
「回帰分析から学ぶ計量経済学」をPythonで写経 ~ 第2章「結果をどう評価するか」①回帰分析と統計的推定・統計的検定

第2章「結果をどう評価するか」
書籍の著者 山澤成康 先生
この記事は、書籍「回帰分析から学ぶ計量経済学」第2章「結果をどう評価するか」の Python写経活動 を取り扱います。
今回は 確率分布、統計的推定、統計的検定 に取り組みます!
線形回帰モデルの回帰係数の検定の基礎体力づくりに相当します。
では書籍を開いて回帰分析の旅に出発です🚀

はじめに
書籍「回帰分析から学ぶ計量経済学」のご紹介
このシリーズは書籍「回帰分析から学ぶ計量経済学: Excelで読み解く経済のしくみ」(オーム社、「テキスト」と呼びます)の Python 写経です。
テキストは、2023年11月に発売され、副題「Excelで読み解く経済のしくみ」のとおり、主に Excel を用いて、計量経済学を平易に学べる素晴らしい書籍です。
テキストの「はじめに」に著者の先生が執筆の動機を書かれています。
社会人の統計リテラシーの向上をテーマの1つとした科研費プロジェクトの最終年度で、広く社会人に向けてわかりやすい経済分析の本を書きたかったのです。
私にとって計量経済学は高嶺の花ですが、このテキストでさまざまな回帰分析のアプローチを知ることができました。
また、書籍の Excel 処理を Python に置き換える「寄り道写経」の実践を通じて、回帰分析のお気持ちに少し近づけた感じがいたします。
回帰分析に慣れ親しむのに丁度良いレベル感と内容ですので、これはぜひともブログにしたい!と思って現在に至ります。
計量経済学の色を薄め、データ分析の色を濃いめに書いてまいります!

引用表記
この記事は、出典に記載の書籍に掲載された文章と配布データを引用し、適宜、掲載文章・配布データを改変して書いています。
【出典】
「回帰分析から学ぶ計量経済学: Excelで読み解く経済のしくみ」
第1版第1刷、著者 山澤成康、オーム社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
第2章 結果をどう評価するか
この記事は第2章の以下の節を取り扱います。
2.1 確率変数と確率分布
2.2 統計量と確率の関係
2.4 統計的推定
2.5 統計的検定
2.6 係数がとりうる範囲(標準誤差)
2.7 係数がゼロの検定(t検定)
2.8 係数成約の検定(F検定)
2.9 平均値の差の検定(t検定)
記事に用いるデータは、オーム社の書籍紹介サイトからダウンロードできる Excel ファイル内のデータをもとにしてCSVファイルを作成し、data フォルダに格納しています。
第2章で用いるライブラリをインポートします。
### インポート
# 数値計算
import numpy as np
import pandas as pd
# 統計処理
import scipy.stats as stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
# 機械学習(線形回帰・OLS)
from sklearn.linear_model import LinearRegression
# 描画
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'
2.1 確率変数と確率分布
テキストの諸定義をお借りします。
確率変数
・変数のうちそれぞれの値に確率が結びついているもの
離散確率変数
・確率変数のとる値がサイコロの目のように有限な場合
連続確率変数
・確率変数のとる値が連続的に変化する(無限の)場合
確率密度関数
・連続確率変数に対応する確率
■ 標準正規分布と$${Z}$$値 p.60
標準正規分布は平均 0、標準偏差 1 の正規分布です。
データの平均$${\mu}$$からの差を標準偏差$${\sigma}$$で割ることを標準化と呼び、標準化したデータを$${Z}$$値と呼びます。
以下は標準化の数式です。
$$
z = \cfrac{x-\mu}{\sigma}
$$
正規分布の確率密度関数をpythonで関数定義してみます。
### 正規分布の確率密度関数の定義
def normal_dist(x, mu, sigma):
return (
1 / (np.sqrt(2 * np.pi) * sigma) * np.exp(-(x - mu)**2 / (2 * sigma**2))
)この関数を利用して、標準正規分布と標準偏差の倍数の区間を可視化します。
### 標準正規分布とZ値の可視化 関数利用
## 描画用データの作成
# σ区間
sigma_int = [0.683, 0.954, 0.997, 0.999]
# x軸の値
x = np.linspace(-5, 5, 1001)
# 標準正規分布の確率密度関数の算出
y = normal_dist(x=x, mu=0, sigma=1)
## 描画
# 描画領域の設定
plt.figure(figsize=(6, 3))
# 標準正規分布の確率密度関数の描画
plt.plot(x, y)
# σ=1, 2, 3の垂直線の描画
colors = ['tab:red', 'tab:green', 'tab:orange', 'gray']
for i, color in zip(range(1, len(colors)+1), colors):
plt.axvline(
i, color=color, lw=0.9, ls='--',
label=f'{i}σ区間 {sigma_int[i-1]:.1%}')
plt.axvline(-i, color=color, lw=0.9, ls='--')
# 修飾
plt.xlabel('z')
plt.ylabel('確率密度')
plt.grid(lw=0.5)
plt.legend(bbox_to_anchor=(1, 1), title='σ区間と確率');【実行結果】

