
「数値シミュレーションで読み解く統計のしくみ」をPythonで写経 ~ 第7章7.2「シミュレーションデータで統計指標の意味を理解する」

第7章「回帰分析とシミュレーション」
書籍の著者 小杉考司 先生、紀ノ定保礼 先生、清水裕士 先生
この記事は、テキスト「数値シミュレーションで読み解く統計のしくみ」第7章「回帰分析とシミュレーション」の7.2節「シミュレーションデータで統計指標の意味を理解する」の Python写経活動 を取り扱います。
第7章は回帰分析を掘り下げます。
今回は回帰分析の係数とサンプルサイズに関連する4つのシミュレーションを実践します。

R の基本的なプログラム記法はざっくり Python の記法と近いです。
コードの文字の細部をなぞって、R と Python の両方に接近してみましょう!
ではテキストを開いてシミュレーションの旅に出発です🚀
はじめに
テキスト「数値シミュレーションで読み解く統計のしくみ」のご紹介
このシリーズは書籍「数値シミュレーションで読み解く統計のしくみ〜Rでためしてわかる心理統計」(技術評論社、「テキスト」と呼びます)の Python写経です。
テキストは、2023年9月に発売され、副題「Rでためしてわかる心理統計」のとおり、統計処理に定評のある R の具体的なコードを用いて、心理統計の理解に役立つ数値シミュレーションを実践する素晴らしい書籍です。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「数値シミュレーションで読み解く統計のしくみ〜Rでためしてわかる心理統計」初版第1刷、著者 小杉考司・紀ノ定保礼・清水裕士、技術評論社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
7.2 シミュレーションデータで統計指標の意味を理解する
この章では以下の4つのシミュレーションを実践します。
① 単回帰の回帰係数の標準誤差
② 単回帰の回帰係数の統計的検定
③ 単回帰のサンプルサイズ設計
④ 重回帰のサンプルサイズ設計($${F}$$統計量使用)

