
「回帰分析から学ぶ計量経済学」をPythonで写経 ~ 第4章「変数の工夫」③チャウテスト、課題

第4章「変数の工夫」
書籍の著者 山澤成康 先生
この記事は、書籍「回帰分析から学ぶ計量経済学」第4章「変数の工夫」の Python写経活動 を取り扱います。
今回は第4章の残りを実践します!
具体的にはチャウテストと2つの課題に取り組みます!
では書籍を開いて回帰分析の旅に出発です🚀

はじめに
書籍「回帰分析から学ぶ計量経済学」のご紹介
このシリーズは書籍「回帰分析から学ぶ計量経済学: Excelで読み解く経済のしくみ」(オーム社、「テキスト」と呼びます)の Python 写経です。
テキストは、2023年11月に発売され、副題「Excelで読み解く経済のしくみ」のとおり、主に Excel を用いて、計量経済学を平易に学べる素晴らしい書籍です。
テキストの「はじめに」に著者の先生が執筆の動機を書かれています。
社会人の統計リテラシーの向上をテーマの1つとした科研費プロジェクトの最終年度で、広く社会人に向けてわかりやすい経済分析の本を書きたかったのです。
私にとって計量経済学は高嶺の花ですが、このテキストでさまざまな回帰分析のアプローチを知ることができました。
また、書籍の Excel 処理を Python に置き換える「寄り道写経」の実践を通じて、回帰分析のお気持ちに少し近づけた感じがいたします。
回帰分析に慣れ親しむのに丁度良いレベル感と内容ですので、これはぜひともブログにしたい!と思って現在に至ります。
計量経済学の色を薄め、データ分析の色を濃いめに書いてまいります!

引用表記
この記事は、出典に記載の書籍に掲載された文章と配布データを引用し、適宜、掲載文章・配布データを改変して書いています。
【出典】
「回帰分析から学ぶ計量経済学: Excelで読み解く経済のしくみ」
第1版第1刷、著者 山澤成康、オーム社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
第4章 変数の工夫
この記事は第4章の以下の節を取り扱います。
Column チャウテストの実例
課題1 多重共線性
課題2 賃金の推定
記事に用いるデータは、オーム社の書籍紹介サイトからダウンロードできる Excel ファイル内のデータをもとにしてCSVファイルを作成し、data フォルダに格納しています。
第4章で用いるライブラリをインポートします。
### インポート
# 数値計算
import numpy as np
import pandas as pd
# 統計処理
import scipy.stats as stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.stats.api import het_white # ホワイトの検定
from statsmodels.stats.outliers_influence import variance_inflation_factor # VIF
import lmdiag # 残差プロット
# 描画
import matplotlib.pyplot as plt
from matplotlib.ticker import PercentFormatter # 軸目盛りを%表示
import seaborn as sns
import japanize_matplotlib
# ワーニング非表示
import warnings
warnings.simplefilter('ignore')
Column チャウテストの実例
■ チャウテストの概要 p.144
前々回の4.2節で構造変化を取り扱いました。
(前々回の記事はこちらのリンクからご覧いただけます)
チャウテストは「構造変化があったかどうかの検定」です。
帰無仮説は「係数制約がある(2期間の係数が等しい)」です。
ざっくり「帰無仮説:構造変化はない」です。
テキストの「係数制約」という言葉について探ると・・・
比較する2期間の係数が等しい
⇒ 係数が変わらないという制約がある =「係数制約がある」
⇒ 構造変化はない
検定の方法は・・・
1. 比較する2期間を別々に残差平方和を算出して合算(係数制約なし)
2. 比較する2期間を一緒に残差平方和を算出(係数制約あり)
3. 上記 1、2 を用いて$${F}$$検定を実行
$${F}$$値の算出式については、著者の先生のWebサイトから引用いたします。
ありがとうございます!
$$
F = \cfrac{(SSR_r - SSR) / q}{SSR / (n-p-q)}
$$
$${SSR}$$は係数制約なしの残差平方和(2期間の残差平方和の合計)、$${SSR_r}$$は係数制約ありの残差平方和、$${n}$$は標本サイズ、$${p}$$は係数制約なしモデルの定数項を含めた説明変数の数、$${q}$$は制約の数、です。
以降はテキストにならい、1955年度から2021年度までの実質GDPデータを用いて、1990年度に構造変化があったかどうかを確認します。
■ 実質GDPデータの読み込み p.144
4.2 節の実質GDPデータを読み込みます。
1955年度から2021年度までの実質GDPとトレンド変数のデータです。
### データの読み込み
# CSVファイルの読み込み
df7 = pd.read_csv('./data/04_07_chowtest.csv', index_col=0)
# トレンド項の追加
df7['トレンド'] = range(1, len(df7)+1)
# データフレームの表示
print('df7.shape:', df7.shape)
display(df7.head())【実行結果】
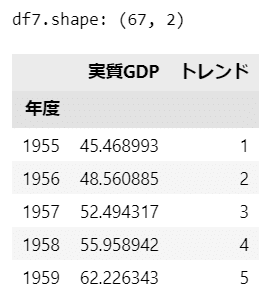
実質GDPデータを可視化しましょう。
1989年度までの期間と、1990年度以降の期間について、回帰直線付き散布図を描画します。
### データの可視化
# 描画領域の設定
plt.figure(figsize=(10, 4))
# ~1989年度の回帰直線付き散布図の描画
sns.regplot(data=df7.loc[:1990].reset_index(), x='年度', y='実質GDP',
scatter_kws={'s': 20, 'alpha': 0.5})
# 1990年度~の回帰直線付き散布図の描画
sns.regplot(data=df7.loc[1990:].reset_index(), x='年度', y='実質GDP',
scatter_kws={'s': 20, 'alpha': 0.5})
# 1990年度の垂直線の描画
plt.axvline(1990, color='tab:red', ls='--');【実行結果】
1990年度の垂直線より左側(青色)が1989年度までの期間の回帰直線付き散布図、右側(オレンジ色)が1990年度以降の期間の回帰直線付き散布図です。