scipy.stats の norm を使って、標準正規分布と標準偏差の倍数の区間を可視化します。
pdf メソッドで確率密度関数を取得できます。
引数 loc に平均 0 を、引数 scale に標準偏差 1 を与えることで標準正規分布の確率密度関数を得ることができます。
### 標準正規分布とZ値の可視化 scipy.stats利用
## 描画用データの作成
# x軸の値
x = np.linspace(-5, 5, 1001)
# 標準正規分布の確率密度関数の算出
std_norm_dist = stats.norm(loc=0, scale=1)
y = std_norm_dist.pdf(x)
## 描画
# 描画領域の設定
plt.figure(figsize=(6, 3))
# 標準正規分布の確率密度関数の描画
plt.plot(x, y)
# σ=1, 2, 3の垂直線の描画
colors = ['tab:red', 'tab:green', 'tab:orange', 'gray']
for i, color in zip(range(1, len(colors)+1), colors):
plt.axvline(
i, color=color, lw=0.9, ls='--',
label=f'{i}σ区間 {std_norm_dist.cdf(i) - std_norm_dist.cdf(-i):.2%}')
plt.axvline(-i, color=color, lw=0.9, ls='--')
# 修飾
plt.xlabel('z')
plt.ylabel('確率密度')
plt.grid(lw=0.5)
plt.legend(bbox_to_anchor=(1, 1), title='σ区間と確率');【実行結果】

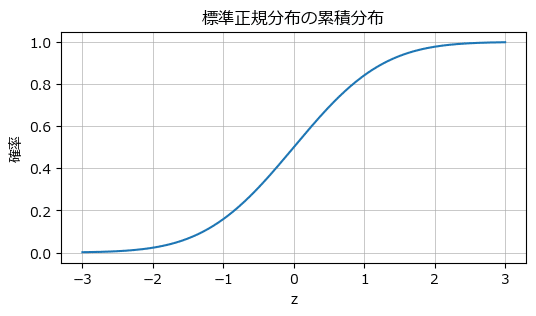
■ 標準正規分布の累積分布関数 p.61
標準正規分布の累積分布関数を描画します。
scipy.stats の norm の cdf メソッドで累積分布関数を取得できます。
引数 loc に平均 0 を、引数 scale に標準偏差 1 を与えることで標準正規分布の累積分布関数を得ることができます。
## 描画用データの作成
# x軸の値
x = np.linspace(-3, 3, 1001)
# 標準正規分布の累積分布関数の算出
y = stats.norm.cdf(x, loc=0, scale=1)
## 描画処理
# 描画領域の設定
plt.figure(figsize=(6, 3))
plt.plot(x, y)
plt.title('標準正規分布の累積分布')
plt.xlabel('z')
plt.ylabel('確率')
plt.grid(lw=0.5)
plt.show()【実行結果】
2.2 統計量と確率の関係
テキストに例示のある4つのケースを実践します。
■ 確率変数のパーセンタイル点を取得
平均 80、標準偏差 10 の正規分布で確率変数が 70 の場合のパーセンタイル点を累積分布関数から取得します。
scipy.stats の norm.cdf で累積分布関数を算出できます。
### 平均80点, 標準偏差10のテストで70点のとき、下位から何%?(正規分布)
stats.norm.cdf(x=70, loc=80, scale=10)【実行結果】
下位から約 15.9% です。

■ パーセンタイル点から確率変数の値を算出
平均 80、標準偏差 10 の正規分布で上位 10% に入る確率変数の値を取得します。
scipy.stats の norm.ppf でパーセンタイル点に対応する確率変数の値を取得できます。
### 平均80点, 標準偏差10のテストで上位10%の点数は?(正規分布)
# stats.norm.isf(q=0.1, loc=80, scale=10) # これでも算出できる
stats.norm.ppf(q=0.9, loc=80, scale=10)【実行結果】
上位 10%(下位 90% )に入る確率変数の値は約 92.8 です。