この記事は Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
概ね確率分布の特性値算出には scipy.stats を用い、乱数生成には numpy.random.generator を用いるようにしています。
主に利用するライブラリをインポートします。
### インポート
# 数値計算
import numpy as np
# データフレーム
import pandas as pd
# 確率・統計
import scipy.stats as stats
import statsmodels.formula.api as smf # 回帰分析等の統計処理
# 描画
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'
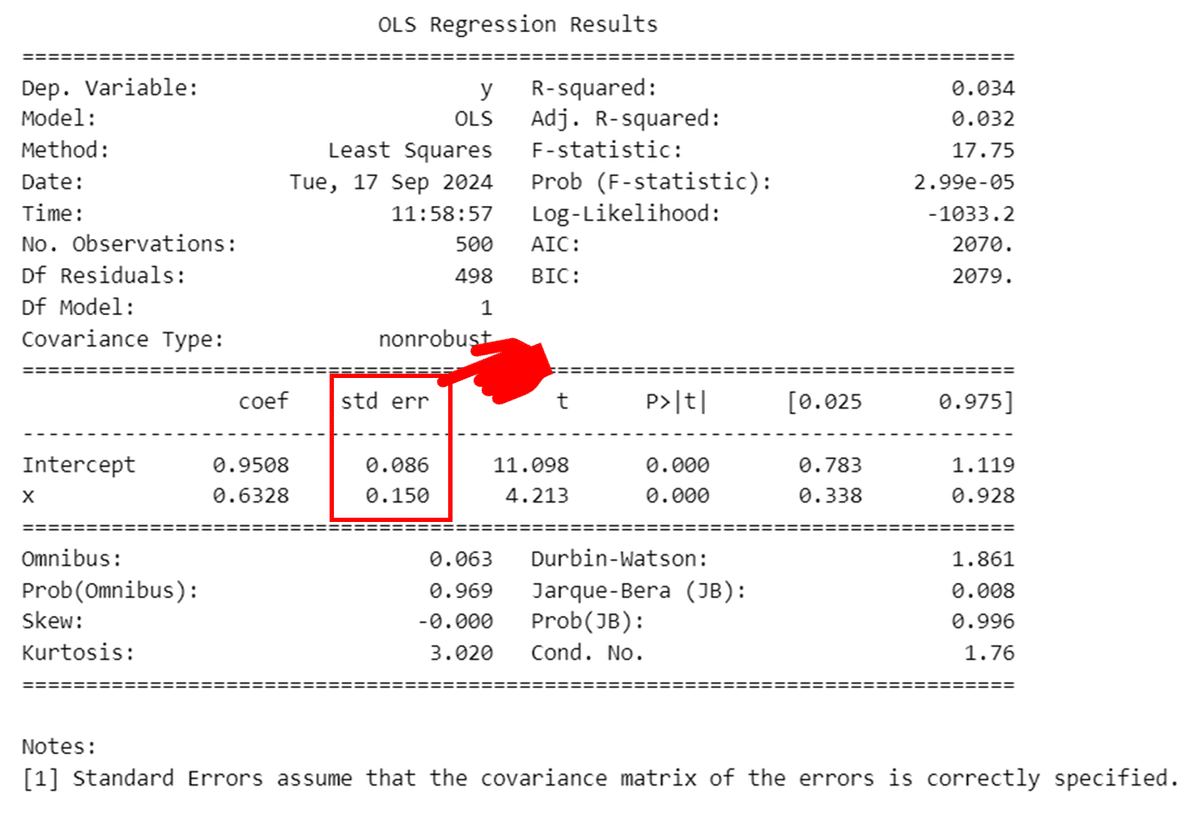
7.2.1 係数の標準誤差
statsmodels の回帰分析結果に表示される係数の標準誤差をシミュレーションします。
下図の赤枠の部分が係数の標準誤差です。
■ 準備
単回帰シミュレーションを500回繰り返して、500個の切片、傾き、切片の標準誤差、傾きの標準誤差、残差の標準偏差を取得します。
テキストにならってシミュレーション関数を定義します。
サンプルサイズ、切片の真値、傾きの真値、残差の標準偏差の真値を引数で受け取り、単回帰の確率モデルでデータを生成して回帰分析を実行し、戻り値として切片・傾き・切片の標準誤差・傾きの標準誤差・残差の標準偏差の推定値を返します。
### 261ページ シミュレーション関数の定義
# 与えられたサンプルサイズ・係数・標準偏差で回帰モデルデータを生成し、
# 回帰分析を実行して切片・傾きの推定値と標準誤差、残差標準偏差を算出する関数
def lm_simulation(n, beta0, beta1, sigma):
# 説明変数の生成
x = rng.uniform(size=n, low=-1, high=1)
# 残差の生成
e = rng.normal(size=n, loc=0, scale=sigma)
# 目的変数の生成
y = beta0 + beta1 * x + e
# 回帰モデルの実行
model = smf.ols('y ~ x', data=dict(x=x, y=y)).fit()
# 残差標準偏差の計算: (残差平方和/残差の自由度)の平方根
rds = np.sqrt(model.ssr / model.df_resid)
# 結果のまとめ
results = np.array([
model.params.iloc[0], # beta0: 切片の推定値
model.params.iloc[1], # beta1: 傾きの推定値
model.bse.iloc[0], # se0: 切片の標準誤差
model.bse.iloc[1], # se1: 傾きの標準誤差
rds, # residuals: 残差標準偏差
]).reshape(1, -1)
return resultsこの関数の動作確認を行います。
サンプルサイズ$${n=500}$$、切片$${\beta_0=1}$$、傾き$${\beta_1=0.5}$$、残差標準偏差$${\sigma=2}$$です。
### 262ページ 上記関数の動作確認
rng = np.random.default_rng(seed=7)
lm_simulation(n=500, beta0=1, beta1=0.5, sigma=2)【実行結果】
左から切片・傾き・切片の標準誤差・傾きの標準誤差・残差標準偏差の推定値です。

