
どうやって「てんかん症候群」情報を世界から集めているの?

結構、患者さんおよび医療関係者など多くの方々から質問を頂いている”INSIGHTX LIBRARY”のお話をさせて頂いています。
AIチャット(例:ChatGPT)は確かに高い情報処理能力を持ち、幅広い質問に答えることができますが、その回答は主にネット上の情報に基づいています。しかし、インターネット上の情報には誤ったものや信頼性に欠けるものも含まれます。
そのため、InsightXでは特に医学や医療分野では、正確性が最優先されるため、これらの情報をそのまま利用してアドバイスを提供するのは適切ではありません。
不確かな情報が患者の健康や安全に重大な影響を及ぼす可能性があるため、信頼できる専門家や公式な医療機関の情報を基に対応する必要があります。
InsightXでは、AIが提供する情報の正確性を高めるために、RAG(Retrieval-Augmented Generation)という手法を採用しています。この手法は、AIが回答を生成する際に、事前に信頼できるデータベースから関連情報を検索して活用する仕組みです。InsightXでは、これらの情報を高品質なベクトルデータとして保存し、日々更新を続けています。このプロセスにより、ネット上の不確かな情報に依存するのではなく、正確性が保証されたソースに基づいた回答を提供できるのです。RAGを活用することで、信頼性と透明性の高い情報提供を実現しています。
そのインフラストラクチャーを図にすると下記のようになります。
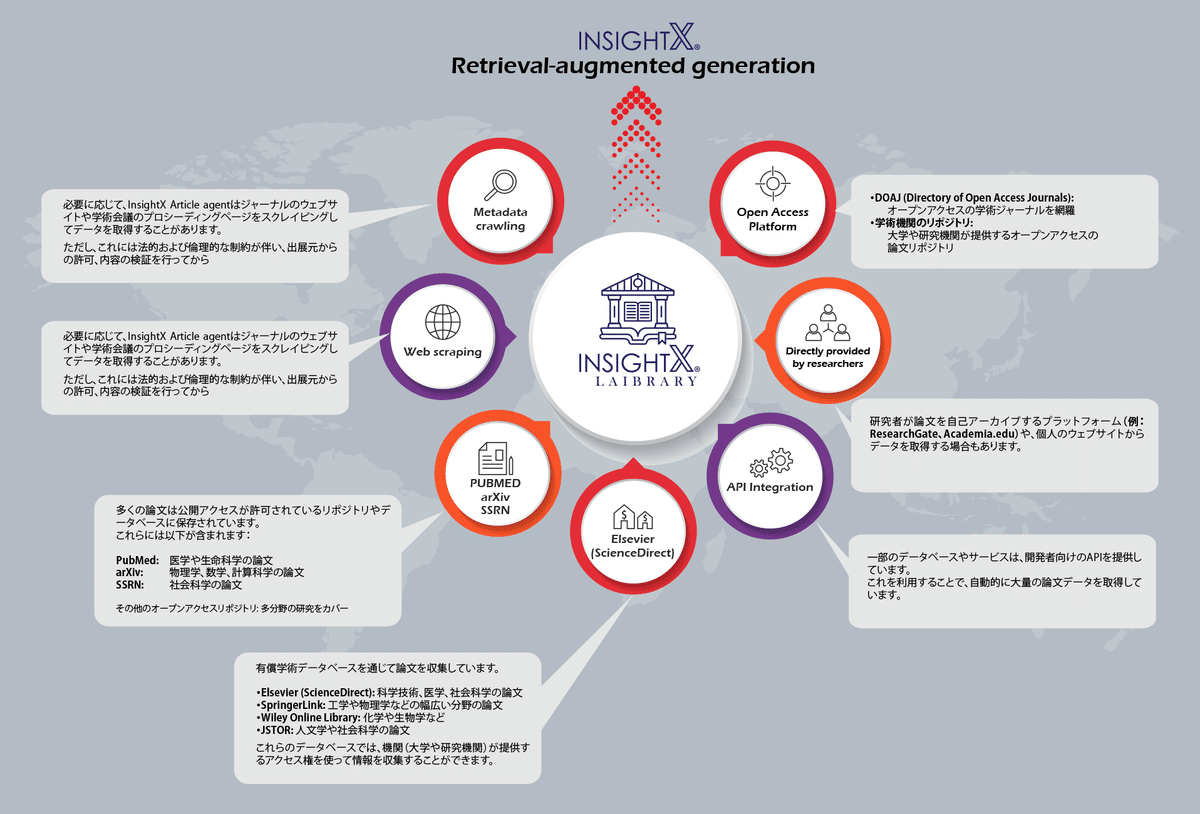
InsightXの運営団体は、1990年から世界中で医療情報システムの設計に携わっており、豊富な情報源へのアクセスが可能です。また、「てんかん症候群情報」はAIロボットによって日々収集されており、情報の規模において他を圧倒する優位性を持っています。
InsightXが目指す医療DXの未来:RAG技術を活用したてんかん治療情報の進化|InsightX
1. 公開データベースからの収集
多くの論文は公開アクセスが許可されているリポジトリやデータベースに保存されています。これらには以下が含まれます:
PubMed: 医学や生命科学の論文
arXiv: 物理学、数学、計算科学の論文
SSRN: 社会科学の論文
その他のオープンアクセスリポジトリ: 多分野の研究をカバー
Article agentはこれらのリポジトリにアクセスして、APIやウェブスクレイピング技術を用いて論文を取得します。
2. 購読ベースのデータベース
購読が必要な学術データベースを通じて論文を収集しています。
具体的には:
Elsevier (ScienceDirect): 科学技術、医学、社会科学の論文
SpringerLink: 工学や物理学などの幅広い分野の論文
Wiley Online Library: 化学や生物学など
JSTOR: 人文学や社会科学の論文
これらのデータベースでは、機関(大学や研究機関)が提供するアクセス権を使って情報を収集することができます。
3. オープンアクセスのプラットフォーム
DOAJ (Directory of Open Access Journals): オープンアクセスの学術ジャーナルを網羅
学術機関のリポジトリ: 大学や研究機関が提供するオープンアクセスの論文リポジトリ
4. ウェブスクレイピング
必要に応じて、Article agentはジャーナルのウェブサイトや学術会議のプロシーディングページをスクレイピングしてデータを取得することがあります。ただし、これには法的および倫理的な制約が伴います。
5. 研究者からの直接提供
研究者が論文を自己アーカイブするプラットフォーム(例:ResearchGate、Academia.edu)や、個人のウェブサイトからデータを取得する場合もあります。
6. APIによる統合
一部のデータベースやサービスは、開発者向けのAPIを提供しています。これを利用することで、自動的に大量の論文データを取得できます。
7. メタデータのクローリング
CrossRefやORCIDなど、論文のDOIやメタデータを管理している団体から情報を取得して、リンクをたどることで対象の論文に到達することが可能です。
いただいたご質問への回答として十分かどうかは分かりませんが、オープンマインドを大切にするInsightXにも一部非公開の情報がある点はご了承ください。
いいなと思ったら応援しよう!