1989年度までの期間に比べて、1990年度以降の期間は回帰直線の傾きは小さくなっている感じがします。
「比較する2期間の係数は変わっている」感じですが、チャウテストの結果はどうなるでしょう・・・?
■ チャウテストの実践 p.144
テキスト 144 ページの分散分析表と$${F}$$値の計算を行う関数を定義します。
チャウテストを行えるライブラリを探せなかったので、テキストの計算方法にならって関数を自作しています。
### チャウテスト実行関数の定義
def exec_chow_test(df, change_year, term_name_list, formula):
## 設定と準備
# 構造変化前、構造変化後を抽出したデータフレームの作成
df_before = df[df.index < change_year].copy()
df_after = df[df.index >= change_year].copy()
# 3つのデータフレームのリスト化
dfs = [df, df_before, df_after]
# 結果を格納するデータフレームの初期化
res_df = pd.DataFrame()
## 3つの期間ごとに回帰分析と分散分析を繰り返し処理
for i in range(len(dfs)):
# 回帰分析の実行
result = smf.ols(formula=formula, data=dfs[i]).fit()
# 分散分析の実行
anova = sm.stats.anova_lm(result)
# 残差の自由度と変動の取得
resid_df = (anova.loc['Residual', ['df', 'sum_sq']]
.rename(term_name_list[i]).to_frame().T)
# 結果を格納するデータフレームに残差の自由度・変動を追加
res_df = pd.concat([res_df, resid_df], axis=0)
## 結果を格納するデータフレームの最終化(列名の変更)
res_df.columns = ['自由度', '変動']
## F検定の実行
# 計算要素の算出
SSR = (res_df.iloc[1, 1] + res_df.iloc[2, 1]) # 係数制約なし2期間の変動合計
m2 = (res_df.iloc[1, 0] + res_df.iloc[2, 0]) # 係数制約なし2期間の自由度合計
SSR_r = res_df.iloc[0, 1] # 係数制約あり全期間の変動
m1 = 2 # 係数制約あり・なしの自由度
# F値の算出
F_val = ((SSR_r - SSR) / m1) / (SSR / m2)
# p値の算出
p_val = stats.f.sf(x=F_val, dfn=m1, dfd=m2)
# 結果のデータフレーム化
res_df2 = pd.DataFrame([[F_val, p_val]], index=[''], columns=['F値', 'p値'])
return res_df, res_df2では早速チャウテストを実行しましょう!
引数は「データ」「構造変化が起きた年度」「分散分析表に表示する文言」「回帰分析のフォーミュラ」です。
### chow testの実行
## 設定と準備
# 構造変化が起きた年度
change_year = 1990
# 行名(期間名)のリスト
terms = ['1955~2021年度', '1955~1989年度', '1990~2021年度']
# フォーミュラ式
formula = '実質GDP ~ トレンド'
## chow testの実行
res1, res2 = exec_chow_test(df7, change_year, terms, formula=formula)
## 結果表示
display(res1.round(3))
display(res2)【実行結果】
上の表が分散分析表の一部に相当します。
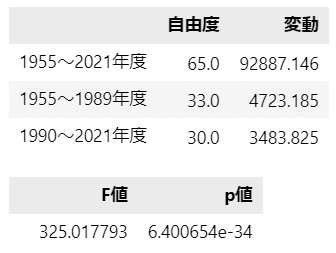
$${F}$$値=$${325.018}$$、$${p}$$値=$${0.000}$$(ほぼゼロ)です。
帰無仮説「係数制約がある(2期間の係数が等しい)」は棄却され、1990年度に構造変化があったと考えられます。
なお自由度と変動($${SSR, SSR_r}$$)を利用して$${F}$$値を算出できます。
$$
\begin{align*}
F &= \cfrac{(SSR_r - SSR) / q}{SSR / (n-p-q)} \\
&=\cfrac{(92887.146 - (4723.185+3483.825)) / 2}{(4723.185+3483.825) / (67 - 2 - 2)} \\
&= 325.017793 \cdots
\end{align*}
$$
$${p}$$:係数制約なしモデルの定数項を含めた説明変数の数は$${2}$$
$${q}$$:制約の数は、定数項とトレンド変数の係数の数$${2}$$
課題1 多重共線性
説明変数間に強い相関のある4.5節のデータを用いて、4つモデルを比較します。
データを読み込みます。
### データの読み込み
# CSVファイルの読み込み
df5 = pd.read_csv('./data/04_05_corr.csv', usecols=[0, 1, 2, 3])
# データフレームの表示
print('df5.shape:', df5.shape)
display(df5.head())【実行結果】