■ シミュレーション実行
シミュレーション回数は1000回です。
サンプルサイズ$${n=500}$$、切片$${\beta_0=1}$$、傾き$${\beta_1=0.5}$$、残差標準偏差$${\sigma=2}$$の条件でデータ生成します。
### 262ページ シミュレーションの実行
## 設定と準備
n = 500 # サンプルサイズ
beta0 = 1 # 切片
beta1 = 0.5 # 傾き
sigma = 2 # 標準偏差
iter = 1000 # シミュレーション回数
# 結果を格納するオブジェクト
results = np.zeros((iter, 5))
## シミュレーション
rng = np.random.default_rng(seed=7)
for i in range(iter):
results[i, :] = lm_simulation(n=n, beta0=beta0, beta1=beta1, sigma=sigma)
## 結果(データフレームに)
df = pd.DataFrame(
results, columns=['beta0', 'beta1', 'beta0se', 'beta1se', 'residuals'])
df【実行結果】
1000個のシミュレーションデータを取得できました。

■ シミュレーションデータの確認
係数の標準誤差を算出する前にシミュレーション結果を確認します。
切片と傾きの平均を見ます。
係数の「一致性」の性質を確認できます。
### 263ページ 切片beta0の推定値の平均 ・・・ 回帰係数の一致性
df['beta0'].mean()【実行結果】
切片$${\beta_0=1}$$にほぼ一致しています。

### 263ページ 傾きbeta1の推定値の平均 ・・・ 回帰係数の一致性
df['beta1'].mean()【実行結果】
傾き$${\beta_1=0.5}$$にほぼ一致しています。

続いて、取得した切片と傾きのヒストグラムを描画してバラツキ具合を確認します。
ヒストグラム描画関数の定義から。
### ヒストグラム描画関数の定義
def plot_histogram(x, col_name='value', bins=20):
plt.figure(figsize=(6, 3))
plt.hist(x, bins=bins, ec='white', alpha=0.7)
plt.axvline(x.mean(), color='tab:red', lw=2, label='平均値')
plt.xlabel(col_name)
plt.ylabel('Frequency')
plt.legend(loc='upper right')
plt.show()切片のヒストグラムを描画します。
### 264ページ 図7.2 切片のヒストグラム
plot_histogram(df['beta0'], col_name='beta0')【実行結果】

傾きのヒストグラムを描画します。
### 264ページ 図7.3 傾きのヒストグラム
plot_histogram(df['beta1'], col_name='beta1')【実行結果】

各係数の平均値は理論値に近いことが分かります。
テキストは、ヒストグラムで可視化された分布の幅=標準偏差を見積もることで係数の推定値の精度を表現できるとしています。
この推定値の精度は statsmodels の係数の標準誤差に示された値になります。
■ 係数の標準誤差の算出
この項のゴールである係数の標準誤差を算出しましょう。
切片の標準偏差です。
### 264ページ 切片の推定値の標準偏差
df['beta0'].std(ddof=1)【実行結果】

傾きの標準偏差です。
### 264ページ 傾きの推定値の標準偏差
df['beta1'].std(ddof=1)【実行結果】

冒頭に掲げた statsmodels の回帰分析結果の表は、1回の回帰分析を示しています。
この表の切片・傾きの標準誤差と、シミュレーションで得た切片・傾きの標準誤差は近い値になっています。
7.2.2 係数の検定
前項のシミュレーションで得たデータを引き続き使用します。
この項では、まず、傾きの95%信頼区間を分析します。
下図の statsmodels の 傾きの95%信頼区間に相当します。

