
「数値シミュレーションで読み解く統計のしくみ」をPythonで写経 ~ 第3章3.3「乱数生成シミュレーションで確率分布を模倣する」

第3章「乱数生成シミュレーションの基礎」
書籍の著者 小杉考司 先生、紀ノ定保礼 先生、清水裕士 先生
この記事は、テキスト「数値シミュレーションで読み解く統計のしくみ」第3章「乱数生成シミュレーションの基礎」3.3節「乱数生成シミュレーションで確率分布を模倣する」の Python写経活動 を取り扱います。
今回はシミュレーションを通じて正規分布とつながりのある確率分布を確認します。
R の基本的なプログラム記法はざっくり Python の記法と近いです。
コードの文字の細部をなぞって、R と Python の両方に接近してみましょう!
ではテキストを開いて準備体操の旅に出発です🚀

はじめに
テキスト「数値シミュレーションで読み解く統計のしくみ」のご紹介
このシリーズは書籍「数値シミュレーションで読み解く統計のしくみ〜Rでためしてわかる心理統計」(技術評論社、「テキスト」と呼びます)の Python写経です。
テキストは、2023年9月に発売され、副題「Rでためしてわかる心理統計」のとおり、統計処理に定評のある R の具体的なコードを用いて、心理統計の理解に役立つ数値シミュレーションを実践する素晴らしい書籍です。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「数値シミュレーションで読み解く統計のしくみ〜Rでためしてわかる心理統計」初版第1刷、著者 小杉考司・紀ノ定保礼・清水裕士、技術評論社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
3.3 乱数生成シミュレーションで確率分布を模倣する
テキストのとおり、いくつかの確率分布から生成した「大量の乱数=シミュレーションによるヒストグラム」と「理論値から導いた正規分布の確率密度関数」が近似することを確認していきます。
この記事は Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
概ね確率分布の特性値算出には scipy.stats を用い、乱数生成には numpy.random.generator を用いるようにしています。
主に利用するライブラリをインポートします。
### インポート
# 数値計算
import numpy as np
# データフレーム
import pandas as pd
# 確率・統計
import scipy.stats as stats
# 描画
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'以前の記事で作成した関数を再利用します。
### 図3.5等の描画関数
def plot_std_normal(lower, upper, xmin=-5, xmax=5, ax=None):
## 設定
# 確率変数xの値(x軸の値)
xval = np.linspace(xmin, xmax, 1001)
# 積分範囲の確率変数xの値(x軸の値)
xval_draw = np.linspace(lower, upper, 1001)
# 標準正規分布オブジェクトの作成
std_norm = stats.norm(loc=0, scale=1)
## 描画処理
# 描画領域の設定
if ax == None:
ax = plt.subplot()
# 確率密度関数の描画
ax.plot(xval, std_norm.pdf(xval))
# 積分範囲の塗りつぶし
ax.fill_between(xval_draw, 0, std_norm.pdf(xval_draw), alpha=0.3)
# 積分範囲の下端の垂直線の描画
ax.vlines(lower, 0, std_norm.pdf(lower), linewidth=0.5)
# 積分範囲の上端の垂直線の描画
ax.vlines(upper, 0, std_norm.pdf(upper), linewidth=0.5)
# 積分範囲のx軸=0の水平線線の描画
ax.hlines(0, lower, upper, linewidth=0.5)
# 修飾
ax.set(xlabel='x', ylabel='density')
return ax
3.3.1 ベルヌーイ分布・二項分布
■ ベルヌーイ試行とシミュレーション
テキストの「モンテカルロ・シミュレーションを一度だけ実施」することをイメージする図3.17 を描画します。
### 91ページ 図3.17 ベルヌーイ分布に従う確率変数の例
## 描画領域の設定
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))
## 描画処理1
# 標準正規分布の確率密度関数の描画
plot_std_normal(-1.96, 1.96, ax=ax1)
# 長方形の描画
r = patches.Rectangle(xy=(-4, 0), width=8, height=0.4, ec='tab:red', fill=False)
ax1.add_patch(r)
# 乱数の散布図の描画
ax1.scatter([-2], [0.3], s=100, color='tomato', ec='tab:red', alpha=0.5)
ax1.set(xlabel='x', ylabel='density', title='$X=0$');
## 描画処理2
# 標準正規分布の確率密度関数の描画
plot_std_normal(-1.96, 1.96, ax=ax2)
# 長方形の描画
r = patches.Rectangle(xy=(-4, 0), width=8, height=0.4, ec='tab:red', fill=False)
ax2.add_patch(r)
# 乱数の散布図の描画
ax2.scatter([0], [0.1], s=100, color='tomato', ec='tab:red', alpha=0.5)
ax2.set(xlabel='x', ylabel='density', title='$X=1$');
plt.tight_layout();【実行結果】
乱数が青塗りの部分に該当する場合に確率変数$${X}$$の実現値が1となり(右側)、該当しない場合に$${X}$$の実現値が0(左側)になります。
ベルヌーイ分布の目覚めです。