■ 自由度 100、$${t}$$値 2 のときの$${t}$$分布のパーセンタイル点を算出
scipy.stats の t.cdf でパーセンタイル点を取得できます。
引数 df に自由度を設定します。
### 自由度100, t値が2のとき、t分布の下位から何%?
stats.t.cdf(x=2, df=100)【実行結果】
下位から約 97.6% です。

■ 自由度 100、$${t}$$値 2 のときの両側検定の$${P}$$値を算出
scipy.stats の t.sf で上側確率を算出して2倍します。
### 自由度100, t値が2のとき、両側検定のp値は?
stats.t.sf(x=2, df=100) * 2【実行結果】
$${P}$$値は約 4.8% です。

2.4 統計的推定
統計的推定の意味をテキストの記述をお借りして記載します。
標本調査を行った場合、それを母集団情報へと変換する必要があります。
その手法を統計的推定と呼びます。
統計的推定には点推定、区間推定が含まれます。
点推定は1つの値(1つの点)を推定値とします。
区間推定は一定の幅をもった区間を推定値とします。
テキストは$${t}$$分布を用いた区間推定を紹介しています。
テキストによると・・・
母集団が正規分布の場合、標本の分布は$${t}$$分布に従うことが知られています。母集団の平均$${\mu}$$がとりうる値は以下の式で表されます。
$$
\bar{X} - T \times SE \leq \mu \leq \bar{X} + T \times SE \\
$$
$${\bar{X}}$$は標本平均、$${T}$$は$${t}$$値、$${SE}$$は標準誤差$${s/\sqrt{n}}$$、$${n}$$は標本サイズです。
■ 95%信頼区間の$${t}$$値 p.67
テキストにならって、3つの自由度に対する95%信頼区間の$${t}$$値(上側)を算出します。
scipy.stats の t.interval() で$${t}$$分布の信頼区間を取得できます。
### t値の95%信頼区間の算出
# 標本サイズを変数にもつデータフレームの作成
df1 = pd.DataFrame({'標本サイズ': [10, 100, 1000]})
# 区間推定の自由度の算出 ※標本サイズ - 1
df1['自由度'] = df1['標本サイズ'] - 1
# 95%信頼区間の上端の算出
df1['95%信頼区間のt値'] = stats.t.interval(0.95, df=df1['自由度'])[1]
# 結果表示
display(df1)【実行結果】

続いて自由度$${4}$$の$${t}$$分布の 95% 信頼区間を可視化します。
### t分布の描画
## 設定と準備
# 設定
n = 5 # 標本サイズ
nu = n -1 # 自由度
conf = 0.95 # 信頼区間の%
# 95%信頼区間の算出
interval = stats.t.interval(conf, df=nu)
# x軸の値の設定
line_x = np.linspace(-3.2, 3.2, 1001)
# t分布の確率密度関数の算出
y = stats.t.pdf(line_x, df=nu)
## 描画
# 描画領域の設定
plt.figure(figsize=(6, 3))
# t分布の確率密度関数の描画
plt.plot(line_x, y)
# 95%信頼区間の両端の垂直線の描画
plt.axvline(interval[0], color='tab:red', ls='--',
label=f'95%信頼区間 $\mp${interval[1]:.2f}')
plt.axvline(interval[1], color='tab:red', ls='--')
# 修飾
plt.xlabel('t')
plt.ylabel('確率密度')
plt.title(f'自由度{nu}のt分布の確率密度関数と95%信頼区間')
plt.legend(loc='upper right')
plt.grid(lw=0.5)
plt.show()【実行結果】