■ 傾きの95%信頼区間の確認
傾きの推定値から、自由度$${n-2}$$のt分布の97.5パーセンタイル点を加減算することで、95%信頼区間の上限と下限を算出します。
### 265ページ 傾きbeta1の95%信頼区間の算出
df['upper'] = df['beta1'] + stats.t.ppf(q=0.975, df=n - 2) * df['beta1se']
df['lower'] = df['beta1'] - stats.t.ppf(q=0.975, df=n - 2) * df['beta1se']
df【実行結果】

この95%信頼区間が確率モデルの傾きの真値$${\beta_1=0.5}$$を含む割合を計算します。
### 265ページ 傾きbeta1の95%信頼区間が真値を含む割合の算出
df['true_in'] = ((df['lower'] <= beta1) & (beta1 <= df['upper'])) * 1
# 95%信頼区間が真値を含んだ割合
sum(df['true_in']) / iter【実行結果】
結果は$${0.952}$$です。
シミュレーションにて、$${95\%}$$に近い割合で信頼区間が真値を含むことを確認できました。

■ 傾きが有意かどうかの判定
傾きが0の場合、説明変数が目的変数を説明していないことになります。
テキストによると「帰無仮説が$${\beta_1=0}$$であれば、信頼区間に0が含まれていれば有意ではない、含まれていなければ有意である、と判断することになる」です。
シミュレーションデータにて、95%信頼区間が0を含む割合を算出して確認してみます。
### 266ページ 傾きbeta1の95%信頼区間が0を含む割合の算出 →タイプⅡエラー確率
df['null_in'] = ((df['lower'] <= 0) & (0 <= df['upper'])) * 1
# 95%信頼区間が0を含んだ割合
sum(df['null_in']) / iter【実行結果】
$${11.6\%}$$です。
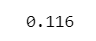
テキストの図7.4を描画します。
信頼区間が赤い線の0を含むかを可視化します。
### 266ページ 図7.4
# 描画領域の設定
fig, ax = plt.subplots(figsize=(8, 4))
# 回帰係数の推定値(点)と信頼区間(線)をエラーバーで描画
ax.errorbar(df.index, df['beta1'], yerr=df['upper'] - df['beta1'],
fmt='o', ms=5, mew=0.5, mec='white', elinewidth=0.2)
# 係数が0の水平線を描画
ax.axhline(0, color='tab:red', lw=1.5)
# x軸ラベル、y軸ラベル、タイトルの設定
ax.set(xlabel='反復回数', ylabel='傾きの係数', title='回帰係数と信頼区間')
# グリッド線の表示
plt.grid(lw=0.5);【実行結果】

