
「生成AIとSaaSの対比」 生成AIに関するレポート

1. 本note記事(生成AIの分析)について
こんにちは、DNX新田です。今回は主に生成AI×SaaSという観点から生成AIについて分析をしてみましたので、その分析内容をnote記事として出したいと思います。大前提として、生成AI領域の進化スピードは凄まじく、また、あらゆる関連分野で同時多発的に発生する全ての情報を正確に追うことは不可能なので、本内容が執筆時点の限定的な情報に基づく考え・分析であり、今後変わり得るものである点は予めご了承ください。また、本内容は2024年11月に開催されたB Dash CampのDNXセッションの内容がベースとなっており、基本的にB2B SaaSとの対比という観点で生成AIを分析しております。
2. サマリー
はじめに、本note記事でカバーする論点サマリー、およびそれに基づく生成AIスタートアップの勝ち筋をまとめたスライドが以下の通りです。


各章にてそれぞれの論点の詳細を記載したいと思いますが、まずは、そもそも生成AIとは何か?その特徴や強み・弱みは何か?という点について理解を深めたいと思います。
3. 生成AIの(B2B SaaSと比較した場合の)基本理解やその特徴
3-1. Distribution Channel
私が生成AIについて、対B2B SaaSという観点で最も重要なポイントと考えているのは、生成AIはそのDistribution Channelに変化がないという点です。海外VCの記事や各種リサーチなどでもよく、生成AIが過去のテック革命(ネット革命、クラウド革命、モバイル革命)になぞらえられることも多いですが、それらと大きく異なるのは、従前からのDistribution Channelに変化がないということだと考えています。
ネット革命であればインターネットという新たなDistribution Channelが生まれ、例えばそれまで紙ベースの商品カタログで注文していた通販がアマゾンをはじめとしたECに置き換わりました。また、クラウド革命ではそれまでエンジニアが顧客のもとに泊まり込みで作り上げていたようなオンプレ・ソフトウェアが、クラウドという新たなDistribution方法によってSaaSに置き換わりました。モバイル革命では人々がスマホという新たなDistribution Channelを手にしたことで、UberやAirbnbのようなスタートアップが生まれました。
これらに共通していることは、もちろんテクノロジー自体の革命はあったとは思いますが、それ以上にDistributionが大きく変化していることです。既存プレイヤー(Incumbent)の強みはすでに持っている大きな顧客基盤であり、Distribution Channelである一方、新しいテクノロジーに対して柔軟に対応することは難しさがあります。スタートアップはその逆で、新しいテクノロジーを積極的に取り込んでイノベーションを起こしますが、Distribution力がありません。このとき、過去のテック革命のように、Incumbent がもっているDistribution Channelとは異なるDistribution方法が生まれる場合にスタートアップに勝機が生まれます。
では、生成AIはどうでしょうか?生成AIアプリケーション(ex. ChatGPT)はWebやAPI、プラグインでの利用ですし、LLMモデルも基本的にはAPIベースで即アクセス可能です。つまり、従前のDistribution Channelから変化がなく、よって、既存プレイヤー(Incumbent)が容易に最新の生成AIテクノロジーにアクセスできている、というのが、過去のテック革命と比べたときに決定的に異なる要素だと私は思っています。そうするとスタートアップにとっては、容易に生成AIを実装してくる既存プレイヤーの動向を否が応でも注視せざるを得ず、生成AIという最新テクノロジーのみでIncumbentをディスラプトするのは(領域やユースケースをよく絞らない限り)難易度が高い、というのが生成AIスタートアップを取り巻く環境だと考えています。
3-2. Product-out Nature
3-1でも少し触れましたが、基本的に現在のLLMや生成AIアプリケーションはWebやAPIで誰でも簡単にアクセスできるものとなっています。言い換えると、現在の生成AIはまずOff-the-shelfのモデル・プロダクトがあり、そのOff-the-shelfモデル・プロダクトをユースケースに当てはめるというプロダクトアウトなアプローチとなっています。誰でもOpenAIやAnthropicなどのエンジニア精鋭部隊が作り上げた出来合いモデルに即アクセス可能であり、生成AI専門家でなくとも生成AIをプロダクトへ実装するだけならできてしまうというメリットがある一方、ユースケースの特定やOutcomeの検証がうまくいかず、PoCからなかなか本番フェーズに進まない例も多くあります。
他方で、従来型AIのマシーンラーニングでは、まずインプット・アウトプットの検討から入ります。つまり、初手がユースケースの特定に近く、その後、データ収集や整備、モデル学習、推論実行・Outcomeの検証を行い、パラメータをチューニングしていく流れです。技術の部分でいうと、想定ユースケースのもと、ビジネス上のOutcomeを検証しながらパラメータチューニングを繰り返すことで独自のアルゴリズムとなっていきますので、モデル自体の独自性や差別化は一定存在します。
一方、LLMは基本的に出来合いのOff-the-shelfモデル・プロダクトなので、モデル自体での技術的な差別化は難しく、当然ながら汎用的なLLMや生成AIアプリケーション(ex. ChatGPT)ではB2Bの具体的なユースケースやワークフローに当てはめづらく、Business Outcomeの創出までいかず、なかなかPoCから脱出しない問題が発生していると思っています。そうすると、必然的に企業内にある独自データの活用やモデル自体の微修正など、“既成モデル・プロダクトへの後付けカスタマイゼーション(ex. RAG, Fine-tuning)”が主戦場となりますし、ユースケースから逆算したときに「ここはこのLLMを使う」「ここはLLMではなくルールベースで対応する」などトータルソリューションとしてのアーキテクチャーが重要になります。つまり、Pythonを使ってアルゴリズムをゴリゴリ作れる能力ももちろん重要ですが、生成AI文脈ではそれ以上に、対象ユースケースの深いビジネス理解と、LLMの特徴を理解した上での後付けカスタマイゼーション、全体アーキテクチャー設計が勝負を分けると考えています。
3-3. B2B SaaSと比較した場合の長所・短所
ここで、生成AIの基本的な技術理解に立ち返りたいと思います。といっても、私は自然言語処理(NLP)技術や大規模言語モデル(LLM)の専門家でもなければAIエンジニアでもない単なる素人なので、厳密な意味での正確性はご容赦いただきたいのと、詳しい技術的な内容は他ソースに譲りたいと思います。
まず、LLMも広い意味ではNLPの技術領域だと理解しております。NLPの大前提として、自然言語を機械学習モデルで扱うには、文章や単語を計算可能な形で表現する必要があるため、自然言語における文章や単語を One-hotベクトル表現という形で計算可能な形で表現します(イメージ例: 犬 →(0,1,2,0))。ただし、これでは各単語の意味や概念の類似性をもたせることができないので、One-hot ベクトルに対して埋め込み行列を用いて、埋め込みベクトル化を行うことで、埋め込みベクトル空間上で各単語の近い遠いといった距離の概念や類似度、加算減算といった構造を与えます(イメージ例: 犬(0,1,2,0) + 小さい(0,0,0,1) = 子犬(0,1,2,1))。
次に、言語モデルは、自然言語の文章をその文章が生成される確率で数理モデル化したもので、LLMもこのような数理モデルがベースとなっております。大雑把にいうと、「今日 “は”天気が良い」という文には高い確率を与え、「今日“を” 天気が良い」という不自然な文章には低い確率を与えるというもので、文章Yの生成確率P(Y)は、条件付確率の積で定式化されます(イメージ例: Y=(y0,y1,y2)という文章の場合、P(Y)=P(y0)* P(y1 | y0)* P(y2 | y1,y0) )。
ここで、2017年にGoogleの研究者による「Attention Is All You Need」という論文でTransformerというモデルが登場します。Transformerは従来のネットワーク構造モデル(CNN や RNN 等)と比較して学習用データセットとして大量のデータが必要というデメリットはあるものの、登場以来 NLP の分野で革命をもたらした基礎モデルで、近年の大部分のLLMのベースになっている超重要モデルです。Transformer では、Attention構造のみをもつEncoder-decoder モデルで、この Attention 構造により、精度および学習速度ともに従来モデルからの大幅な向上を実現しております。ここで、Attention構造が非常に重要になるわけですが、大雑把にいうと、言語単位である各トークンにおけるQueryベクトル(問い合わせ用)、 Keyベクトル(索引用)、Valueベクトル(トークンの値)の3つでAttentionを数式化し、例えば「これをマウスでクリックしてください」という文章で、「マウス」というトークンから見たときに「クリック」というトークンのAttention数値を高くし、「マウス」の意味がパソコンで使用する入力機器のマウスであり、ネズミではないということを捉えています。

