることがわかりました。
職場の校務系ネットワークではアプリの使用に制限があるので、Pythonのインストールは難しいです。
Google Colaboratoryでテキストマイニングすることができれば、校務系でも生徒系でも使えるので、その方法を探ってみました。
まずは本家のページを見ました。
順番に実行していきました。
janomeのインストール
pip install janome
#実行結果
Collecting janome
Downloading Janome-0.5.0-py2.py3-none-any.whl (19.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 19.7/19.7 MB 62.1 MB/s eta 0:00:00
Installing collected packages: janome
Successfully installed janome-0.5.0documentation通りに例を実行してみます。
from janome.tokenizer import Tokenizer
t = Tokenizer()
for token in t.tokenize('すもももももももものうち'):
print(token)
#実行結果
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ問題無いですね。
wordcloudのインストール
次にwordcloudのインストールです。
神戸学院大学 経営学部 林坂ゼミのページを参考に進めてみました。
pip install wordcloud
#実行結果
Requirement already satisfied: wordcloud in /usr/local/lib/python3.10/dist-packages (1.9.2)
Requirement already satisfied: numpy>=1.6.1 in /usr/local/lib/python3.10/dist-packages (from wordcloud) (1.23.5)
Requirement already satisfied: pillow in /usr/local/lib/python3.10/dist-packages (from wordcloud) (9.4.0)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.10/dist-packages (from wordcloud) (3.7.1)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->wordcloud) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib->wordcloud) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->wordcloud) (4.44.3)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->wordcloud) (1.4.5)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->wordcloud) (23.2)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->wordcloud) (3.1.1)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib->wordcloud) (2.8.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib->wordcloud) (1.16.0)
実はwordcloudはColaboratoryで準備されていました。
日本語フォントのインストール
ワードクラウドを表示させるには、日本語フォントが必要になります。
ローカルマシンなら本体にすでにインストールされているフォントの場所を指定すればいいのですが、Colaboratoryでは本体の日本語フォントを使うことができないので、Colaboratory上に日本語フォントのインストールが必要です。
!apt -y install fonts-ipafont-gothic
#実行結果
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:
fonts-ipafont-mincho
The following NEW packages will be installed:
fonts-ipafont-gothic fonts-ipafont-mincho
0 upgraded, 2 newly installed, 0 to remove and 11 not upgraded.
Need to get 8,237 kB of archives.
After this operation, 28.7 MB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu jammy/universe amd64 fonts-ipafont-gothic all 00303-21ubuntu1 [3,513 kB]
Ign:1 http://archive.ubuntu.com/ubuntu jammy/universe amd64 fonts-ipafont-gothic all 00303-21ubuntu1
Get:2 http://archive.ubuntu.com/ubuntu jammy/universe amd64 fonts-ipafont-mincho all 00303-21ubuntu1 [4,724 kB]
Get:1 http://archive.ubuntu.com/ubuntu jammy/universe amd64 fonts-ipafont-gothic all 00303-21ubuntu1 [3,513 kB]
Fetched 7,735 kB in 13s (575 kB/s)
Selecting previously unselected package fonts-ipafont-gothic.
(Reading database ... 120880 files and directories currently installed.)
Preparing to unpack .../fonts-ipafont-gothic_00303-21ubuntu1_all.deb ...
Unpacking fonts-ipafont-gothic (00303-21ubuntu1) ...
Selecting previously unselected package fonts-ipafont-mincho.
Preparing to unpack .../fonts-ipafont-mincho_00303-21ubuntu1_all.deb ...
Unpacking fonts-ipafont-mincho (00303-21ubuntu1) ...
Setting up fonts-ipafont-mincho (00303-21ubuntu1) ...
update-alternatives: using /usr/share/fonts/opentype/ipafont-mincho/ipam.ttf to provide /usr/share/fonts/truetype/fonts-japanese-mincho.ttf (fonts-japanese-mincho.ttf) in auto mode
Setting up fonts-ipafont-gothic (00303-21ubuntu1) ...
update-alternatives: using /usr/share/fonts/opentype/ipafont-gothic/ipag.ttf to provide /usr/share/fonts/truetype/fonts-japanese-gothic.ttf (fonts-japanese-gothic.ttf) in auto mode
Processing triggers for fontconfig (2.13.1-4.2ubuntu5) ...最初、これを忘れて日本語が表示されませんでした。
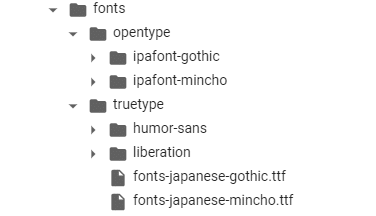
インストールされると
/usr/share/fonts/
に明朝体とゴシック体が現れます。
分析するテキストファイルのアップロード
分析するテキストデータとして、私のnoteの記事をメモ帳に貼り付け、txtファイルで保存しました。
ファイル名は「sample.txt」としました。
「content」→「sample_data」フォルダを右クリックし、アップロードを選択します。
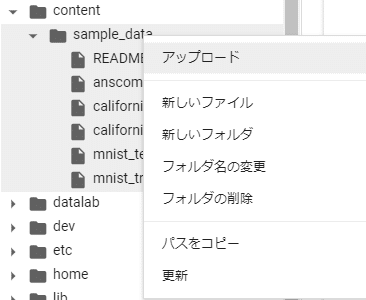
ファイルを指定すると、sample_dataフォルダにアップロードされます。