■ 二項分布とシミュレーション
ベルヌーイ分布は試行回数1回でしたが、二項分布は複数回($${k}$$回)の試行回数に対応した分布です。
試行回数が2回の場合の成功回数$${X}$$のシミュレーションをテキストにならって描画します。
### 92ページ 図3.18 二項分布に従う確率変数の例
# 二項分布の2個の乱数データ
x_sets = [[-2, -2], [0, 3], [0, -1.5]]
y_sets = [[0.3, 0.2], [0.3, 0.25], [0.35, 0.05]]
# 描画領域の設定
fig, ax = plt.subplots(1, 3, figsize=(12, 3.5))
# 3つのケースを繰り返し描画
for i, (x_set, y_set) in enumerate(zip(x_sets, y_sets)):
# 標準正規分布の確率密度関数の描画
plot_std_normal(-1.96, 1.96, ax=ax[i])
# 長方形の描画
r = patches.Rectangle(xy=(-4, 0), width=8, height=0.4, ec='tab:red',
fill=False)
ax[i].add_patch(r)
# 乱数の散布図の描画
ax[i].scatter(x_set, y_set, s=100, color='tomato', ec='tab:red', alpha=0.5)
# 修飾
ax[i].set(xlabel='x', ylabel='density', title=f'$X=${i}');
# 全体修飾
plt.tight_layout();【実行結果】
青塗りの部分に該当する回数が成功回数です。

■ 二項分布と確率
試行回数$${k=2}$$、成功確率$${\theta=0.3}$$の二項分布に従う確率変数が取りうる値の確率を scipy.stats で計算します。
### 93ページ 二項分布の確率を算出
k = 2 # 試行回数
theta = 0.3 # 成功確率
# 引数nは試行回数k, 引数pは成功確率θに対応
stats.binom.pmf(k=range(0, k+1), n=k, p=theta)【実行結果】
左から成功回数$${X=0}$$の確率、$${X=1}$$の確率、$${X=2}$$の確率です。
成功回数0の確率が最も高いです。

