
シリーズR① 文字コードの呪い~R言語の直し方が分からないのでアール

はじめに
シリーズRのご案内
「シリーズR」の R はアールと読みます。
シリーズ R は、統計処理に強いプログラミング言語「R言語」に関する記事を取り扱うのでアール。
主に、R 言語のつまづきと解決の糸口を書きます。
現場ですぐ使える 時系列データ分析
この記事は、書籍「現場ですぐ使える時系列データ分析~データサイエンティストのための基礎知識」の「5-4節のコード」が動かないときの解決策を取り扱います。
2014年初版のこの書籍は、時系列データ分析の入門書に位置づけられ、さまざまなデータ分析の紹介サイトで推薦されています。
株価・収益率の時系列データをR言語で分析するコード事例が盛り込まれています。
今回取り組む問題
第5章「【実践編】時系列分析の投資への応用」第4節「クラスタリングのペアトレーディングへの活用」に記載された「図5-6 クラスタリング」を描画するコードがエラーになる事象の解決に取り組みます。
やってる内容は大したことではないのですが、エラーを解消してコードが動くようになったときの感激をお伝えできれば幸いです。
デンドログラムを描画する!
1. 事象
この書籍のサンプルコードで用いられる「.RData」形式の株価・収益率等のデータは、出版社のサポートページからダウンロードして取得します。
エラーは、「.RData」ファイル内の「data.log.core30」データを用いて「デンドログラム」図を描画するコードで発生しました。
エラーの発生するコード
fit.clust=hclust(dist(t(data.log.core30)))
plot(fit.clust)エラーメッセージ
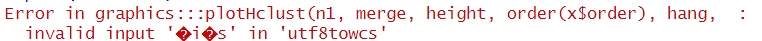
Error in graphics:::plotHclust(n1, merge, height, order(x$order), hang, : invalid input '�i�s' in 'utf8towcs'
エラーメッセージに「utf8」の文字が見えたので、おそらく文字コードの問題だろうと想定しておきます。
2. 原因分析
オブジェクトの種類の確認
「data.log.core30」データが何者かを調べます。(参考情報1)
> class(data.log.core30)
[1] "data.frame"データフレームです。表形式のデータです。
データの参照
データの中身を見てみましょう。
> head(data.log.core30)
\x82i\x82s \x83Z\x83u\x83\x93 \x90M\x89z\x89\xbb \x89ԉ\xa4 \x95\x90\x93c \x83A\x83X\x83e\x83\x89\x83X
1 -2.33271917 -0.2088119 -1.0303468 -0.3920719 -0.5578815 -0.1261830
2 -0.13120492 0.0000000 1.1441772 -0.3498036 -0.1399580 -0.7604599
3 -0.04377326 -2.4974843 -0.5704522 -1.8568173 -1.9802627 -0.8945747
4 -0.08760404 1.6578488 1.9264052 1.8568173 1.2775191 0.6397974
5 0.74219943 -4.3072980 1.6694879 0.4370636 0.1409444 -1.4129972
6 -2.68916359 0.2637364 -2.1194324 -0.9640741 0.8415197 0.5161302列名がおかしなことになっているようです。
文字コード変換の実験
試しに列名の文字コードを変換してみましょう。(参考情報2、3)
「iconv」関数を利用して、SHIFT-JIS(CP932)からUTF-8に変換してみます。
> iconv(colnames(data.log.core30), from = "CP932", to = "utf8")
[1] "JT" "セブン" "信越化" "花王" "武田" "アステラス" "新日鉄住金"
[8] "コマツ" "日立" "東芝" "パナソニック" "ソニー" "ファナック" "日産自"
[15] "トヨタ" "ホンダ" "キヤノン" "三井物" "三菱商" "三菱UFJ" "三井住友FG"
[22] "みずほFG" "野村" "東京海上" "菱地所" "JR東日本" "NTT" "NTTドコモ"
[29] "ソフトバンク"ビンゴッ!!!
ちなみに利用環境の文字コードは「UTF-8」です。
「SHIFT-JIS」環境を使う場合には、このエラーは発生しないのかも知れません。
実は・・・
書籍にこんな一文が記載されていました。
(太字は筆者によるものです)
デンドログラムをわかりやすくするために、データ data.log.core30 では列名をこれまでのような証券コードではなく省略した企業名にしています。
そういうことだったのか・・・・
今までエラーが出なかった理由に納得です。
3. 解決策
今回の対処は「読み込んだデータフレームの列名の文字コードを変換する」ことにします。
データフレーム「data.log.core30」の列名を扱う「colnames」に、文字コード変換した列名を代入します。(参考情報3)
問題を解決するコードはこちら。
colnames(data.log.core30) <- iconv(colnames(data.log.core30),
from = "CP932", to = "utf8")変換後のデータフレームの中身を見てみましょう。
> head(data.log.core30)
JT セブン 信越化 花王 武田 アステラス 新日鉄住金 コマツ 日立
1 -2.33271917 -0.2088119 -1.0303468 -0.3920719 -0.5578815 -0.1261830 -1.2578782 -1.04644513 0.0000000
2 -0.13120492 0.0000000 1.1441772 -0.3498036 -0.1399580 -0.7604599 0.6309169 -1.19049025 -0.2306806
3 -0.04377326 -2.4974843 -0.5704522 -1.8568173 -1.9802627 -0.8945747 -1.9048195 0.06651148 -1.1614532
4 -0.08760404 1.6578488 1.9264052 1.8568173 1.2775191 0.6397974 0.0000000 0.66269295 2.5376217
5 0.74219943 -4.3072980 1.6694879 0.4370636 0.1409444 -1.4129972 1.2739026 2.15624166 0.0000000
6 -2.68916359 0.2637364 -2.1194324 -0.9640741 0.8415197 0.5161302 2.5001302 -3.48604849 -3.9494099列名に読める文字が表示されました!
4. 成果
データが整ったところで、デンドログラムを描画しましょう。
fit.clust=hclust(dist(t(data.log.core30)))
plot(fit.clust)
デンドログラムを出力できました!
デンドログラムは「クラスタリング」を可視化するツールです。
この図では「最遠隣法」(最長距離法)を用いています。
株価日次収益率の「類似度が高い企業同士」が近くに配置されています。
中には思いもよらない異業種の組み合わせがありますね!
5. まとめ
「UTF-8」利用環境で「SHIFT-JIS」の混在するデータを扱う方法の1つ、「読み込み済みデータの文字コードを iconv 関数でUTF-8に変換する方法」を実施しました。
なお、最初に取り組んだのは「読み込んだデータフレームをCSV出力する際に文字コード変換する方法」(write.csv関数)でした。
変換後のデータを保存(永続化)して、再読み込みする作戦です。
しかし、write.csv関数の実行時にエラーが発生したことと、エラー解決策が簡単に見つからなかったことにより、この対策は見送りました。
参考情報
今回のエラー解消の際に利用したWebサイトです。
特に2番目のサイトで文字コード変換関数を教えていただいたおかげで、エラーを解消することができました!
ありがとうございます!
1.オブジェクトの種類を調べる:class
2.文字コードを変換する:iconv
3.列名を参照する/変更する:colnames
以上です。
おわりに
R言語にはなかなか慣れないです・・・。
ネットで得られる情報は限られており(Pythonとの比較)、つまづいたときのリカバリの難しさを感じています。
しかし、とても短いコードで統計的な分析ができる便利な言語でもあります。
覚えておきたい言語です。
おわり
ブログの紹介
noteで3つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
2.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
3.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。