これまでの技術的な理解を踏まえ、私なりにB2B SaaSと対比したときのLLMの長所・短所をまとめたいと思います。まず長所ですが、以下のように考えております。
【LLMの長所】
① インプットの自由度が高い(動的条件、複数情報、未学習情報、マルチモーダル)
② アウトプットの自由度が高い(従来型のAIは予め想定・学習したタスクしか扱えない)
③ 言語間の意味の近似性や関係性を捉えるのが得意
④ 自然言語での高度な生成・推論・分析が可能
⑤ 自律性をもたせられる(ex. AI Agents)
まず、①と②にあるように、インプット・アウトプットの自由度が大変高いというのが大きな特徴だと思っています。従来型のAIは予め想定・学習したタスクしか扱えませんが、LLMでは未学習情報でもマルチモーダルでも複数の動的条件でもインプットし、アウトプットを出すことができます(SaaSは基本的にはRule-based Systemなので、インプット・アウトプットの柔軟性は限定的です)。さらに、上述のようにAttention構造により、言語の近似性や関係性を捉えるのが得意であり(③)、自然言語で高度な分析まで可能(④)なため、SQLなど非自然言語の知識は不要、さらに後段で触れますがAI Agentsのような自律性をもたせることもできます(⑤)。
他方で、SaaSと対比したときに短所もあります。
【LLMの短所】
① ハルシネーション
② データを溜めていくことができない(※RAGのような外付けDBは除く)
③ 過程がブラックボックス(インプット - アウトプットの関係性が不明)
④ (少なくとも現時点では)コストが相応にかかる
⑤ Output-oriented (not Outcome-oriented)
まず、LLM自体の精度向上やRAG等の組み合わせで直近はハルシネーションをかなり抑えられるようになっていますが、上述の通り本質的には条件付確率でアウトプットを類推しているだけなので、ハルシネーションを完全になくすことは難しく、また、アーキテクチャー上でのデータ蓄積やRAGのような外付けDBを除き、LLMそのものはOne-shotで類推しているだけなので、LLM単体ではデータを溜めていくことはできません。さらに、インプット - アウトプットの過程や関係性がブラックボックスなので、Foundation Modelのバージョンアップによる精度面での大きなジャンプやプロンプトの工夫による精度改善はありますが、SaaSでいう顧客フィードバックに基づく機能改善のような漸次的改善を積み上げていくことにはあまり向いていません。また、多くのトークンを消費する場合に少なくとも現時点では相応のコストがかかるため、SaaSほどMarginal Costが低くはなく、Scale of Economyがやや限定的かなとも思います(※他方で、LLMのコストは急激に下がっているので、近い将来気にならないレベルのコスト構造になる可能性は十分にあります)。
4. SaaS vs 生成AI
4-1. エンタープライズにおける生成AIおよびSaaSの位置づけ
SaaS vs 生成AIの論点の前に、エンタープライズにおいて生成AIとSaaSがどのような棲み分けになっているか、私なりの理解を概念的に共有したいと思います。まずは以下の概念図をご覧ください。

