
【競馬AI開発#7】機械学習モデルに入れる特徴量を完成させる

この【競馬AI開発】シリーズでは、競馬予想AIを作ることを通して、機械学習・データサイエンスの勉強になるコンテンツの発信や、筆者が行った実験の共有などを行っていきます。
■どんな機械学習モデルを目指しているか?
初手として作成するモデルでは、2023年に開催された全てのレースについてnetkeiba.comからデータを取得し、以下の「着順」列を機械学習で予測することを目指しています。
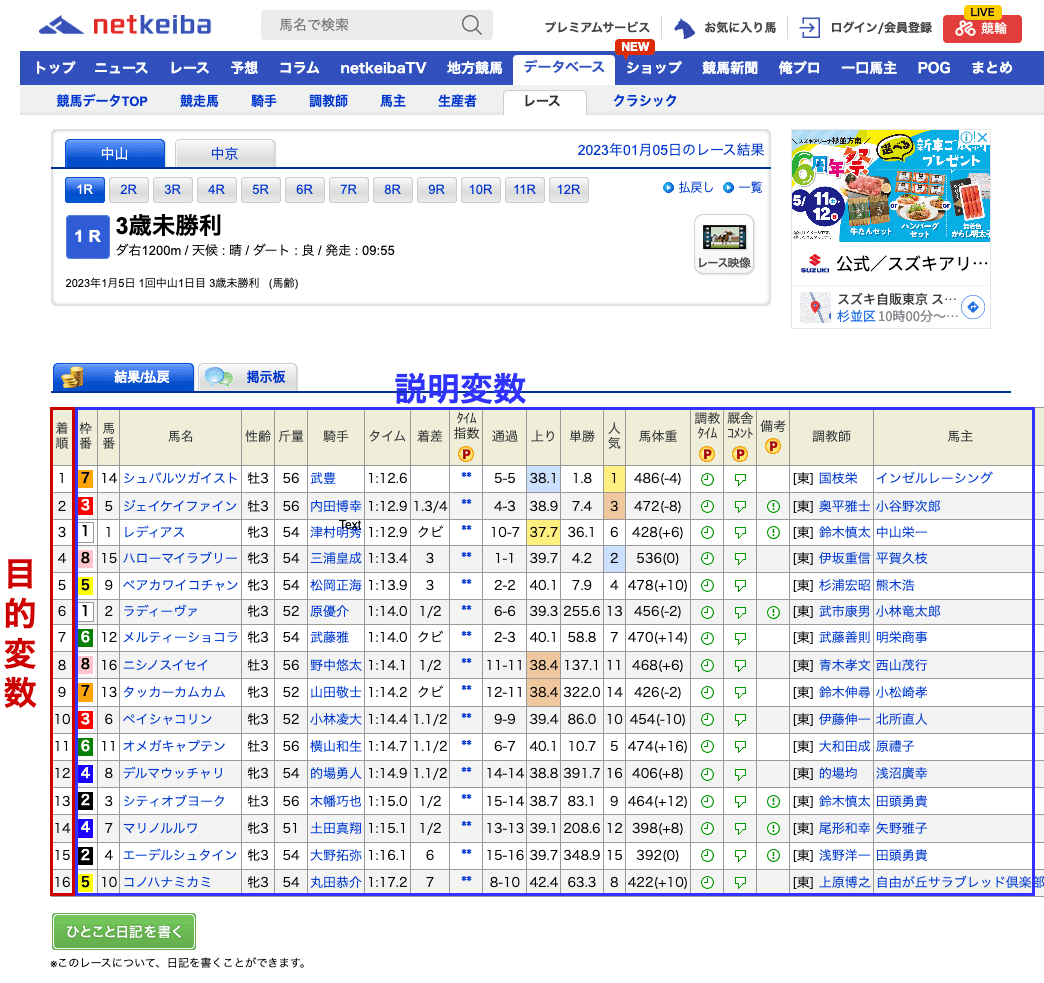
https://db.netkeiba.com/race/202306010101/
そこに予測材料として、馬の過去成績テーブルも取得して集計して加えます。

https://db.netkeiba.com/horse/2020103575/

このように、「データを加工して作られた予測材料となる列」のことを機械学習の用語で「特徴量」といい、特徴量を作成することを「特徴量エンジニアリング」と言います。
特徴量エンジニアリングの段階においては、上のように様々なデータを集計して追加し、場合によっては数千個の特徴量を作成し、複数パターンを試しながら精度を上げていくことになります。
この時、何も考えずにコードを書いていくと、notebook上でソースコードが量産され、管理しきれなくなってしまう状態に陥ります。
この記事では、「煩雑になりがちな特徴量作成のコードをどのように管理するか」というポイントも意識しながら、実際のソースコードを見ていきます。
このように本シリーズでは、一度きりの「機械学習で競馬予測してみた」で終わるものではなく、「継続的に開発・運用できる、かつ分かりやすい(初心者でも理解できる)」コードの作成を心がけています。
■今回作るもの
今回のコードを実行することで、最終的に機械学習モデルにインプットするデータが完成します。
from feature_engineering import FeatureCreator
fc = FeatureCreator()
features = fc.create_features()
具体的な特徴量は以下のようになります。
・race_id ・・・ レースID
・horse_id ・・・ 馬ID
・date ・・・ レース開催日
・jockey_id ・・・ 騎手ID
・trainer_id ・・・ 調教師ID
・owner_id ・・・ 馬主ID
・rank ・・・ 着順
・umaban ・・・ 馬番
・wakuban ・・・ 枠番
・tansho_odds ・・・ 単勝オッズ
・popularity ・・・ 人気
・impost ・・・ 斤量
・sex ・・・ 性別(カテゴリをラベルエンコーディング)
・age ・・・ 年齢
・weight ・・・ 体重
・weight_diff ・・・ 体重変化
・race_type ・・・ レース種別(カテゴリをラベルエンコーディング)
・around ・・・ 回る向き(カテゴリをラベルエンコーディング)
・course_len ・・・ 距離
・weather ・・・ 天候(カテゴリをラベルエンコーディング)
・ground_state ・・・ 馬場状態(カテゴリをラベルエンコーディング)
・race_class ・・・ レースクラス(カテゴリをラベルエンコーディング)
・place ・・・ 開催場所(カテゴリをラベルエンコーディング)
・rank_3races ・・・ その馬の過去3レースの平均着順
・prize_3races ・・・ その馬の過去3レースの平均賞金
・rank_5races ・・・ その馬の過去5レースの平均着順
・prize_5races ・・・ その馬の過去5レースの平均賞金
・rank_10races ・・・ その馬の過去10レースの平均着順
・prize_10races ・・・ その馬の過去10レースの平均賞金
・rank_1000races ・・・ その馬の過去1000レースの平均着順
・prize_1000races ・・・ その馬の過去1000レースの平均賞金これを最初のモデルとして、今後ここから特徴量を増やしていくことになります。
「ラベルエンコーディング」については、以下の記事で解説しています。
■筆者のプロフィール
東京大学大学院卒業後、データサイエンティストとしてWEBマーケティング調査会社でWEB上の消費者行動ログ分析などを経験。
現在は、大手IT系事業会社で、転職サイトのレコメンドシステムの開発を行っています。
定期購読をすると、今月更新される記事に加えて#1〜#4の記事が980円で全て読めるので大変お得です。
ソースコード

この記事が気に入ったらチップで応援してみませんか?