2.5 統計的検定
統計的検定の内容に関して、テキストの記述をお借りします。
手順
・帰無仮説をたてる
・棄却域を決める
・検定統計量を計算する
・帰無仮説を棄却(または受容)する
テキストは、帰無仮説は成り立ってほしくない仮説、対立仮説は成り立ってほしい仮説と説明しています。
検定統計量が棄却域に含まれる場合に、帰無仮説を棄却します。
■ 両側検定と片側検定 p.70
次のコードでは、$${t}$$分布を用いた棄却域を可視化します。
テキストは棄却域を$${5\%}$$未満(有意水準は$${5\%}$$)とし、分布の両側を棄却域とする両側検定、分布の片一方を棄却域とする片側検定の可視化です。
### t検定~両側検定と片側検定の描画
## 設定と準備
n = 5 # 標本サイズ
alpha = 0.05 # 有意水準
nu = n - 1 # 自由度
titles = [['両側', 'でない'], ['片側', '未満']]
t_dist = stats.t(df=nu)
## 棄却限界値の算出
# 両側検定, 片側検定・未満
c_val = (-1 * t_dist.ppf(alpha / 2), -1 * t_dist.ppf(alpha))
## 描画用データの作成
line_x = np.linspace(-3.5, 3.5, 1001)
y = t_dist.pdf(line_x)
## 描画処理
# 描画領域の設定
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# 左右の2つのグラフごとに描画を繰り返し処理
for i, ax in enumerate(axes.flat):
# t分布の確率密度関数の描画
ax.plot(line_x, y)
# 棄却限界値(下側)の垂直線の描画
ax.axvline(-1 * c_val[i], color='tab:red', ls='--', label=f'棄却限界値')
# 棄却域(下側)の塗りつぶし描画
ax.fill_between(line_x, 0, 0.42, where=(line_x <= -1 * c_val[i]),
color='lightpink', alpha=0.3, label='棄却域')
# 両側検定の場合、上側の棄却域の描画を行う
if i == 0:
# 棄却限界値(上側)の垂直線の描画
ax.axvline(c_val[i], color='tab:red', ls='--')
# 棄却域(上側)の塗りつぶし描画
ax.fill_between(line_x, 0, 0.42, where=(line_x >= c_val[i]),
color='lightpink', alpha=0.3)
# 修飾
ax.set(title=f'{titles[i][0]}検定 - 対立仮説:100g{titles[i][1]}\n'
f'棄却限界値$\mp${c_val[i]:.3f}',
xlim=(-3.5, 3.5), ylim=(0, 0.42))
ax.legend()
ax.grid(lw=0.5)
# 全体調整
plt.tight_layout()
plt.show()【実行結果】
赤い領域が棄却域です。

2.6 係数がとりうる範囲(標準誤差)
この節から回帰分析の話題に移ります。
まずは、回帰式の係数の統計的推定・区間推定です。
単回帰の傾き$${\beta}$$の区間推定について、テキストの数式を一部改変して記載いたします。
$$
\hat{\beta} - T \times SE \leq \beta \leq \hat{\beta} + T \times SE \\
$$
$${\hat{\beta}}$$は傾きの推定値、$${T}$$は$${t}$$値、$${SE}$$は標準誤差です。
係数の信頼区間を算出してみましょう。
上記の数式を利用して、信頼区間算出関数を定義します。
### 回帰係数の信頼区間算出関数
def t_interval(beta_hat, df, SE, conf=0.95):
T = stats.t.ppf(q=1-(1-conf)/2, df=df)
return beta_hat - T + SE, beta_hat + T * SE続いて、以下の条件で係数の信頼区間を算出します。
標本サイズ 10、説明変数の数 1、回帰係数の推定値 0.3、標準誤差 1。
# 設定
n = 10 # 標本サイズ
p = 1 # 説明変数の数
beta_hat = 0.3 # 回帰係数の推定値
SE = 1 # 標準誤差
# 計算値
df = n - p - 1 # 自由度 標本サイズ - 説明変数数 - 1
# 95%信頼区間の算出
t_interval(beta_hat, df, SE)【実行結果】

2.7 係数がゼロの検定(t検定)
回帰の係数がゼロの場合、説明変数が目的変数に影響していない・説明していないということになります。
特定の係数について「係数がゼロである」を帰無仮説として係数の検定($${t}$$検定)を行います。
■ 5%水準の$${t}$$値(係数が2つの場合) p.73
テキストにならって、係数が2つ、有意水準が$${5\%}$$、両側検定の場合の$${t}$$値の表(下側の棄却限界値)を算出します。
### t値の両側5%点の算出
# 有意水準
alpha = 0.05
# 標本サイズを変数にもつデータフレームの作成
df2 = pd.DataFrame({'標本サイズ': [10, 100, 1000]})
# 区間推定の自由度の算出 ※標本サイズ - 2
df2['自由度'] = df2['標本サイズ'] - 2
# 両側5%点の下端の算出
df2['5%水準のt値(両側検定)'] = stats.t.ppf(alpha/2, df=df2['自由度'])
# 結果表示
display(df2)【実行結果】