このデータは以下の式で算出されています。
切片の真値は$${1}$$、説明変数$${X_1, X_2, X_3}$$の係数の真値は$${0.5}$$です。
$$
Y_i = 1 + 0.5 X_{1i} + 0.5 X_{2i} + 0.5 X_{3i} + 誤差 \\
$$
相関係数を確認します。
# 相関行列
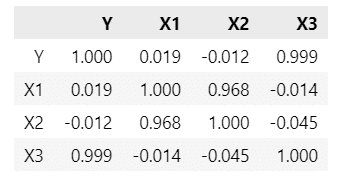
df5.corr().round(3)【実行結果】
$${X_1, X_2}$$の相関係数は$${0.968}$$であり強い相関関係があります。
$${X_3}$$と$${X_1, X_2}$$との間の相関は非常に弱いです。
◆ ◆ ◆
① $${Y=\alpha + \beta_1 \times X_1 + \beta_2 \times X_1}$$
### (1) Y = α + β1 X1 + β2 X1
# X1の係数の標準誤差が大きい, 同じ説明変数を与えるとstatsmodelsは1つを除外するみたい
result = smf.ols(formula='Y ~ X1 + X1', data=df5).fit()
display(result.summary())【実行結果】
説明変数$${X_1}$$が1つになっちゃいました!
係数は真値に近い$${0.5397}$$ですが、標準誤差はかなり大きな値$${4.193}$$になりました。
決定係数はなんと0!

◆ ◆ ◆
①’ $${Y=\alpha + \beta_1 \times X_1 + \beta_2 \times X_1}$$(別案)
$${X_1}$$と同じ値の別変数$${X_{1\_}}$$を作ってモデリングします。
### (1)Y = α + β1 X1 + β2 X1 ※X1と同じ値をX1_列に追加
# 係数・標準誤差が半分になった
# df5をコピーして、X1と同じ値のX1_列を追加
df5_mod = df5.copy()
df5_mod['X1_'] = df5_mod['X1']
# 回帰分析の実行
result = smf.ols(formula='Y ~ X1 + X1_', data=df5_mod).fit()
display(result.summary())【実行結果】
1つ前の結果と比べて、係数と標準誤差の値が半分ずつに分かれました。
標準誤差が大きい状況は変わっていません。
なお、脚注で「強い多重共線性」(strong multicollinearity problems)を警告されています。