シミュレーション発動です!
試行回数$${k=2}$$確率$${\theta=0.3}$$の二項分布に従う乱数を10000個生成して、成功回数$${X}$$のヒストグラムを描画します。
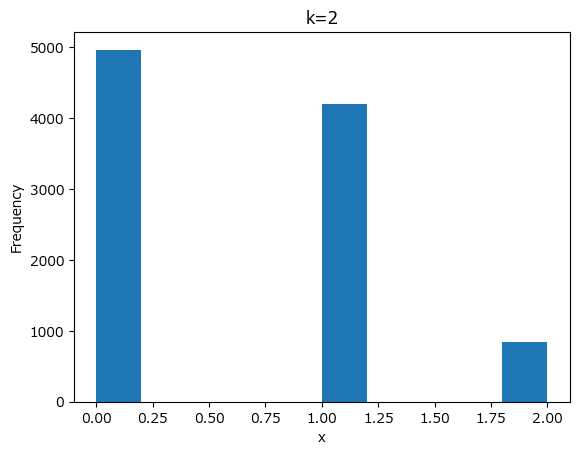
### 93ページ 二項分布乱数によるシミュレーション 図3.19
n = 10000 # 生成する二項分布に従う乱数の個数
k = 2 # ベルヌーイ試行の回数(試行回数)
theta = 0.3 # 成功確率
rng = np.random.default_rng(seed=123)
plt.hist(rng.binomial(size=n, n=k, p=theta))
plt.xlabel('x')
plt.ylabel('Frequency')
plt.title('k=2');【実行結果】
scipy.stats で算出した成功回数$${X=0, 1, 2}$$のときの確率と一致している感じがします!
■ 二項分布の試行回数を大きくすると正規分布に近似する
どんどんシミュレーションを繰り出します!
試行回数$${k}$$が$${5, 20, 50, 500}$$のときの二項分布から生成した10000個の乱数のヒストグラムを比べてみます。
二項分布から乱数を生成することは、二項分布の母集団から標本をランダムサンプリングすることと同じ感じです。
### 94ページ 二項分布乱数によるシミュレーション 図3.20
## パラメータの設定
n = 10000 # 生成する二項分布に従う乱数の個数
ks = [5, 20, 50, 500] # ベルヌーイ試行の回数(試行回数)
theta = 0.3 # 成功確率
rng = np.random.default_rng(seed=123) # 乱数生成器・乱数シード
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(2, 2, figsize=(10, 7))
# 4つの試行回数ケースごとに描画を繰り返し処理
for i, k in enumerate(ks):
# axesの位置を設定
pos = divmod(i, 2)
# 二項分布乱数のヒストグラムの描画
ax[pos].hist(rng.binomial(size=n, n=k, p=theta), bins=25, ec='white')
# 修飾
ax[pos].set(xlabel='x', ylabel='Frequency', title=f'k={k}')
plt.tight_layout();【実行結果】
試行回数$${k}$$の値が大きくなるにつれて、正規分布に近似する様子が確認できました。

試行回数$${k=2000}$$の場合の二項分布乱数のヒストグラムと、当該二項分布の平均・分散の理論値をパラメータにする正規分布の確率密度関数を重ねてみて、両者の一致を確認します。
### 94ページ 二項分布の正規分布近似シミュレーション 95ページ図3.21
## パラメータの設定
n = 10000 # 生成する二項分布に従う乱数の個数
k = 2000 # ベルヌーイ試行の回数(試行回数)
theta = 0.3 # 成功確率
mu = k * theta # 平均 μ
sigma = np.sqrt(k * theta * (1 - theta)) # 標準偏差 σ
## 乱数生成
rng = np.random.default_rng(seed=777) # 乱数生成器・乱数シード
rnd = rng.binomial(size=n, n=k, p=theta)
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 3))
# 乱数のヒストグラムの描画
ax.hist(rnd, bins=26, density=True, ec='white', alpha=0.7)
# 正規分布の形状を曲線で表す
line_x = np.linspace(rnd.min(), rnd.max(), 1001)
plt.plot(line_x, stats.norm.pdf(line_x, loc=mu, scale=sigma), linewidth=2,
color='tab:red')
# 修飾
ax.set(xlabel='x', ylabel='Density', title=f'k={k}')
plt.tight_layout();【実行結果】
二項分布乱数(標本)のヒストグラムと理論値から描いた正規分布の確率密度関数は、ほぼ一致しています。


3.3.2 χ²分布
テキストの定理・数式をお借りして$${\chi^2}$$分布を理解します。
互いに独立に標準正規分布に従う$${n}$$個の確率変数$${Z_1, \cdots, Z_n}$$の二乗和は、自由度$${n}$$の$${\chi^2}$$分布に従います。
$$
\displaystyle \sum_{i=1}^n Z_i^2 \sim \chi^2\ (n)
$$
■ 定理をシミュレーションする
互いに独立に標準正規分布に従う 10 個の確率変数の二乗の和 z2 を10000個の乱数で作成します。
z2 のヒストグラムが自由度 10 の$${\chi^2}$$分布に一致することを可視化します。
### 96ページ カイ二乗分布のシミュレーション 97ページ図3.22
## パラメータの設定
n = 10
iter = 10000
z2 = np.zeros(iter)
## 乱数の生成
rng = np.random.default_rng(seed=123)
for i in range(iter):
z2[i] = sum(rng.normal(size=n, loc=0, scale=1)**2)
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 3))
# 乱数のヒストグラムの描画
ax.hist(z2, bins=40, density=True, ec='white', alpha=0.7)
# カイ二乗分布の確率密度関数の描画
line_x = np.linspace(z2.min(), z2.max(), 1001)
plt.plot(line_x, stats.chi2.pdf(line_x, df=n, loc=0, scale=1), linewidth=2,
color='tab:red')
# 修飾
ax.set(xlabel='x', ylabel='Density', title=f'Histogram of z2\n自由度 $\\nu$={n}')
plt.tight_layout();【実行結果】
ほぼ一致しました。

