
【デブサミ2020】セッションレポート:14-B-2 守りのモニタリングから攻めのモニタリングへ

攻めのモニタリングとは何なのか
登壇:大谷 和紀[New Relic]さん
得意な芸風はLTなのでこの長さのセッションはちょっと辛い、とのことw
ブースには個性的なメンバーがいる、とのことなので後で寄ってみよう。
感謝から始まるセッション、素敵だ。

「攻めのモニタリング」というタイトルに惹かれ、こちらのセッションを選択。
New Relicについて
・業界最大手の最も包括的なクラウドベースの可観測性プラットフォーム

・グローバルで17000社以上
・20億イベント/分
相当数のデータ処理が走っていることがわかる。
・SanSanはAPMを活用してパフォーマンスを劇的に改善させた
・古巣のZucksでも使われている
オブザーバビリティ成熟モデル
導入企業で最初から劇的な効果が得られたわけではない
最初は何もわからないところからスタートする
段階的に成熟する

まず、何を計測すればよいのだろうか
SRE本より
・Latency
・Traffic
・Errors
・Saturation
何をもってして「正しく動いている」とするか
・テストして期待値通りの動きをする
・想定通りのエラーレートか
・いろいろあるが、関心ごとによって計測対象は微妙に異なる
従来の監視は「動いているか動いていないか」
オブザーバビリティは「どう動いているのか」
従来の監視だと「エラーが出てないのに動かない」「CPUの負荷が一時的に上がったけど収束したあとに何があったかわからない」といった問題点がある。あるある。めっちゃある。
オブザーバビリティ4つの柱
Metric
Event
Log
Trace
「イベント」があるのが、New Relicの特色であり強みとのこと。
ここからデモになった。


あやしいのがあったら・・・

詳しく追って・・・
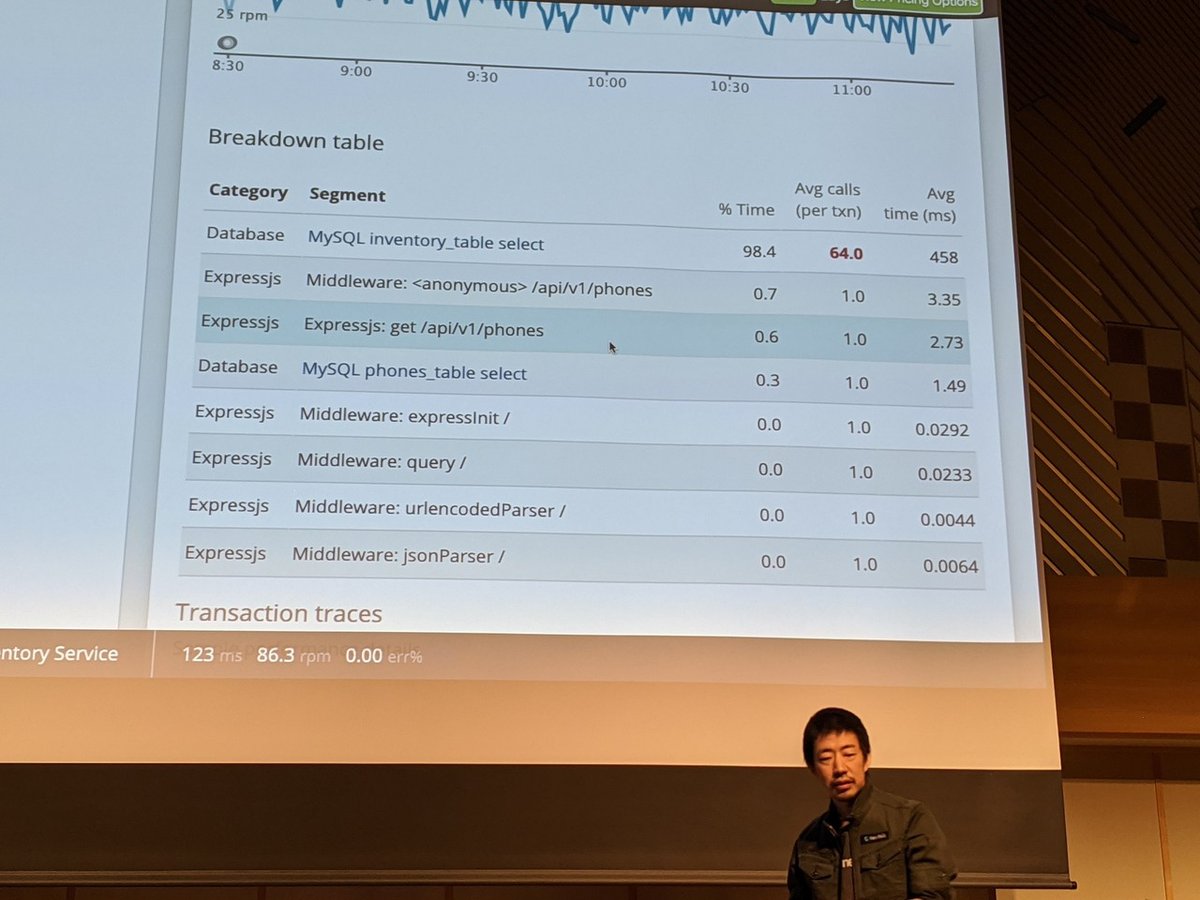
特定のsqlが悪さしてそう、というのを捕まえることができる。
この粒度で、本番環境でプロファイリングできるのはすごい。
机上でのプロファイリングだと、検証リクエスト単体ではわからない負荷やボトルネックを再現できない。これなら本番で検査できるのか。
積極的対応
アラートにはならないけど不安定な挙動
コントロールしづらい。なるべく不安定な挙動を除去したい

たとえば、普段200msのものが300msになってたら、何かが起こっている。しかしアラートは上がらないし、原因究明も難しい
予測的対応
ちょうどよいスケーリング
避難訓練
実験的デプロイ
安定した挙動じゃないと、リソースを最適化することは難しい。安定していると必要な分だけ用意すればよい。なのでコスト削減につながる、というのは確かに。安全のため多めに用意しておこう!ってやりがちなプラクティスだ。
「サービスレベルを定義していれば、避難訓練は本番でできるはずだ」これは同意しつつも、心理的ハードルを超えていくのが難しそうだと感じた。そのハードルを超えるには、やはりそもそも安定させるというのが大切なのだろう。

データ駆動
デプロイの評価
顧客満足の向上
「プロダクトバックログの改善に役立てられる」といわれると、興味持たずにはおられないですな。
まとめ

「みたい人はブースにきてください」は笑った。
ツールだけではなく文化も育てていこう
コードを書いてパフォーマンスをあげていくのは、現場の人だ
大谷さんのいい感じに力が抜けたトークと、ガチなモニタリングの話のコントラストがよかった。攻めのモニタリング、俄然興味が湧いてきた。