
【画像生成AI】Stable Diffusion 3はここまで進化した!現状の性能と今後の可能性を探る 📝

こんにちは!AI-Bridge Labのこばです😊
今回は、最新の画像生成AI「Stable Diffusion 3(SD3)」を実際に使ってみた感想をお伝えしたいと思います。
生成してみた画像も掲載しますので、他に試してほしいことなどリクエストがあればコメントでお知らせください!
▼最新情報!
ローカル版 Stable Diffusion3 Mediumの使い方はこちら
1.SD3を使うには?
現在、SD3を使うには主に2つの方法があります。
Google Colabで動かす
https://colab.research.google.com/github/stability-ai/stability-sdk/blob/main/nbs/SD3_API.ipynbFireworks.aiで動かす
https://fireworks.ai/models/stability/sd3
どちらの場合も、Stability AIのディベロッパーサイトからAPIキーを発行し、利用料金を支払う必要があります。料金は1リクエスト当たりのAPI使用料で、最小単位は10ドル(約154回の画像生成が可能)からとなっています。
ただし、これはあくまでAPIアクセスの料金体系です。将来的には、従来のSDシリーズ同様オープンソース化されて無料で使えるようになると思います(商用利用には月額メンバーシップが必要)
2.実際に生成してみた画像例
では早速、SD3で生成した画像をいくつかご紹介します。
プロンプトはポジティブプロンプトとネガティブプロンプト両方使えます
今回はFireworks.aiで生成してみました。とても分かりやすいUIで、Stable Diffusion WebUIを使い慣れている方ならすぐに使えると思います。

2-1.◆リアル系 人物画像
瓦礫の街に立っている2人の女性、シリアスな雰囲気と心配げな表情を浮かべています。上の画像はStable Diffusionと描かれたTシャツと、3とだけ描かれたTシャツに分けようとしましたが、そこまではうまくいきませんでした。下の画像はStable Diffusionの文字をテロップみたいに浮かべようとしましたが、スペルミスがあります。

A scene from a drama, with a serious atmosphere. The main character, happy smile,girl,close-up, She is standing in Cyberpunk City. The movie's lighting effects,One person is wearing a T-shirt with "Stable diffusion" written on it, and the other is wearing a T-shirt with "3" written on it.

A scene from a drama, with a serious atmosphere. The main character, happy smile,girl,close-up, She is standing in Cyberpunk City. The movie's lighting effects have large letters "Stable Diffusion 3" floating in the credits.hyper realistic,RAW photo,

Midjourneyよりもアジア人寄りな感じに作れそうです。
2-2.◆アニメ系 人物画像
2Dアニメと3Dアニメ系で作ってみました。
普段SD1.5やSDXLの構図に見慣れているので、また一つ進化している感があります。表現力がとても豊かで、Midjourney V6と並ぶかそれ以上かもしれません。ただ、体が崩れることも多いので安定感はMidjourneyの方があるかなという印象です。

2D anime of a smiling young woman in a red floral dress, with long curly hair adorned with pink flowers, walking through a fantasy scene with colorful flower petals blowing in the wind, romantic and dreamy atmosphere, high quality

3d render of a smiling young woman in a red floral dress, with long curly hair adorned with pink flowers, walking through a fantasy scene with colorful flower petals blowing in the wind, romantic and dreamy atmosphere, high quality

Text to ImageとImage to Imageの両方で試してみましたが、どちらも非常に高品質な画像が生成できました。
2-3.◆その他
他にもいろいろ出してみました。
表情や造形がとても自然で、リアル系のファインチューニングモデルが出てきたらもう写真と区別がつかないぐらいになりそうですね。

Portrait of a smiling young japanese woman with long dark hair,beautiful girl, wearing a bright yellow "good morning" t-shirt, brown high-waisted pants, and a light colored wide-brimmed sun hat, walking happily down a busy city street, 85mm portrait lens, shallow depth of field,hyper realistic,8k