◆ ◆ ◆
② $${Y = \alpha + \beta_1 \times X_1 + \beta_2 \times X_3}$$
### (2) Y = α + β1 X1 + β2 X3
# X1の係数の推定値は、X1の係数の真値0.5にX2の係数の真値0.5くわえた感じがする
result = smf.ols(formula='Y ~ X1 + X3', data=df5).fit()
display(result.summary())【実行結果】
$${X_3}$$の係数は真値に近く、標準誤差は小さな値となっています。
一方で$${X_1}$$の係数は$${X_1, X_2}$$の真値の合計に近くになっていて、標準誤差は先の①と比べると小さくなっています。
脚注の多重共線性アラートは発令中です。
そして決定係数はなんと1!

◆ ◆ ◆
③ $${Y = \alpha + \beta_1 \times X_2 + \beta_2 \times X_3}$$
### (3) Y = α + β1 X2 + β2 X3
# X2の係数の推定値は、X2の係数の真値0.5にX1の係数の真値0.5くわえた感じがする
result = smf.ols(formula='Y ~ X2 + X3', data=df5).fit()
display(result.summary())【実行結果】
$${X_2}$$の係数は$${X_1, X_2}$$の真値の合計に近くになっています。
先の②の$${X_1}$$と似た立ち位置、でしょうか。
なお脚注の多重共線性アラートは発令中であり、決定係数は1です。

◆ ◆ ◆
④ $${Y = \alpha + \beta_1 \times (X_1 + X_2) + \beta_2 \times X_3}$$
### (4) Y = α + β1(X1 + X2) + β2 X3
# (X1 + X2)の係数β1の推定値は真値0.5に近似し、標準誤差も小さい
result = smf.ols(formula='Y ~ I(X1 + X2) + X3', data=df5).fit()
display(result.summary())【実行結果】
$${X_1 + X_2}$$の係数が真値に近い$${0.4863}$$となり、標準誤差も①~③の中で最小値になりました。
なお脚注の多重共線性アラートは発令中であり、決定係数は1です。

課題2 賃金の推定
賃金データを読み込みます。
厚生労働省「賃金構造基本調査」の2020年調査の月所定内給与(単位:千円)データです。
### データの読み込み
# CSVファイルの読み込み
df8 = pd.read_csv('./data/04_ex2_wage.csv')
# データフレームの表示
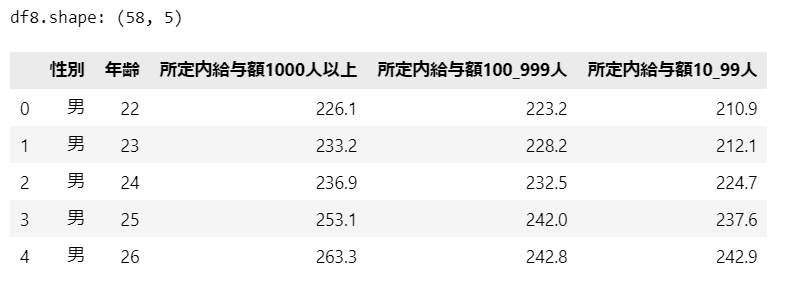
print('df8.shape:', df8.shape)
display(df8.head())【実行結果】
性別・年齢別の大企業・中企業・小企業の58件のデータです。
データの前処理を実行します。
性別と企業規模のダミー変数を作成します。
併せて横並びの企業規模を縦持ちに変換します。
### 前処理
# 列名の変更
df8 = df8.rename({'所定内給与額1000人以上': '大企業',
'所定内給与額100_999人': '中企業',
'所定内給与額10_99人': '小企業'}, axis=1)
# 女性ダミーの作成
df8['女性ダミー'] = np.where(df8['性別']=='女', 1, 0)
# 大企業・中企業・小企業の縦持ち化
df8 = df8.melt(id_vars=['性別', '女性ダミー', '年齢', ],
value_vars=['大企業', '中企業', '小企業'],
var_name='企業規模', value_name='所定内給与額')
# 大企業ダミー、中企業ダミーの作成
df8['大企業ダミー'] = np.where(df8['企業規模']=='大企業', 1, 0)
df8['中企業ダミー'] = np.where(df8['企業規模']=='中企業', 1, 0)
# 結果の表示
print('df8reg.shape: ', df8.shape)
display(df8)【実行結果】
58行から3つの企業規模を縦持ち化して174行になりました。
女性ダミーは 0:男性、1:女性です。
大企業ダミーは 0:中小企業、1:大企業、大企業ダミーは 0:大・小企業、1:中企業です。
小企業は大企業ダミー=0 かつ 中企業ダミー=0 です。