ワードクラウドの作成
林坂ゼミの「成功例」のソースコードを参考に、「テキストファイルの場所」と「フォントファイルの場所」を指定します。
このように書き換えました。
from wordcloud import WordCloud
import os
import re
from janome.tokenizer import Tokenizer
def strip_CRLF_from_Text(text):
plaintext = re.sub('([ぁ-んー]+|[ァ-ンー]+|[\\u4e00-\\u9FFF]+|[ぁ-んァ-ンー\\u4e00-\\u9FFF]+)(\n)([ぁ-んー]+|[ァ-ンー]+|[\\u4e00-\\u9FFF]+|[ぁ-んァ-ンー\\u4e00-\\u9FFF]+)',
r'\1\3',
text)
plaintext = plaintext.replace('\n', ' ').replace('\t', ' ')
return plaintext
def janome_wakati(text):
t = Tokenizer()
results = t.tokenize(text, wakati=False)
sent = ""
for token in results:
if token.part_of_speech.split(',')[0] in ["名詞"]:
sent += token.surface + " " # 表層形
return sent
#テキストファイルの場所指定
f = open(os.path.sep.join(['sample_data', 'sample.txt']), encoding='utf-8')
raw = f.read()
f.close()
print(raw)
text = strip_CRLF_from_Text(raw)
print(text)
sent = janome_wakati(text)
print(sent)
# フォントの保存先を指定する
font_path = "/usr/share/fonts/truetype/fonts-japanese-gothic.ttf"
wc = WordCloud(max_font_size=36, font_path=font_path).generate(sent)
wc.to_file("wc.png")書き換えたのは3か所。
1.テキストファイルの場所は
/content/sample_data/sample.txt
にしたので、
f = open(os.path.sep.join(['sample_data', 'sample.txt']), encoding='utf-8')
に書き換え。
2.フォントの保存先は
/usr/share/fonts/truetype/fonts-japanese-gothic.ttf
なので、
font_path = "/usr/share/fonts/truetype/fonts-japanese-gothic.ttf"
に書き換え。
3.ワードクラウドのファイル名をwc.pngとしました。
実行すると、contentフォルダにワードクラウドのファイルが作成されます。
wc.pngがそのファイルです(トイレではありません)。
wc.pngをダウンロードして開いてみると・・・

おお、できていますね。
画像サイズ、最大フォントサイズの変更
縦横の大きさを設定しないと400×200ピクセルなので、拡大するとジャギーが目立ちます。
横幅はwidth、立幅はheightで設定できます。
フォントサイズもmax_font_sizeで設定できるので大きくしてみます。
from wordcloud import WordCloud
import os
import re
from janome.tokenizer import Tokenizer
def strip_CRLF_from_Text(text):
plaintext = re.sub('([ぁ-んー]+|[ァ-ンー]+|[\\u4e00-\\u9FFF]+|[ぁ-んァ-ンー\\u4e00-\\u9FFF]+)(\n)([ぁ-んー]+|[ァ-ンー]+|[\\u4e00-\\u9FFF]+|[ぁ-んァ-ンー\\u4e00-\\u9FFF]+)',
r'\1\3',
text)
plaintext = plaintext.replace('\n', ' ').replace('\t', ' ')
return plaintext
def janome_wakati(text):
t = Tokenizer()
results = t.tokenize(text, wakati=False)
sent = ""
for token in results:
if token.part_of_speech.split(',')[0] in ["名詞"]:
sent += token.surface + " " # 表層形
return sent
#テキストファイルの場所指定
f = open(os.path.sep.join(['sample_data', 'sample.txt']), encoding='utf-8')
raw = f.read()
f.close()
print(raw)
text = strip_CRLF_from_Text(raw)
print(text)
sent = janome_wakati(text)
print(sent)
# フォントの保存先を指定する(環境によって書き換えてください)
font_path = "/usr/share/fonts/truetype/fonts-japanese-gothic.ttf"
wc = WordCloud(max_font_size=200, font_path=font_path, width = 1920, height = 1080).generate(sent)
wc.to_file("wc.png")最後から2行目を
wc = WordCloud(max_font_size=200, font_path=font_path, width = 1920, height = 1080).generate(sent)
に書き換えました。
実行すると・・・

これならスライドに貼り付けても大丈夫です。
処理には9秒かかりました。
ここからさらに分析する品詞の種類や長さなどを調整していくのですが、最低ここまでできれば、とりあえず容量を気にせず試しまくることはできるかなと思います。
生徒が授業後に書いているリフレクションや、調査の記述式解答などを分析してみようかなと思っています。