シミュレーションでは、$${11.6\%}$$の割合で傾きが有意ではない、と判定されました。
この割合は帰無仮説が正しくないときに帰無仮説を棄却できないエラー:タイプⅡエラー確率$${\beta}$$であり、検出力$${1-\beta}$$は$${88.4\%}$$です。
テキストは、タイプⅡエラー確率はサンプルサイズ、傾きの大きさで変わるとし、データ取得前にコントロール可能なサンプルサイズ設計が重要である、としています。
7.2.3 回帰分析のサンプルサイズ設計
単回帰(切片=0)のサンプルサイズ設計に移ります。
タイプⅡエラー確率が閾値以下になるサンプルサイズをシミュレーションします。
■ シミュレーション関数の定義
有意水準・傾き・残差標準偏差・サンプルサイズ・シミュレーション回数を引数で与えてデータ生成と回帰分析を実行、傾きの$${p}$$値が有意水準を上回る割合=タイプⅡエラー確率(割合)を返す関数です。
### 267ページ 単回帰モデルのタイプⅡエラー確率算出関数
# データ標準化済み、傾きは想定値とし、所与のサンプルサイズのタイプⅡエラー確率を計算
# 回帰分析には処理時間が短いscipy.statsを使用
def t2e_lm(alpha, beta1, sigma, n, iter_t2e):
pValue = np.zeros(iter_t2e)
for i in range(iter_t2e):
# 説明変数の生成
x = rng.standard_normal(size=n)
# 残差の生成
e = rng.normal(size=n, loc=0, scale=sigma)
# 目的変数の生成(切片なし)
y = beta1 * x + e
## scipy,statsを使用
# 回帰モデルの実行
model = stats.linregress(x=x, y=y)
# p値を取り出す
pValue[i] = model.pvalue
## 参考:statsmodelsの場合
# 回帰モデルの実行
# model = smf.ols('y ~ x', data=dict(x=x, y=y)).fit()
# p値を取り出す
# pValue[i] = model.pvalues.x
# 有意でない(p値が有意水準を超えた)割合を算出
t2e = (pValue > alpha).mean()
return t2e前項では傾きの95%信頼区間を用いてタイプⅡエラー確率を算出する方法を学びましたが、この関数では傾きの$${p}$$値を用いて算出する方法に変わっています。
傾きの$${p}$$値が有意水準を上回る場合、帰無仮説「傾き=0」を受容する(棄却できない)ので「信頼区間に0が含まれていれば有意ではない」と同じ意味になる、のでしょうか。
■ シミュレーションの実行
有意水準$${\alpha=0.05}$$、傾き$${\beta_1=1}$$、残差標準偏差$${\sigma=2}$$、サンプルサイズ$${n=100}$$・シミュレーション回数$${10000}$$回でシミュレーションを実行します。
### 268ページ 続き サンプルサイズシミュレーションのテスト実行 n=100
# 設定と準備
alpha = 0.05 # 有意水準
beta1 = 1 # 傾き
sigma = 2 # 標準偏差
n = 100 # サンプルサイズ
iter = 10000 # シミュレーション回数
# シミュレーション
rng = np.random.default_rng(seed=123)
t2e_lm(alpha, beta1, sigma, n, iter_t2e=iter)【実行結果】
サンプルサイズ$${n=100}$$のとき、シミュレーションによるタイプⅡエラー確率(割合)は$${0.33\%}$$です。

■ タイプⅡエラー確率が$${0.20}$$未満になるサンプルサイズをシミュレーション
テキストにならって、サンプルサイズを 10 から 201 まで 10 刻みで変えて、タイプⅡエラー確率が閾値$${\beta=0.20}$$になるまでシミュレーションを繰り返します。
### 268ページ 続き サンプルサイズシミュレーションの実行
# タイプⅡエラー確率が閾値以下になるまでサンプルサイズを変えて実行
# 設定と準備
alpha = 0.05 # 有意水準
beta1 = 1 # 傾き
sigma = 2 # 標準偏差
beta = 0.2 # タイプⅡエラー確率の閾値(検出力0.8)
iter = 10000 # シミュレーション回数
# シミュレーション
rng = np.random.default_rng(seed=123)
# サンプルサイズnを10から200まで10刻みに変えて、タイプⅡエラー確率を算出
for n in range(10, 201, 10):
# タイプⅡエラー確率の算出
type2_error = t2e_lm(alpha, beta1, sigma, n, iter_t2e=iter)
# 結果表示
print(f'n = {n:3d}, type2 error = {type2_error:.4f}')
# タイプⅡエラー確率が閾値以下になったら処理を終了
if type2_error <= beta:
break【実行結果】
サンプルサイズが大きくなるにつれてタイプⅡエラー確率も小さくなり、サンプルサイズ$${n=40}$$のとき、タイプⅡエラー確率は $${0.20}$$ 未満になりました。