データを可視化しましょう。
最初に年齢・企業規模別の給与額の回帰直線付き散布図です。
### 可視化1 企業規模
sns.lmplot(data=df8, x='年齢', y='所定内給与額', height=4, aspect=1.2,
hue='企業規模', palette=['tab:blue', 'tomato', 'tab:green'],
scatter_kws={'alpha': 0.5})
plt.title('年齢別所定内給与額')
plt.ylim(0, 700)
plt.grid(lw=0.5)
plt.show()【実行結果】

年齢が増加するにつれて給与額が増加する傾向が見られます。
企業規模別に見ると、給与額の水準は大企業 > 中企業 > 小企業の順に大きく、かつ、昇給の度合い(回帰直線の傾き)は大企業 > 中企業 > 小企業の順に大きいと思われます。
続いて年齢・性別ごとの給与額の回帰直線付き散布図です。
### 可視化2 性別
sns.lmplot(data=df8, x='年齢', y='所定内給与額', height=4, aspect=1.2,
hue='女性ダミー', palette=['tab:blue', 'tomato'],
scatter_kws={'alpha': 0.5})
plt.title('年齢別所定内給与額')
plt.ylim(0, 700)
plt.grid(lw=0.5)
plt.show()【実行結果】
性別ごとに見ると、給与額の水準は男性 > 女性の順に大きく、かつ、昇給の度合い(回帰直線の傾き)は男性 > 女性の順に大きいと思われます。

回帰分析を実行します。
テキストの以下の式に従ってモデリングします。
$$
\begin{align*}
賃金 = &\alpha + \beta_1 \times 年齢 + \beta_2 \times 女性ダミー \\
&+ \beta_3 \times 大企業ダミー + \beta_4 \times 中企業ダミー \\
&+ \beta_5 \times 年齢 \times 女性ダミー + \beta_6 \times 年齢 \times 大企業ダミー \\
&+ \beta_7 \times 年齢 \times 中企業ダミー + u_i \\
\end{align*}
$$
### 回帰分析の実行
formula = '''
所定内給与額 ~ 年齢 + 女性ダミー + 大企業ダミー + 中企業ダミー + 年齢:女性ダミー
+ 年齢:大企業ダミー + 年齢:中企業ダミー
'''
result = smf.ols(formula=formula, data=df8).fit()
display(result.summary())【実行結果】

女性ダミーの係数が$${68.1}$$であり男性よりも女性の方が給与のベースが高いと思いきや、「年齢:女性ダミー」の係数は$${-3.3}$$とマイナスです。
21歳程度で$${68.1 - 3.3 \times 21}$$が0となり、以後、1歳増えるにつれて女性の給与は男性よりも$${3300}$$円ずつ低くなると読めます。
企業規模に目を向けると、1歳増えるにつれて、大企業は小企業よりも$${3700}$$円程度高く、中企業は小企業よりも$${1200}$$円程度高くなります。
大企業ダミー、中企業ダミーの係数は20歳程度でトントンになる感じです。
◆ ◆ ◆
ちなみに、フォーミュラ文はもっと簡略化して書けます。
$$
\begin{align*}
所定内給与額 = &年齢*女性ダミー + 年齢*大企業ダミー \\
&+ 年齢*中企業ダミー \\
\end{align*}
$$
### 回帰分析の実行
# formulaの参考例
# 「*」を用いることで女性ダミー・大企業ダミー・中企業ダミーを自動生成する
formula = '''
所定内給与額 ~ 年齢*女性ダミー + 年齢*大企業ダミー + 年齢*中企業ダミー
'''
result = smf.ols(formula=formula, data=df8).fit()
display(result.summary())【実行結果】

今回の写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。