
【R言語】多群比較パラメトリックの場合の効果量の計算コードを書く

こんにちは。Rで統計の勉強もしつつプログラミングの勉強もしている、生命科学系研究者のえいこです。
今回は現在書いている多群比較用のコードに、「パラメトリックの場合の効果量の計算コードを書いていく」をしていきたいと思います。
多群比較の場合、効果量の計算はどうなるのか調べたところ確率論ではないので何回計算しても同じ。つまり単一の計算式で計算していくという結論を得ました。
(もしかしたら私の理解が間違っているかもしれないので、専門家の先生が見ていらっしゃったらご指摘いただけると嬉しいです。)
多群検定の時の効果量の計算方法について検討した記事はこちら。
今回はこんな流れでコードを書いていきます
①パラメトリック検定の場合の効果量rを計算するコードを書く
② for文で全ての組み合わせについて効果量を計算する
—————
パラメトリック検定の場合の効果量rを計算するコードを書く
前回検討した結果、t値を取得して下の計算式に当てはめるのが良いという結論に達しました。

さて、Rでどう効果量の計算を書いていくかですが、二群検定の時と全く同じということでこちらの記事を参考にします。
コードをまとめると...
#t検定をする(Welchのt検定)
ttest<-t.test(data$value ~ data$treatment) #二群データの比較
#t値と自由度の値を取り出す
t<-ttest$statistic
df<- ttest$parameter
#値だけに変更
t<-unname(ttest$statistic)
df<- unname(ttest$parameter)
#効果量を計算する
t.effect<- sqrt(t^2/(t^2+df))今回の多群比較の場合は、data.frameにすべての群のデータが入っているので工夫が必要です。(後程for文を回せるように工夫する)
そこで、考えたのが、
元dataのうち、orderでfilterを書けた新しいdata.frameを二つ作る
↓
二つのdata.frameからそれぞれデータを取り出してt検定
↓
効果量の計算
もとの"data"の形はこんな感じです。
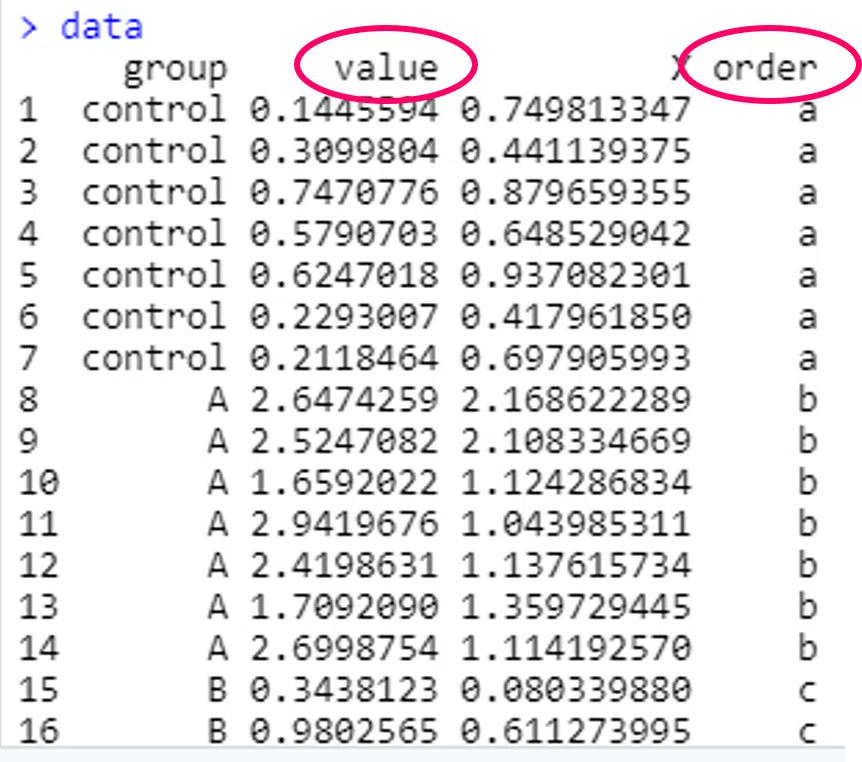
丸で囲んだorderの"a"だけのdata.frameをdplyrの"filter関数"で作っていきます。
split<- strsplit(as.character(df$comparison),":")
d1<- filter (data, order == split[[1]][1])strsplit関数の使い方はこちらの記事で紹介しています。dfは検定結果を格納しているdata.frameです。
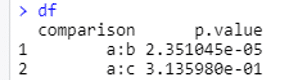
d1を実行すると...

同じようにorderの"b"だけのdata.frameを作ります。
d2<- filter (data, order == split[[1]][2])d1とd2それぞれのdata.frameからvalueを取り出して、t検定をして効果量を算出します。
t<- unname(t.test(d1$value, d2$value)$statistic)
f<- unname(t.test(d1$value, d2$value)$parameter)
r.p<- c(r.p, sqrt(t^2/(t^2+f)))これで、基本のコードが完成しました。
for文でdata.frameを作るのはスマートなやり方かどうかはわかりませんが、とりあえずできたので次に進みます。
for文で全ての組み合わせについて効果量を計算する
できたコードをfor文の中に入れていきます。
効果量を比較するのは”df”の行数と一緒なので、nrow(df)を使います。
あとは、作ったコードをiに変えるべきところは変えて書いていくだけ。
r.p<- c()
for (i in 1:nrow(df)){
d1<- filter (data, order == split[[i]][1])
d2<- filter (data, order == split[[i]][2])
t<- unname(t.test(d1$value, d2$value)$statistic)
f<- unname(t.test(d1$value, d2$value)$parameter)
r.p<- c(r.p, sqrt(t^2/(t^2+f)))
}これで、完成です!
元のデータで回してみると...

できました。
次は、ノンパラメトリック検定の場合のコードを書いていこうと思います。
それでは、また!
いいなと思ったら応援しよう!
