
自然言語処理(NLP)について知りたくなったら。

お久しぶりです。
データテクノロジーラボです。
今回は「自然言語処理」について定期的に投稿していこうと思います。
概要から実際に書いてみたり、(実力が追い付けば)高度なチャットボット的なものまで「自然言語処理を学習する過程で困ったらここ!」みたいな位置までたどり着けば泣こうと思います。
初回は「自然言語処理ってそもそもなに?」から。
(概要だけ知りたい方は①と②だけで大丈夫です!)
①自然言語処理とは?
一文で言うと、以下です。
人間の言葉をコンピュータが読み取れるようにする処理(いずれは自然に会話したり、話し相手になったり)のこと
自然言語(我々が使う言葉。英語から日本語から人が話す言語)を(コンピュータが)処理するという意味で、「自然言語処理」ですね!
NLP (Natural Language Processing)ともいわれまして、書店などのコンピュータのコーナーにも「NLP」という言葉が入った書籍もチラチラ見るようになりました。
(単に、自分が最近自然言語という言葉を知ったがゆえのカラーバス効果ともいえます)
現在はSiriやGoogle アシスタント、アレクサなど音声同士の会話が徐々に実用化され始め、チャットボットなどでは実際に企業も導入しています。
日本では少し前に女子高校生の「りんな」が話題になったことは記憶にある方もいるかもですね
(知らぬ間に曲出してる。。)
②どこに使われているか?
ざっくりと羅列すると
・検索エンジン
・予測変換
・機械翻訳
・音声アシスタント
・チャットボット
etc..
挙げれば(五条悟の「無下限呪術」くらい)無限ですが、実はもう身近に自然言語処理はいるんですね。。
③自然言語処理をしたくなった時に必要なもの
自然言語処理を動かす前に必要なものは2点。
・辞書(機械可読目録 「辞書」でいいです笑)
・コーパス(自然言語の文章を構造化たもの)
※正確な説明をすると長くなる(眠くなる)ので、簡略に説明しています
SNSの普及から、ネットスラングや独特の表現など造語が日に日に生まれていて、機械がある程度知っている辞書だけでは限界があります。
そこで、定期的に辞書を更新して「こういう単語があったら、区切らないでね」と命令する必要があります。
コーパスは正しく説明すると、
言語学において、自然言語処理の研究に用いるため、自然言語の文章を構造化し大規模に集積したもの。
(wikipedia参照)
となりますが、最初のうちは「解析したい文書」くらいでいいと思います。
④自然言語処理の仕組み・流れ
では、準備が整ったとき、どのようなことをコンピュータはしているのかというと、以下の4つとなります。
・形態素解析
・構文解析
・意味解析
・文脈解析
・形態素解析
文章を最小構成の単語(これを形態素といいます)に分けてばらばらにして、それぞれの単語に品詞の情報や原型の単語などの情報を付与する方法です。
例を挙げると、展示されたプラモデルを開封前のパーツに分解する作業だとわかりやすいですかね?
実際の例を挙げると
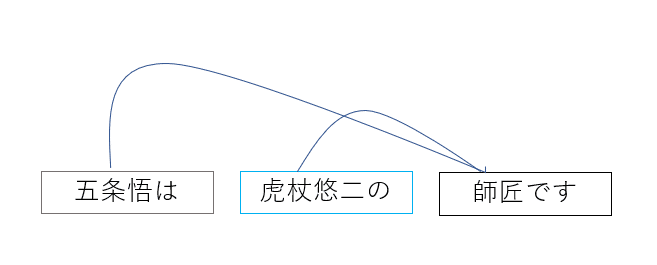
「五条悟は虎杖悠仁の師匠です。」
という文章で考えます。
形態素解析をすると、
「五条悟 は 虎杖悠仁 の 師匠 です 。」
と分解されます。
※多分「五条悟」とかはコンピュータは読み込んでくれないので、先ほど説明した辞書に「五条悟」を辞書として入れるなどの工夫が必要です。
・構文解析
係り受け解析とも呼ばれますが、形態素解析した各単語がそれぞれどの単語に関係(係り受け)しているか?を解析します。
先ほどのプラモデルで例えるならば、「どのパーツとどのパーツをつなげる必要があるのか?」って感じです。
・意味解析
だいたいここまででパーツがそろってきたところで、ちゃんと適切な場所に配置して意味を成すように組むことを意味解析はします。
正しく言えば、辞書に基づき、文章を適切な文として解析すること、です。
(プラモデルを作った経験がない自分が頻繁にプラモデルの例を出してますが、)腕を作れても、それを「腕」として装着しなければプラモデルは完成しないイメージでしょうか。
例えば、「私は今日五条悟と運動しました。」という文を考えたとき、
・私は、今日五条悟と、運動しました。(五条悟という人と、運動した)
・私は今日、五条悟と運動しました。(五条悟という動作と、運動をした)
というパターンが考えられます。
しかし、ここでコンピュータは辞書を用いて、
・五条悟は「名詞」である
・五条悟は「しました」と関連性が低い
・「私」は「しました」と関連性が高い
ということを判別し、前者の文章を採用する方が正しいと判別します。
・文脈解析
最後は、複数の文章に先ほどまでの流れを順次行い、文章同士でどのような関係性を持つのか?を解析します。
この文脈解析は特に日本語では難しく、例えば、「商品を買ったけど、とても腹立たしい対応をされた。品質は良かったので、最終的に満足した。」みたいな文章は、結局のところ「満足している」ということになります。
しかし、前文ではマイナス表現があります。
また、品質は良かった、というのは「買った商品の」品質であるなど、単語が抜けたりしています。
これくらいであれば簡単ですが、とても長い文章になると複雑性が増し、現代でも世界で機械学習をはじめとして、研究や訓練が行われています。
・終わりに
詳細な説明や専門用語などはなるべく避けた説明のため、厳密性に欠けているかもしれませんが、あくまで何も知らなかった人が興味を持っていただければ嬉しい限りです。
次回以降から、実際にコードを書いてみたりもしようと思います~
では、またお会いしましょう。