■ $${\chi^2}$$分布の再生性シミュレーション
別々の$${\chi^2}$$分布に従う2つの確率変数の和に関する$${\chi^2}$$分布の再生性のシミュレーションを行います。
### 97ページ カイ二乗分布の再生性 98ページ図3.23
## パラメータの設定
nu_1 = 20 # 自由度1
nu_2 = 30 # 自由度2
n = 10000 # サンプルサイズ
## 乱数の生成
rng = np.random.default_rng(seed=123)
chisq_1 = rng.chisquare(size=n, df=nu_1)
chisq_2 = rng.chisquare(size=n, df=nu_2)
chisq_all = chisq_1 + chisq_2 # 2つのχ²分布に従う確率変数の和
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 3))
# 乱数のヒストグラムの描画
ax.hist(chisq_all, bins=40, density=True, ec='white', alpha=0.7)
# カイ二乗分布の確率密度関数の描画
line_x = np.linspace(chisq_all.min(), chisq_all.max(), 1001)
plt.plot(line_x, stats.chi2.pdf(line_x, df=nu_1 + nu_2, loc=0, scale=1),
linewidth=2, color='tab:red')
# 修飾
ax.set(xlabel='x', ylabel='Density', title='Histogram of chisq_all')
plt.tight_layout();【実行結果】
確率変数の和のヒストグラムと理論値に基づく$${\chi^2}$$分布の確率密度関数はほぼ一致しました!

■ さまざまな自由度の$${\chi^2}$$分布と正規分布の関係
$${\chi^2}$$分布の自由度が限りなく大きくなるとき、正規分布に近似します。
### 98ページ さまざまな自由度のχ²分布 99ページ図3.24
## 設定
# 自由度と線種
nus = [5, 10, 50]
linestyles = ['-', '--', ':']
# x軸の値の設定
line_x = np.linspace(0, 100, 1001)
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(8, 3))
# 3つの自由度ごとに描画を繰り返し処理
for (nu, linestyle) in zip(nus, linestyles):
# χ²分布の確率密度関数の描画
ax.plot(line_x, stats.chi2.pdf(line_x, df=nu), ls=linestyle,
label=rf'$\nu$={nu}')
# 修飾
ax.set(xlabel='x', ylabel='density')
ax.legend();【実行結果】
自由度 50 の$${\chi^2}$$分布(緑の点線)は左右対称の形状に近づき、正規分布に近似していく感じがいたします。


3.3.3 t分布
最初にt分布が正規分布にとても良く似ていることを示す描画から。
t分布と正規分布の確率密度関数を重ねて描画します。
### 99ページ 標準正規分布とt分布 100ページ図3.25
## x軸の値の設定
line_x = np.linspace(-8, 8, 1001)
## 描画処理
# 描画領域の設定
plt.figure(figsize=(8, 3))
# 太い実線:標準正規分布
plt.plot(line_x, stats.norm.pdf(line_x, loc=0, scale=1), lw=2,
label='Normal (0,1)')
# 細い実線:自由度ν=3のt分布
plt.plot(line_x, stats.t.pdf(line_x, df=3), lw=1, label='t (ν=3)')
# 破線:自由度ν=10のt分布
plt.plot(line_x, stats.t.pdf(line_x, df=10), ls='--', label='t (ν=10)')
# 修飾
plt.xlabel('x')
plt.ylabel('density')
plt.legend();【実行結果】
t分布の確率密度関数は正規分布の形状に良く似ています。