正確性というよりあくまでイメージ優先というヘッジはさせて頂いた上で、この図で表現したいことは、B2B文脈でのエンタープライズでは、業務ワークフローがあり、データが生まれ、そのデータがレコードされていくというSystem of Recordというレイヤーがあるというのと、そのデータを活用したApplicationとしてのインターフェースレイヤーがあるということです。
足元のエンタープライズにおける生成AI活用はあくまでApplicationとしてのインターフェースレイヤーでの活用が多く、RAGに代表されるような全体アーキテクチャーの設計によって、いかに企業内のワークフローから生じるデータを吸い上げるか・活用するかが焦点となっています。
他方、SaaSは、この図の一番右のようなイメージで、頻度の高い定型ユースケースを起点に、“(定型)ワークフロー、データ、インターフェース”を一気通貫で高速化・簡略化していることが価値です。ここで、“ワークフロー、データ、インターフェース”という要素が出てきましたが、SaaSは基本的にこれら要素を一気通貫でカバーしていますが、これら要素全てに強みがあるというわけではなく、SaaSによってどの部分に強みがあるかは異なります。その強みとするイチ要素でまず存在感を強め、協業や連携、製品拡充などで徐々に他要素にも強みを拡げていく進化を辿るわけですが、例えば、Googleが買収したLookerやSalesforceが買収したTableauは社内に散らばったデータに共通の分析可視化ツールを提供するという意味でインターフェースに強みがあるでしょうし、SalesforceはSystem of Recordとしての顧客データに強みがあり、また、飲食店の業務フローに深く入っているToastはワークフローに強みがあるSaaSと言えます。そして、このSaaSとして“どこに強みがあるか”が、生成AIにディスラプトされやすいのか、あるいはディスラプトされにくくむしろ生成AIを活用していく側なのか、を分けると考えています。
4-2. SaaS vs 生成AI: LLMの長所・短所から見るSaaSとの比較
ここで一度、3-3で触れたLLMの長所・短所の議論に戻ります。生成AIの長所は「インプット・アウトプットの自由度が高く、言語間の意味の近似性や関係性を捉えるのが得意であり、自然言語での高度な生成・推論・分析が可能で、自律性ももたせられる」という点です。この強みを踏まえると、B2B文脈でLLMのユースケースの方向性として、以下のようなものが考えられると思います。
大量の情報や雑多なデータ、複数のデータベースを横断し、これまで人間にできなかった示唆・分析・特定の情報を抽出するユースケース
高度な推論や分析を自然言語で可能にするユーザーインターフェースやコミュニケーション(System of Engagement)を抑えるユースケース
サービス業のような、人間とのインタラクションや非定型ワークフローを伴うタスクを自律的に実行していくユースケース
先ほどの4-1の議論の続きでいうと、生成AIは、「大量の情報を取り込み、人間には難しい示唆・分析・特定の情報を抽出できる」「高度な推論や分析を自然言語で可能にするユーザーインターフェースやコミュニケーションが可能」ということで、System of Recordレイヤーというより、インターフェースレイヤーに強みをもちます。
同時に3-3では、生成AIの短所について、LLMが本質的には条件付確率でアウトプットを類推しているだけなので、ハルシネーションを完全には排除できない点やLLM自体データを溜められない点に触れました。これらをSaaSとの対比でみると、LLMは条件付確率でアウトプットを類推しているだけであることから、明確な定型ワークフローやタスクはRule-base System(=SaaS)が優位だと考えます。また、アーキテクチャー上でのデータ蓄積やRAGのような外付けDBを除き、LLM単体ではSaaSのようなSystem of Recordとしてデータを溜めていくことはできません。つまり、定型ユースケースを起点にしたワークフローやSystem of Recordとしての役割はSaaSに軍配が上がります。
4-1のSaaSは「“ワークフロー、データ、インターフェース”を一気通貫でカバーしているが、どこに強みをもっているかはSaaSによって異なる」という点を合わせると、SaaS vs 生成AIの観点では、
インターフェースに強みをもつSaaSは生成AIにディスラプトされ得る一方で、定型ワークフローに深く入っているSaaSやSystem of Recordとして独自データが溜まっているSaaSは生成AIだけでリプレイスすることは難しい
逆に言うと、深く業務ワークフローを抑えること、価値あるデータを溜めることがSaaSプレイヤーにとって重要
すでにしっかりと定型ワークフローに入っているSaaS Incumbentsが、ユーザエンゲージメントを更に高めるために生成AIを補完的に活用することはあっても、その逆(=生成AIを活用すれば企業の定型ワークフローが抑えられること)は難しい
ということが言えるかと思います。