ちなみに1刻みでサンプルサイズをシミュレーションするとこんな感じです。
### 2続き サンプルサイズシミュレーションの実行
# タイプⅡエラー確率が閾値以下になるまでサンプルサイズを変えて実行
# シミュレーション
rng = np.random.default_rng(seed=123)
# サンプルサイズnを30から40まで1刻みに変えて、タイプⅡエラー確率を算出
for n in range(30, 41):
# タイプⅡエラー確率の算出
type2_error = t2e_lm(alpha, beta1, sigma, n, iter_t2e=iter)
# 結果表示
print(f'n = {n:3d}, type2 error = {type2_error:.4f}')
# タイプⅡエラー確率が閾値以下になったら処理を終了
if type2_error <= beta:
break【実行結果】
タイプⅡエラー確率$${\beta=0.20}$$・検出力$${1 - \beta = 0.80}$$の場合、必要サンプルサイズは 36 です。
テキストは 35 ですので、発生させた乱数に違いがあったのかもです。

7.2.4 回帰分析(重回帰分析)のサンプルサイズ設計
重回帰のサンプルサイズ設計に移ります。
回帰の有意性の検定(重相関係数に対する検定)に用いる$${F}$$統計量をサンプルサイズ設計のベースにします。
回帰の有意性の検定の帰無仮説は「母集団におけるモデル全体としての説明力が0」です。
$${F}$$統計量に関するテキストの数式をお借りします。
$$
F = \cfrac{R^2}{1 - R^2}\ \times \ \cfrac{n - p - 1}{p}
$$
重相関係数$${R^2}$$、サンプルサイズ$${n}$$、説明変数の個数$${p}$$であり、右辺第1項 $${\frac{R^2}{1 - R^2}}$$は Cohen の$${f^2}$$という効果量です。
サンプルサイズの算出には非心度$${\lambda = f^2 n}$$の非心$${F}$$分布を用います。
非心$${F}$$分布には scipy.stats の ncf を利用します。
ではサンプルサイズのシミュレーションに移ります。
■ 重回帰分析のサンプルサイズのシミュレーション
タイプⅡエラー確率算出関数を定義します。
### 270ページ F値のタイプⅡエラー確率を算出する関数
def t2e_MRA(alpha, n_param, n, R2=None, f2=None):
# 引数R2とf2の両方が未入力の場合、メッセージを表示して関数を終了
if R2 is None and f2 is None:
print('効果量f2か重相関係数R2を入力してください')
return
# R2が入力され、f2が未入力の場合、R2の値からf2を算出
if f2 is None:
f2 = R2 / (1 - R2)
# 非心度の計算
lambda_ = f2 * n
# 自由度の計算
df1 = n_param # 分子の自由度
df2 = n - n_param - 1 # 分母の自由度
# 臨界値の計算: F分布のパーセント点
cv = stats.f.ppf(q=1 - alpha, dfn=df1, dfd=df2)
# タイプⅡエラー確率の計算: 非心F分布の累積分布関数
type2_error = stats.ncf.cdf(x=cv, dfn=df1, dfd=df2, nc=lambda_)
return type2_error必要サンプルサイズをシミュレーションで算出します。
中程度の効果量$${f^2=0.15}$$、有意水準$${\alpha=0.05}$$、タイプⅡエラー確率の閾値$${\beta=0.2}$$、説明変数の数$${p=10}$$で実行します。
### 271ページ 重回帰分析の必要サンプルサイズのシミュレーション
## 設定と準備
f2 = 0.15 # cohenの効果量f²
alpha = 0.05 # 有意水準
beta = 0.2 # タイプⅡエラー確率の閾値
p = 10 # 説明変数の数
## シミュレーション
# サンプルサイズを20~2000まで動かして、タイプⅡエラー確率が閾値以下になる
# サンプルサイズを探索
for n in range(20, 2001):
# タイプⅡエラー確率の算出
type2_error = t2e_MRA(alpha, f2=f2, n_param=p, n=n)
# タイプⅡエラー確率が閾値以下になったら探索終了
if type2_error <= beta:
break
## 出力:必要サンプルサイズ
n【実行結果】
必要サンプルサイズは$${n=118}$$です。

今回の写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。