テキストの定理・数式をお借りしてt分布を理解します。
標準正規分布に従う確率変数$${Z}$$と、独立な自由度$${\nu}$$の$${\chi^2}$$分布に従う確率変数$${Y}$$で定義される比$${T=\frac{Z}{\sqrt{Y/\nu}}}$$は、自由度$${\nu}$$の$${t}$$分布に従います。
$$
\cfrac{Z}{\sqrt{\cfrac{Y}{\nu}}} \sim t\ (\nu)
$$
■ 定理をシミュレーションする
標準正規分布に従う 10000 個の乱数と自由度 4 の$${\chi^2}$$分布に従う 10000 個の乱数から確率変数$${T}$$を計算してヒストグラムを描画します。ヒストグラムが自由度 4 のt分布の確率密度関数に一致することを可視化します。
### 100ページ 自由度ν=4のt分布の描画 101ページ図3.26
## パラメータの設定
nu = 4 # χ²分布の自由度パラメータ
n = 10000 # 生成するtの個数
## 乱数の生成
rng = np.random.default_rng(seed=5)
t = rng.normal(size=n, loc=0, scale=1) \
/ np.sqrt(rng.chisquare(size=n, df=nu) / nu)
## 描画処理
# 描画領域の設定
plt.figure(figsize=(8, 3))
# χ²分布の自由度パラメータν = 4のときのtのヒストグラム
plt.hist(t, bins=80, density=True, ec='white')
# 自由度ν = 4のt分布の確率密度関数の描画
line_x = np.linspace(t.min(), t.max(), 1001)
plt.plot(line_x, stats.t.pdf(line_x, df=nu), color='tab:red', lw=2)
plt.xlabel('t')
plt.ylabel('Density')
plt.title('Histogram of t');【実行結果】
ほぼ一致しました。

■ 自由度 4 のt分布の期待値・分散をシミュレーションする
自由度 4 のt分布に従う乱数を100000個生成して期待値・分散を算出し、理論値(期待値 0、分散 2)に近似することを確認します。
まずは期待値から。
### 101ページ χ²分布の期待値
nu = 4 # 自由度パラメータ
rng = np.random.default_rng(seed=5)
t = rng.standard_t(size=100000, df=nu)
t.mean() # 平均 理論値は0【実行結果】
期待値の理論値0にほぼ一致しています。

続いて分散。numpy で分散を計算します(自作関数を使いません)。
### 102ページ χ²分布の分散, numpy利用 理論値は4/(4-2)=2
t.var(ddof=0)【実行結果】
分散の理論値2にほぼ一致しています。

■ t分布の正規分布近似シミュレーション
自由度$${\nu}$$が限りなく大きくなるにつれて、t分布は標準正規分布に近づくことをシミュレーションします。
自由度$${\nu=100000}$$です。
### 102ページ t分布の標準正規分布近似 図3.27
## パラメータの設定
nu = 100000 # t分布の自由度パラメータ
n = 10000 # 生成するtの個数
## 乱数の生成
rng = np.random.default_rng(seed=123)
t = rng.standard_t(size=n, df=nu)
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 3))
# t分布の自由度100000のときのt乱数のヒストグラムの描画
ax.hist(t, bins=30, density=True, ec='white', alpha=0.7)
# 標準正規分布の確率密度関数の描画
line_x = np.linspace(t.min(), t.max(), 1001)
plt.plot(line_x, stats.norm.pdf(line_x, loc=0, scale=1),
linewidth=2, color='tab:red')
# 修飾
ax.set(xlabel='t', ylabel='Density', title='Histogram of t')
plt.tight_layout();【実行結果】
乱数のヒストグラムは標準正規分布の確率密度関数(赤い線)にほぼ一致しています。