4-3. 既存SaaS Player(SaaS Incumbent)における生成AI実装について
3-1で触れたように、生成AI革命は過去のテック革命と比較したときにDistribution Channelに変化がなく、既存プレイヤー(Incumbent)が容易に最新の生成AIテクノロジーにアクセスできることが重要なポイントです。本章では、SaaS Incumbentがどのように生成AIを実装しているかSalesforceの事例を引用した上で、顧客基盤やデータがないスタートアップが生成AI機能だけを起点に戦ったとしてもそれは非常に不利な戦いになる点に触れたいと思います。
SalesforceはLLMを活用したAIプロダクト”Einstein”を実装しています。例えば営業メールを自動生成するという事例を考えてみます。営業メールを打つ際のベースになる情報はSalesforceのCRM内にあります。通常のLLM活用プロセスとしては、CRMにある情報や背景知識を用いたプロンプトを作成し、LLMにインプットし、営業メールというアウトプットが返ってくるというプロセスです。しかし、詳細なCRM情報や背景知識をプロンプトとして打ち込む工数がそもそもかかることに加え、情報漏洩やセキュリティ上の懸念があります。そこで、SalesforceではCRMデータを起点に工数なく自動でセキュリティも考慮した営業メールの自動生成を実装しています。具体的には、JSON形式のデータ要素をプロンプト・テンプレートに当て込み、CRMから具体データを割り当て、それを暗号化した上でOpenAIのLLMモデルにプロンプトとして投げます。LLMからのアウトプットに対してSalesforceのアプリケーション内で暗号を復元し、営業メールを自動作成、さらにLLM側のプロンプトは他に流用されることなくその場で削除、といった流れです。

ここで重要なことは、様々な営業活動の結果として顧客情報がデータとして溜まっているCRM(System of Record)がOpenAIのAPIを活用することで容易に生成AI機能を実装できていること、そして、System of Recordとしての独自データをLLMとシームレスに統合・活用することで、ユーザーの負担なく、一つのApplication (Interface)として営業メール自動生成という生成AIを活用したユーザー体験を提供している点です。
さらに、以下はSalesforceだからこそできるというレベルのものですが、CRMのデータだけでなく、他のデータソースもSalesforce Einsteinのプラットフォームを通して統合可能(=データベース機能)、さらに、プロンプト・マネジメント機能やオーケストレーション機能などもあり、生成AIに関連する各種ミドルウェアまで提供しています。

以上のSalesforceの事例を少し一般化すると、単一のData Sourceや単一System of Recordに依拠するWrapper型の生成AI-nativeスタートアップは、既に独自データをもつSaaS Incumbentにディスラプトされ得ると考えています。生成AI-nativeスタートアップにとっては、例えば複数Data Sourceや複数System of Recordを横断してデータや情報を抽出・分析するような、単一のData sourceやSystem of Recordでは出せない価値を提供することが重要となります。逆に、SaaS Incumbentにとっては、どのようなデータが溜まっているかが非常に重要で、そのデータとLLMを活用して顧客への新たな価値提供ができる場合、ARPA向上や更なるユーザエンゲージメントの向上を狙って生成AI実装を検討すべきかと思います。

5. LLM providerの動向
5-1. LLM provider概観
これまでLLMの長所短所に触れてきましたが、OpenAIを始めとした、LLMを提供しているLLM Providerについて少し分析してみたいと思います。
まず、上述の通りですが、基本的にLLMは、Transformerをベースにしたアルゴリズム上の技術革命である一方、過去のテクノロジーシフト(インターネットシフト、クラウドシフト、モバイルシフト)と大きく異なるのは、LLMのDistribution Channelに大きな変化がない点です。以下の表の通り、基本的にAPI経由での提供となっており、既存プレイヤー(Incumbent)も最新テクノロジーであるLLMを積極的に活用できています。

