パワークエリで、特定のフォルダ配下、ファイル、シート名の全シートを結合して読み込む方法

はじめに
以下のような複数フォルダに格納されている複数ファイルのテーブルを結合して読み込む方法を紹介します。
フォルダ名やファイル名に、除外ワード("対象外")がある場合は読み込み対象外とします。

さらに各ファイルには複数シートが存在し、読み込み対象のシートも複数あります。DataXXXという名前のシートが読み込み対象で、はじめにシートや、対象外XXXといったシート名は読み込み対象外とします。

手順
まずは新しいソースから、フォルダを指定してクエリに読み込みます。

冒頭で示したフォルダのルートフォルダ(”データ”フォルダ)を指定すると、以下のダイアログが表示されるので、「編集」を押して読み込みます。

すると、以下のようにフォルダ配下のファイル全てがパワークエリに読み込まれます。

次にフォルダ名やファイル名に除外ワードが含まれている行を、パワークエリのフィルタ機能で除外します。
まずはフォルダ名から除外します。以下のようにフォルダパス名の列の▼ボタンからフィルタ指定ダイアログを出します。ダイアログから、「指定の値を含まない」を選択します。ここでその他の選択肢を使用することで、様々な除外ルールを適用できそうです。

”対象外”と記入します。

フォルダ名に除外ワードを含む行がフィルタされました。

ファイル名の方も同様の手順で除外ワードを含むものをフィルタします。

除外ファイルもフィルタできました。

次に、上で読み込んだ各エクセルファイルのシート一覧をクエリに読み込みます。まずはエクセルファイルからシート一覧を取得する関数を作成します。
パワークエリで空のクエリを作成し、以下のコードを詳細エディタに記載することで、この関数が作成できます。
(エクセルファイル) =>
let
ソース = Excel.Workbook(エクセルファイル, null, true)
in
ソースパワークエリ画面では以下のように関数が定義されます。

最初に読み込んだクエリに戻り、カスタム関数の呼び出しをクリックし、先ほど作成した関数を指定します。関数の引数(図中の”エクセルファイル”の欄)には、エクセルファイル自体を表す「Contents」列を指定します。

列が追加されました。

以下のボタンを押して、追加された列を展開します。

すると、各ファイルにシート名の一覧(図中”Name”)と、各シートのデータが「Data」列に読み込まれます。

Name列のシート名の内、”DataXXXX”(Xは数値)というルールに従うシートのみを読み込み対象とするため、このルールでフィルタします。
まずはDataで始まる行のみにフィルタします。
以降Name列の内容を加工する操作をしていくため、まずはName列を複製します。

複製したら、その列に対し、Dataで始まる行のみにフィルタします。

フィルタされました。

Dataの後ろは数値というルールのため、Dataとそれ以降に列を分割します。


分割されました。
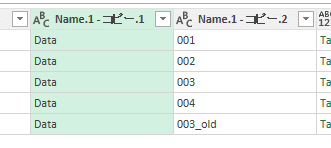
右側の列が数値かどうか確認します。右側の列を選択して、以下をクリックします。

一番下の行は数値ではない文字列(”_old”)が含まれていたので、Errorになりました。
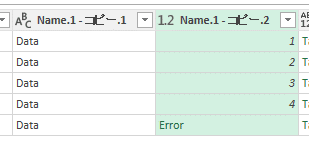
このErrorをダミーの数値に変換します。

ここでは-1としておきます。

以下のように-1に置換されました。
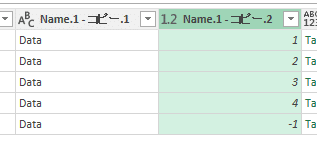
あとはこの列が正の値のもののみでフィルタすれば、読み込み対象のシートのみの選択が完了します。手順はこれまでと同様のため割愛します。
結果、読み込み対象のシートのみにフィルタできました。

パワークエリでは正規表現はサポートされていないようです。
ただ、上記のように、フィルタ機能やメニューバーの各機能(型の変換、列の分割、書式、抽出、解析など)を駆使することにより、それなりに高度なフィルタは可能と思います。
各シートのテーブルを展開して結合します。

下のようにテーブル情報(Column1~3の部分)が展開されます。

しかし、各シートの見出しの行(上図でいうA、B、Cと書かれている各行)まで結合されています。
見出し行を除去していきます。
まず、列の削除を使い、ファイル名とシート名を表す列とテーブル情報(Column1~3の部分)だけを残します。以下は削除後です。

各シート(図中のData001などの単位)ごとのテーブルに1始まりの連番を付与し、連番が1の行のみを削除すれば、見出し行の除去はできそうです。ただ、シート名は異なるファイル名でも重複することを考慮し、ファイル名とシート名の組み合わせで、テーブル情報(Column1~3の部分)をグルーピングすることを考えます。
具体的な操作は、以下です。Name(ファイル名)、Name.1(シート名)の列を選択し、グループ化をクリック。その後ダイアログに以下のように指定してOKをクリックします。

下図のようにテーブル情報(Column1~3の部分)がファイル名&シート名の組み合わせごとにグルーピングされ、グルーピング列の各Tableとして格納されました。一番上のTableをクリックすると、図中下段にそのテーブルの内容が表示されます。

次に各グルーピングされたテーブルごとにインデックスを付与します。
具体的にはカスタム列の追加してダイアログに、以下のように記載します。
Table.AddIndexColumn([グルーピング], "index", 1, 1)
上記は、グルーピング列をAddIndexColumn()関数の引数に指定することにより、この列の各テーブルごとにIndex列を追加するという意味です。結果のイメージは以下のとおり。

改めて上の「インデックス付与テーブル」列を展開します。以下のように展開され、期待通りシートごとにグルーピングされたテーブルごとに1始まりの連番が付与されました。

テーブル情報(Column1~3の部分)とIndex以外の列を削除します。

1行目をヘッダーとして使用します。

下のようになります。

1番右の列名が1になってしまいましたが、この列を1以外でフィルタします。

見出し行のみが除去できました。

仕上げに1番右の列を削除して完成です。