コラム:t分布とF分布
■ $${\chi^2}$$分布とF分布
$${\chi^2}$$分布からF分布を捉えるテキストの説明・数式を引用いたします。
自由度$${\nu_1}$$の$${\chi^2}$$分布に従う確率変数$${Y_1}$$と、自由度$${\nu_2}$$の$${\chi^2}$$分布に従う確率変数$${Y_2}$$が独立のとき、$${F=\frac{Y_1 / \nu_1}{Y_2 / \nu_2}}$$は自由度$${(\nu_1, \nu_2)}$$のF分布に従います。
$$
\cfrac{Y_1 / \nu_1}{Y_2 / \nu_2} \sim F\ (\nu_1, \nu_2)
$$
■ 定理をシミュレーションする
自由度 5 の$${\chi^2}$$分布に従う 10000 個の乱数と自由度 20 の$${\chi^2}$$分布に従う 10000 個の乱数から確率変数$${F}$$を計算してヒストグラムを描画します。
ヒストグラムが自由度( 5, 20 )のF分布の確率密度関数に一致することを可視化します。
### 103ページ 自由度(5,20)のF分布の可視化 104ページ図3.28
## パラメータの設定
nu_1 = 5 # F分布の第1自由度(分子)
nu_2 = 20 # F分布の第2自由度(分母)
n = 10000 # 生成するfの個数
## 乱数の生成
rng = np.random.default_rng(seed=123)
f = ((rng.chisquare(size=n, df=nu_1) / nu_1)
/ (rng.chisquare(size=n, df=nu_2) / nu_2))
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 3))
# f分布乱数のヒストグラムの描画
ax.hist(f, bins=30, density=True, ec='white', alpha=0.7)
# 自由度(5,20)のF分布の確率密度関数の描画
line_x = np.linspace(f.min(), f.max(), 1001)
plt.plot(line_x, stats.f.pdf(line_x, dfn=nu_1, dfd=nu_2),
linewidth=2, color='tab:red')
# 修飾
ax.set(xlabel='f', ylabel='Density', title='Histogram of f',
ylim=(0, 0.75))
plt.tight_layout();【実行結果】
ほぼ一致しました。


■ t分布とF分布
t分布に従う確率変数$${T}$$の定義からF分布との関係があぶり出されます!
【確率変数$${T}$$の定義】
$$
T = \cfrac{Z}{\sqrt{Y/\nu}}
$$
【確率変数$${T}$$の二乗】
$$
T^2 = \cfrac{Z^2}{Y/\nu}
$$
確率変数$${Z}$$の二乗$${Z^2}$$は自由度1の$${\chi^2}$$分布に従うので、式を次のように変形できます。F分布の目覚めです!
$$
T^2 = \cfrac{Z^2/1}{Y/\nu}
$$
$${T^2}$$は自由度$${(1, \nu)}$$のF分布に従います。
■ 定理をシミュレーションする
標準正規分布に従う 10000個の乱数と自由度 20 の$${\chi^2}$$分布に従う 10000 個の乱数から確率変数$${F=T^2}$$を計算してヒストグラムを描画します。
ヒストグラムが自由度( 1, 20 )のF分布の確率密度関数に一致することを可視化します。
### 103ページ 自由度20のt分布と自由度(1,20)のF分布の可視化 104ページ図3.29
## パラメータの設定
nu = 20 # χ²分布の自由度パラメータ
n = 10000 # 生成するfの個数
## 乱数tの生成, tからfの導出
rng = np.random.default_rng(seed=123)
t = ((rng.normal(size=n, loc=0, scale=1)
/ np.sqrt(rng.chisquare(size=n, df=nu) / nu)))
f = t**2
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 3))
# f分布乱数のヒストグラムの描画
ax.hist(f, bins=30, density=True, ec='white', alpha=0.7)
# 自由度(5,20)のF分布の確率密度関数の描画
line_x = np.linspace(f.min(), f.max(), 1001)
plt.plot(line_x, stats.f.pdf(line_x, dfn=1, dfd=nu),
linewidth=2, color='tab:red')
# 修飾
ax.set(xlabel='f', ylabel='Density', title='Histogram of f',
ylim=(0, 0.7))
plt.tight_layout();【実行結果】
ヒストグラム(シミュレーション)は理論値としてのF分布の確率密度関数とほぼ一致しました。

今回の写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。