さらに、LLM開発は規模(≒資本力)が大きな差別化となっていましたが、直近は必ずしも資本力が全てを決める勝負ではなくなってきていると言えます(もちろん、資本力が重要な要素の一つであることは変わりませんが)。LLM Providerの中で業界トップランナーはOpenAIです。OpenAIが圧倒的な性能の最新モデルを出し、他社がそれに追随する形が長く続いてきました。そして、Open-source Community台頭もあり、
OpenAIが最新モデルで圧倒的性能を出す
➡他Closed-model Playerが同等性能モデルを作る(Gemini, Claude)
➡Open-source Modelで同等性能モデルを作る(Llama)
➡より小型のOpen-source Modelで同等性能モデルを作る(Gemma、Llama)
というような流れを直近は辿っており、最新モデルの技術も時間が立てばより小型で安価な同等性能のモデルで利用できるようになってきています。つまり、フロントランナーとしてのOpenAIでさえモデル自体の技術的な差別化を維持することが難しくなってきており、従い、各社ともOpen・Closeの別やターゲット、用途、価格など各社戦略に少しずつ違いが出てきているのがLLM Providerの大まかな現在地かと捉えています。
5-2. Closed-source vs Open-source
ここで、Open-sourceという言葉が出てきたので、Closed-source vs Open-sourceという観点で少し深掘ってみたいと思います。
まず、この議論をするにあたって避けては通れない事象が、2023年5月にGoogleの社内文書が匿名のgoogle社内研究者によってリークされたという事象です。その文書のタイトルが"We Have No Moat, And Neither Does OpenAI"というもので、当時GoogleはGeminiを中心にOpenAIを猛追していたときで、そのリーク内容が衝撃的で瞬く間に拡散されたそうです。
そのリーク内容についてですが、事の発端は、Metaが初の本格的なOpen-source LLM (LLaMA)を公開したことです。ただし当時、これは何のチューニングもRLHFもされていない非常にプレーンな原始モデルでした。しかしその後、全世界のエンジニアのチューニングによって数週間のうちに多種多様で高性能なモデルが数多く誕生し、中にはChatGPTと同等レベルのものまで出来上がってしまいました。さらに注目すべきはこのチューニングは、個人が一夜に安価に手元のlaptopでできるものだったことです。具体的には、Low Rank Adaptation(LoRA)と呼ばれるチューニング手法で、ざっくり言うと、既存パラメータを“凍結”し、Add-on部分だけをチューニングするような手法です。LLMの全パラメータをイチからチューニングするより遥かに軽くチューニングを実行できることに加え、LoRAが基本的にStackableであるという点が重要で、Open-source Communityにいる各人の小さな改善が積み重ねっていくことで非常に強力なモデルが生まれました。この状況を目の当たりにしたGoogle研究者が、
We have no secret sauce. Our best hope is to learn from and collaborate with what others are doing outside Google.
People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality.
Giant models are slowing us down. In the long run, the best models are the ones which can be iterated upon quickly.
という具合に、Open-source Communityの存在に危機感を覚え、ClosedなGiant Modelを作っている自社の未来を憂いたという内容だったようです。
ここで、私は2つの見方があると思っています。
一つは、このリークされたGoogle社内文書にあるように、Open-source Modelの発展は凄まじく、さらにそれが、個人が一夜に安価に(~$100)、手元のlaptopでできていることが示唆的であり、LLM ProviderがMoatにしていた巨大資本による技術的差別化が無効化され得る可能性です。
そしてもう一つは、LLMにおけるOpen-sourceというのが、例えばLinuxのようにソースコードがすべて公開されているというわけではなく、“真のOpen-source”ではないという点です。つまり、LLMにおけるOpen-sourceというのは、Open-sourceのモデルをダウンロードして推論実行するだけ、です。そもそもLLM Applicationはまず膨大なデータから原始モデルを作り、それを適切にチューニング・強化学習することで、ChatGPTのような“現実的に使える最終モデル”になります。Open-sourceが本来もたらす外部経済性(第三者による品質向上)はこのチューニングフェーズのみということであり、再現可能な形でLLMそのものの挙動を変更するのが難しいというのが、”Open-source”という言葉を額面通り受け取ってはいけない点です。
そして、Open-source Communityの台頭でチューニングフェーズ以降が民主化されたのは間違いないですが、依然として原始モデル自体の構築は大きな資本をバックにしたプレイヤー(ex. OpenAI、Google、Anthropic、Meta etc.)の独壇場とならざるを得ません。そして、“現実的に使える最終モデル”の性能差が原始モデルのトレーニングフェーズで生まれるのか、あるいはそれ以降のチューニングフェーズで生まれるのか、仮に後者の場合、原始モデルを構築する巨大資本をバックにしたプレイヤーも技術的なMoatを維持するのが難しく、Open-source Communityでチューニングされた安価モデルとのコストパフォーマンスの戦いになっていくと思われます。

5-3. Google
ここから、GoogleとOpenAIの2社に焦点を当てて、個社の動きを少しまとめたいと思います。まずGoogleですが、これまでGoogleは基本的にOpenAIを追従する形で生成AIプロダクトをリリースしてきました(ex. ChatGPT vs Gemini)。直近でも、OpenAIがCoTをコア技術としてリリースした推論モデル(OpenAI o1)に追従すべく、同様の推論モデルを開発中のようです。
一方、上述の23年にリークされた社内文書にあるように、Open-source Modelの台頭でGoogleの立ち位置は揺らぎ始め、その影響からか、24年2月には初となるOpen-source Modelをリリースしました。また、24年9月にはLLMの欠点であるハルシネーションに対応するためリアルデータを武器にしたOpen-source Modelをリリースしました。これまでClosedな戦略でApplication Layerで勝負をしていたGoogleですが、2024年に入り立て続けに従前とは異なる動きを見せており、(OpenAIにはない)Googleの本来の強みであるdataを起点にするような戦略転換の兆しが見えます。