という感じのかなり複雑なプロンプトでもきちんと反映してくれました。

この混み具合がプロンプトだけで出せるのはSD3だけかもしれません。

3.Text To Imageの使い方
3-1.APIキーの発行と入力
Stability API Keyの部分にAPIキーを入れる必要があります。
これは下記のディベロッパーサイトにログインして、すぐに発行できます。
ただし、最初に使用できるクレジットは僅かなので利用する場合はディベロッパーサイトのBillingから画像生成用のクレジットを購入しましょう。
Fireworksの場合はこちらからアクセス
3-2.設定
シード値、出力形式、アスペクト比を選択します。
・Seed
作品を固定したい場合は指定してよいですがランダム生成する場合は0で大丈夫です。
・Output Format
ファイルの保存形式です。None,jpeg,Pngから選べます
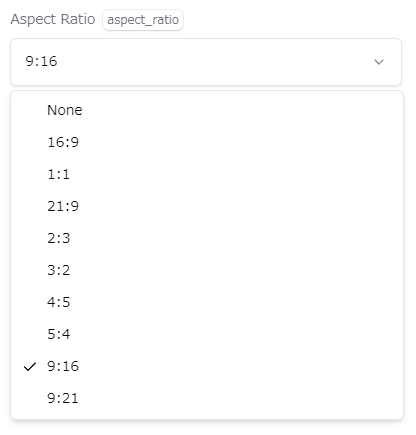
・Aspect Ratio
画像の縦横比です。横長のYoutubeサムネサイズに作りたければ16:9、人物の全身絵など縦長の画像が欲しければ9:16や9:21で設定してください。
3-3.プロンプトを入力
上段がイメージプロンプト入力欄、下段がネガティブプロンプト入力欄
それぞれ入力してGenerateボタンを押せば生成されます。
イメージプロンプト
生成したい画像のイメージをテキスト入力します
ネガティブプロンプト
生成したくない画像のイメージをテキスト入力します

4.SD3の性能に対する率直な感想
SD3を使ってみて感じたのは、とにかくプロンプトの理解力の高さです。文章でも、カンマ区切りの単語でもかなり高い精度で画像化してくれました。
(:1.2)などの強調構文はあまり反映されている感じが無く、Midjourneyっぽさを感じました。
文字の描画についても、英語の短い単語なら90%以上の精度で描画できていました。ただし、日本語はまだ生成できなさそうです。英語でも、長すぎる文章だとエラーが出ることがありました。

複数人物の描き分けも優秀でした。上でもご紹介しましたが「男性1人(紳士風)と女性2人(ドレス風)」といった具合に指定すると、しっかりと各人物を別々の特徴で描いてくれました。
一方、課題点としては、体の造形が崩れたり手の形がおかしくなったりすることがありました。ネガティブプロンプトで改善を試みましたが、完全には解消できませんでした。
5.SD3の将来性と今後への期待
現時点のSD3は、まだ完璧とは言えません。しかし、そのすさまじいプロンプト読解力には大きな将来性を感じます。
これからSD3がオープンソース化され、SD1.5やSDXLのようにコミュニティによるファインチューニングやモデル統合が進めば、今までと同様に安定感のある、自由度の高いモデルへと進化していくことと思います。
今後アップスケールやControlnetなどの拡張機能が使えるようになるのが楽しみです!
6.読者の皆さまへ
今回の記事はいかがでしたか?まだクレジットが残っているので、試してみたい画像のリクエストがあればぜひコメントでお知らせください!できる限り対応させていただきます。
AIBridge Labでは、こうしたAI技術を使ったビジネス活用事例なども多数ご紹介しています。もし生成AIの導入に興味がある方は、ぜひ参考にしてみてくださいね。
最後までお読みいただき、ありがとうございました!また次の記事でお会いしましょう😄

いいなと思ったら応援しよう!