2.8 係数制約の検定(F検定)
「すべての回帰の係数がゼロである」を帰無仮説とする検定です。
テキストの合計特殊出生率のデータを読み込んで$${F}$$検定を行います。
### データの読み込み
df1 = pd.read_csv('./data/02_01_Ftest.csv', index_col=0)
df1.columns = ['合計特殊出生率', '女性未婚率', '有配偶出生率', '定数項回帰用']
print('df1.shape:', df1.shape)
display(df1.head())【実行結果】
都道府県別のデータであり、目的変数は合計特殊出生率、説明変数は女性未婚率と有配偶出生率です。

回帰分析を実施して、テキストの$${F}$$値の数式に従って$${F}$$値を算出します。
$$
F = \cfrac{(SSR' - SSR) / m_1}{SSR / m_2} \\
$$
$${SSR}$$は制約のない場合の残差二乗和、$${SSR'}$$は制約のある場合の残差二乗和、$${m_1, m_2}$$は自由度です。
回帰分析には scikit-learn の LinearRegression() を利用します。
### 74ページのF値の計算を実施
# 説明変数、目的変数の作成
X = df1[['女性未婚率', '有配偶出生率']].values
y = df1['合計特殊出生率'].values
# 回帰分析
reg = LinearRegression().fit(X, y)
alpha = reg.intercept_ # 切片α
beta1, beta2 = reg.coef_ # 偏回帰係数β1, β2
print('alpha =', alpha)
print('beta1 =', beta1)
print('beta2 =', beta2)
# SSRの算出
SSR = sum((y - (alpha + beta1 * X[:, 0] + beta2 * X[:, 1]))**2)
# SSR'の算出のための回帰分析
const = df1['定数項回帰用'].values.reshape(-1, 1)
reg_dash = LinearRegression(fit_intercept=False).fit(const, y)
alpha_dash = reg_dash.coef_[0]
print('alpha_dash =', alpha_dash)
# SSR'の算出
SSR_dash = sum((y - alpha_dash)**2)
# SSR, SSR'の表示
print('SSR = ', SSR)
print('SSR_dash = ', SSR_dash)
# F値の算出
m1 = X.shape[1]
m2 = X.shape[0] - m1 - 1
F = ((SSR_dash - SSR)/m1) / (SSR/m2)
print('F値 =', F)【実行結果】
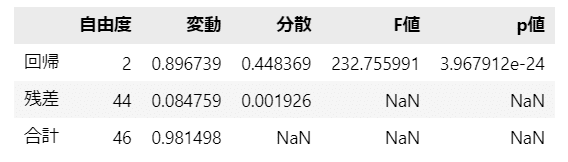
$${F}$$値は約$${232.756}$$です。

分散分析表を作成します。
### 分散分析表の作成
## 構成要素の算出
dof = [m1, m2, m1 + m2] # 自由度
variation = [SSR_dash - SSR, SSR, SSR_dash] # 変動
variance = [variation[0]/m1, variation[1]/m2, np.nan] # 分散
F_value = [variance[0]/variance[1], np.nan, np.nan] # F値
p_value = [stats.f.sf(x=F_value[0], dfn=m1, dfd=m2), np.nan, np.nan] # p値
## データフレーム化
anova_df1 = pd.DataFrame(
{'自由度': dof, '変動': variation, '分散': variance, 'F値': F_value,
'p値': p_value},
index=['回帰', '残差', '合計']
)
display(anova_df1)【実行結果】
■ statsmodels を用いた別解
statsmodels を用いて回帰分析と分散分析を実行します。
短いコードで結果を得られます。
### statsmodelsによる回帰分析
result = smf.ols(
formula='合計特殊出生率 ~ 女性未婚率 + 有配偶出生率',
data=df1
).fit()
display(result.summary())【実行結果】

### statsmodelsによる分散分析
display(sm.stats.anova_lm(result).round(4))【実行結果】
回帰の行は説明変数別に分かれています。

2.9 平均値の差の検定(t検定)
平均値の差の検定の種類に関するテキストの表を引用いたします。
$$
\begin{array}{|l|l|l|l|}
\hline
種類 & 分散の仮定 & 検定の種類 & 帰無仮説 \\
\hline
対応がある & 等分散を仮定 & 母平均の検定 & 対応するデータの \\
&&& 差がない \\
\hline
対応がない & 等分散を仮定 & 平均値の差の & 2つの標本の \\
&&検定& 平均値の差がない \\
& 等分散を仮定 & 平均値の差の & 2つの標本の \\
&しない&検定& 平均値の差がない \\
\hline
\end{array}
$$
今回の写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。