5-4. OpenAI
続いてOpenAIですが、OpenAIは、その開発力を武器にGPT-4、OpenAI o1など最先端モデルを常に送り込んできた業界のフロントランナーです。ただし、上述の通り、その技術がキャッチアップされるのも早く、その永続性はやや疑問です。LLM技術のコモディティ化が今後進むとして、今のところOpenAIはLLMの肝となるデータソースを明確にはしていませんが、おそらくそのデータソースは限定的で、コンテンツプロバイダーとの事業提携に奔走しているのもそのためかと思料します。また、Distribution力も限定的で、例えばApple社がOpenAIの旗艦LLMであるGPT-4oをApple社OS利用者に無償提供していくと発表しましたが、本来iPhoneユーザーがChatGPTに質問するたびにOpenAIはGPUを使って推論するため限界コストは大きいはずですが、それでもOpenAIはこの協業に関してライセンス料を要求していないそうです。そうすると、目的は他のところにあり、OpenAI自体の販路が限定的であるため、協業を通じたAppleユーザーへの販路確保とみるのが自然かなと思います。このように考えると、巨大資本をバックにした技術的Moat以外に大きなMoatは今のところ見えづらく、5-2のOpen-source vs Closed-sourceで触れたように、ここの技術Moatが揺らぐ場合、OpenAIといえども盤石ではないと言えそうです。
そういう背景もあってか、OpenAIはモデル性能の向上だけでなく、APIや周辺機能の開発スピードが非常に早いのも特徴です。23年3月のChatGPTのAPI公開以降、 プラグインのリリース、外部API連携を可能にするActions、文脈の永続性や社内ファイルへのアクセス、制御フローを管理するAssistants、外部教師データの追加などオリジナルChatGPTを作れるGPTsなど、多くの周辺機能が開発され、ChatGPTで対応できるユースケースの拡大や開発者をはじめとしたユーザー体験を向上してきました。B2B向けには垂直統合型でのApplication Layerで勝負しようとしているとも受け取れ、今後もちょっとやそっとのユースケースであればChatGPTで十分対応できる状態(“ChatGPTでいいや問題”)を作る動きや、開発者向けadd-onやインテグレーションが充実したプラットフォームの動きを加速させていくと思われます。
生成AI-nativeなスタートアップ、特にApplication Layerで勝負しようとするスタートアップにとっての示唆としては、OpenAIのAPIに依存したWrapper appの生成AIスタートアップはOpenAIのアプリケーションに簡単にディスラプトされ得るということかと思います。上記4. “SaaS vs 生成AI”で触れた通り、SaaS Incumbentも生成AI機能を容易に実装できますので、生成AI Applicationで勝負する生成AI-nativeなスタートアップにとっては、そうした既存プレイヤーとの棲み分けも考えなくてはいけませんが、加えて、LLM Providerが提供するApplication (ex. ChatGPT)とも被る可能性があり、LLM Providerが提供するApplicationの動向にも注視する必要があるということかと思います。

6. B2Bにおける生成AIユースケースについて
6-1. Generativeから、Search/Syntheticへ
これまでLLMの長所短所に触れてきましたが、B2Bにおける生成AIユースケースについて少し考えてみたいと思います。まず、B2B向けでは、コンテンツを生成できるという”Generative”な側面だけではビジネス上の成果には繋がりにくいと考えています。LLMはハルシネーションをゼロにできないので、例えばメール返信のドラフトでも内容にミスがないかチェックが必要です。また、LLMは条件確率に基づいて文章をアウトプットしているだけで、Outcomeベースで出力しているわけではないので、ビジネス上の成果に繋げるためには、結局追加作業が必要となることが多いです(例:返信率が高くなるような営業メールのドラフトは難しく、結局セールスが付加価値を補足する必要がある)。また、しっかりとしたものをLLMにアウトプットさせようとすると、高度なプロンプトテクニックが必要となり、自然言語とはいえ、プログラミングと同じような労力が必要となり、そもそも効果的なプロンプトを書くためにはその領域の高度な専門意識が必要にもなるので、結局エキスパートの工数が取られてしまいます。そうすると、ナレッジワーカーにとって、コストパフォーマンスを考えると、結局「(生成AIを使わず)自分でやってしまう」という選択になりがちです。
私はB2BユースケースにおけるLLMの優れている点はむしろインプット側だと考えています。社内に散らばっている大量の情報や雑多なデータ、複数のデータベース / Systems of recordを一つに集約して読み込むことで、人間には難しい新たな分析や示唆を提供できる可能性(Synthetic)や、社内に乱立する複数システムを横断するone-stop interfaceとして、自然言語で情報にアクセス・分析できる可能性(Search)が考えられます。実際、a16zも生成AIの第二波としてSynthesis AIに注目していますし、国内大企業でも同じような方向性を模索している企業(例:日清食品)があります。

6-2. Service as a software
人間とのインタラクションや、非定型・動的なワークフローの多いサービス業はこれまでソフトウェアでの代替が難しかった領域ですが、生成AIの特徴である「自然言語、インプット・アウトプットの柔軟性、推論能力の高さ、自律性の高さ」は本来サービス業で活きる強みだと考えています。Sequoiaも「Service as a Software」という言葉を使って、生成AIが労働集約的なサービス業がソフトウェアに置き換わる可能性に言及しています。
中でも、すでに外部にアウトソースされているような人的サービス(ex. コールセンター)は、ある程度型化もしやすく、現時点のレベルの生成AIが取り組む領域として相性が良いかと思います。また、Vertical SaaSなどが業界固有の人的ワークフローを丸ごと受け取り、裏でAIを活用して効率的にタスクを遂行するAI-enabled BPaaSのようなユースケースの可能性もあるかと考えています。(生成AIに限らず)AIは喰わせるデータが品質に直結するため、基本的に領域特化でユースケースが限定されているほど差別化に繋がります。従い、業界特化ゆえに、データの密度が高く良質なデータが溜まりやすいVertical SaaSとAIは本来相性が良いと考えております。さらに、Vertical領域は、未だに労働力を前提とした業界固有のワークフローも多く残る一方、人材不足に苦しむ業界もあり、BPOの機会が多く存在します。しかし、Vertical SaaSにとって、BPOは労働集約的で低マージンかつスケールも難しいため、全体の出来上がりPLを考えたときにSaaS playerとしては取りづらい戦略です。しかし、生成AIの自然言語能力の高さやインプット・アウトプットの柔軟性を活かすことで、これまでエコノミクスの観点で採りづらかった、業界固有の人的ワークフローを丸ごと引き受けられる可能性があるかと思います。米国ではすでに様々な事例が出てきていますが、業界固有データを活用したVertical SaaSが、業界固有の人的ワークフローを丸ごと引き受け、裏で生成AIを活用しながら従来では実現できなかった圧倒的な効率性でBPO的にタスクを実行するVertical SaaSによるAI-enabled BPaaSは面白いユースケースの一つだと思います。

6-3. AI Agents
これまでの主な生成AIのユースケースは、Generation(コンテンツ作成)、Search(データ・情報の検索)、Synthesis(情報統合による分析・示唆)の3つでしたが、LLM自体の推論能力向上や外部データ活用のソリューションを提供するEnablerの台頭などがあり、特に2024年の生成AIを取り巻く話題として、AI Agentsは一つの大きなキーワードだったかと思います。
しかし、AI Agentsは何でもできる魔法ではなく、その限界やユースケースはしっかりと見定める必要があります。AI Agentsは動的な環境下でも自律的に業務を遂行できるのが強みであり、スケールアップも容易なため、急な需要下でも処理能力を柔軟に拡張できるのも利点です(例:事故直後の航空会社の電話窓口)。ただし、以下のPlan & Action型のアーキテクチャー例にあるように、AI Agentsに考慮させる環境範囲設定やツール選択、タスク順序、自己修正の粒度・タイミング設定など、事前定義項目が多く、Delivery工数はかなり大きくなります。

従って、AI Agentsの方向性としては、①個社最適・高単価の前提で、ハイタッチな導入支援でエンプラ内のワークフローを攻めるか、②業界特化で、これまで人手をかけるには規模が小さい、あるいは収益性が見込めなかった業界共通ワークフローを丸ごと請け負い、従来では実現できなかった効率性で攻めるか、の2つが今後のAI Agentsの方向性として考えられるかなと思います。
さらに直近では、ユーザーのリクエストに基づき、画面上でAIが自律的にタスクを遂行する”Computer use”をAnthropicが公表しました。これも基本的にはAI Agentsの一種だと思いますが、Applicationレイヤーではなく、Applicationを動かすさらにその上の”Screen Layer”を抑えようとする動きに見えます。現状は精度の問題で実験段階ですが、今後急速な精度向上が見込まれます。ただし、これもB2Bで本格的なユースケースを想定した場合、考慮させる環境範囲設定やツール選択など、事前定義項目はそれなりにあるはずで、Delivery工数はかなり大きくなると思われます。

7. 生成AIにおけるmiddlewareについて
7-1. Vector database
生成AIの活用が広がるにつれ、生成AIを活用するためのミドルウェアの需要も高まっています。特に3. “生成AIの(B2B SaaSと比較した場合の)基本理解やその特徴”で触れたように、生成AIは出来合いの汎用モデルをすぐに使うことができ、ChatGPTのように非常に優れた汎用Applicationも存在しますが、汎用的であるが故に、本格的なユースケースを想定した場合には、いかに社内の独自データを活用するかという“後付けカスタマイゼーション”が重要になるというのは上述の通りです。このように、社内ファイルなどLLMが学習していない外部データ活用の重要度が増している中、社内データをベクトル化し、迅速なベクトル検索を可能にするベクトルデータベースが注目されています。
特に、このベクトルデータを応用しているのがRAG(=社内ファイルなど外部データを参照したプロンプトをLLMに投げることで正しいバイアスをかけ、回答の精度を上げる仕組み)です。RAGの利点は、ハルシネーションの抑制やLLMの学習データに含まれていない情報も回答可能になる点です。また、LLMそのものを再構築せずに済むため経済的でもあります。ベクトル化により、多くの外部データを限られた容量内に格納でき、且つ迅速な検索が可能となりますので、ベクトル化およびそのベクトルデータを溜める専用データベースがRAGの必須要素となります。
ただし、ベクトル検索は万能ではなく、ベクトルデータの最近傍を探るような検索をするため、意味の類似性のランク付けには強い一方、特定用語の完全一致が優先されるべき検索には必ずしも強くありません。キーワードベースの全文検索結果のスコアを使ったベクトル検索のリランキングや、複数のインデックス戦略を組み合わせることで精度を向上させる必要があります。また、ベクトルデータベースベンダーのコア技術部分でありベクトル検索のバックボーンであるインデックス方法(データの格納および検索の方法論)も、基本的には精度とスピードのトレードオフがありますが、各ベクトルデータベースベンダーの特徴が出ます。このようなベクトルデータベースの論点や各社の特徴を以下の表にまとめております。


7-2. Deployment
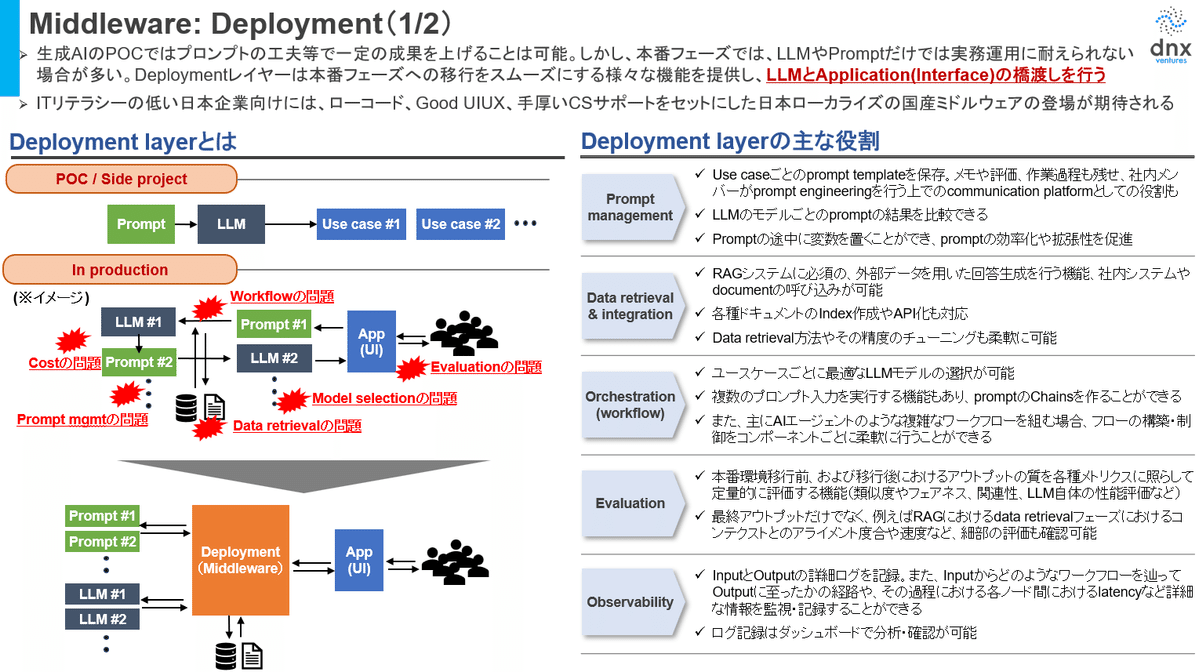
Deploymentレイヤーは生成AIプロジェクトのPoCから本番フェーズへの移行をスムーズにする様々な機能を提供し、LLMとApplication(インターフェース)の橋渡しを行う、生成AI活用のためのミドルウェアです。ChatGPTのように出来合いApplicationを使う場合には必要性は限定的ですが、生成AIを本格活用する上では様々な問題(ex. オーケストレーションの問題、LLM Model Selectionの問題、データRetrievalの問題、コスト管理の問題 etc.)が発生します。このような課題に対して、ソリューションを提供するのがDeployment用のミドルウェアです。グローバルではかなり多くのプレイヤーが出てきておりますが、往々にしてITリテラシーの低い日本企業はこのようなグローバルプレイヤーのミドルウェアを使いこなせないことが多いため、日本企業に合わせたローコード・ノーコードで、分かりやすいUIUX、手厚いCSサポートをセットにした日本にローカライズされた国産ミドルウェアの登場が期待されます。

8. 最後に
いかがでしたでしょうか?長文のnote記事にここまでお付き合いいただき、ありがとうございました。今回は主に生成AI×SaaSという観点から生成AIについて分析をしてみましたが、今後も色々なテーマ・確度から分析記事を出していきたいと思っています。なお、冒頭記載したように、生成AI領域の進化スピードは凄まじく、また、あらゆる関連分野で同時多発的に発生する全ての情報を正確に追うことは不可能なので、本内容が執筆時点の限定的な情報に基づく考え・分析であり、今後変わり得るものである点は予めご了承ください。
(文・新田修平)