
【v1.1アプデ】SDXLモデルを半分に圧縮!?モデルをFP8に量子化してストレージを解放せよ!

24/08/25 15時頃追記(※スクリプトアプデしました)
これ、ローカル版の場合に変換前のキャッシュが残ってしまう問題がありました。今改修してるので、とりあえずもう実行しちゃった人は C:\Users\ユーザーID\.cache\huggingface\hub\以降のフォルダにリポジトリidフォルダがあったら削除してください。 https://t.co/VPb6A3Nab5
— 電々/でんでん (@den2_nova) August 25, 2024
こんな感じで、初期のローカル版のコード実行時に変換前のキャッシュが残るようになっています。C:\Users\ユーザーID\.cache\huggingface\hub\以降のフォルダにリポジトリidフォルダがあったら削除してください。
コードの改修が終わりましたので、お手数ですがローカル版ご使用の方は改めてダウンロードお願いいたします。
ちわっちゅ!世間ではFluxでもちきり!最近、FP8版の作り方が共有されました。その際に共有されたコードを使用すると、SDXLでも同様の効果が得られる事が分かったので使いやすく改良したスクリプトを作成してみました。
SDXLモデルを6GB→3GBに減量!?
通常のSDXLモデルはfloat16のパラメータを持っており、FP8量子化する事で16から8へ……つまりモデルのサイズを半分にまで圧縮出来ます。
ですが、いい事ばかりという訳でもなく……メリットデメリットがある行為なので、それらを把握して選択してください。
【メリットデメリットを5行で】
・SDXLモデルが約半分にまで削減可能、ストレージ容量が空きます。
・VRAM使用量を削減出来るかもしれない。
・モデルロード速度が速くなるかもしれない。
・生成結果が変わる場合があります。具体的には僅かに劣化します。
・LoRAが上手く掛からなくなる可能性がある。
【もっと詳しくメリット】
モデルサイズの削減:
SDXLモデルのファイルサイズを約半分に削減します(例:6.46GB → 3.23GB)。
ストレージ空間を節約し、モデル管理が容易になります。
メモリ使用量の最適化:
画像生成時のVRAM使用量を削減出来る可能性があります。(例:10.2GB -> 7.7GBになった事例をご報告頂きました)
処理速度の可能性:
一部の環境で画像生成速度が向上する可能性があります。
低スペックGPUでの利用:
VRAM容量の少ないGPUでもSDXLモデルを使用できる可能性が高まります。
【もっと詳しくデメリット】
画質への影響:
FP8変換により、生成される画像の品質に影響が出る可能性があります。(理論上は僅かに劣化するはずです)
ハードウェア互換性:
Forge並びにComyUIでのみ動作確認をしています。いずれにしてもFluxのFP8対応に伴うものだと思うので、最新のverに更新した場合のみ使用可能とお考えください。
古いGPUでは性能向上が見られない、または使用できない可能性があります。
モデルの挙動変化:
プロンプトに対する反応が元のモデルと異なる可能性があります。
特にLoRAはFP16モデルでトレーニングされているのが殆どです。そのためFP8の環境で使用した場合に損失が発生し効き目が悪くなったり、想定と異なる出力になる可能性があります。(強度を上げたりで対応可能かも?)
XYZ Plotを使用する場合、FP16のモデルと混ぜてcheckpoint軸で比較を取るとなぜかモデル変更が効かない。(FP16モデルとFP8モデルとの出力差を見たい場合はXYZ Plotは使用せずに個別にモデルをロードして生成してください)
モデルダイエットにはなにが必要?
変換時:PC または google colab(無料版)
生成時:Forge または ComfyUI の最新版
※A1111環境は未テストなので、試した方がいたら教えてください。
以上です。すご~い! 省メモリ化コードを使ってるので、3~8GBくらいのRAMで動くと思います。もしローカル版でメモリが足りなかった場合は、googleアカウントがあれば使用できるcolab版を使用してみてください。
FP8モデルの出力例
※でんでんさんは4GB VRAMの貧弱かつ古い環境でやってるので、一般的な人の環境とは出力結果が異なる可能性があります。(実際、他の環境の人に試して貰った時にはやや出力結果の傾向が変わりました)
※使用環境は記事執筆時点での最新版Forgeです。
←左が変換前 右がFP8変換後→


▼ FP8モデル変換ツールのコード
24/09/20 追記
shiba*2さんがcomfyUI上で動作するカスタムノード版を作成されていたので、お求めの方はそちらもどうぞ!
ローカル版
ローカル実行用のファイルは以下になります。ダウンロードし、お好きなフォルダに解凍して配置してください。
※24/8/25 15時くらいの追記 【ver1.1にアップデート】
hugging faceのキャッシュフォルダ(C:\Users\ユーザーID\.cache\huggingface\hub\)に変換前のモデルデータが残ってしまう問題に対応いたしました。
具体的には、処理が完了するとキャッシュフォルダ内のリポジトリidフォルダごと削除される仕様です。
解凍すると、以下のファイルが入っています。
model_converter.py(スクリプトファイル)
run_converter.bat(実行用batファイル)
update_huggingface.bat(フォルダ削除処理でエラーが出た時のhuggingfaceライブラリのアプデファイル)
本業プログラマではないため、これ系のお作法がよく分かっていません。python環境作ってなくても実行できるかは分かってないっす!ごめん!
ローカル版の使い方
(※直感で分かるなら飛ばしてOK)
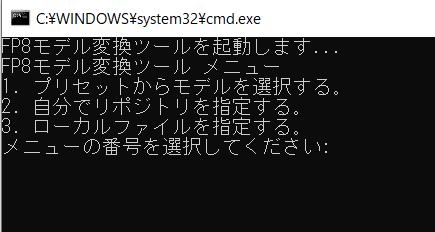
run_converter.bat をクリックしてcmd画面を起動します。
FP8モデル変換ツール メニューから、該当する数字を入力します。
プリセットからモデルを選択する。
自分でリポジトリを指定する。
ローカルファイルを指定する。
各種メニューに従って入力していきます。
変換が完了すると、FP8 Models フォルダに変換後のモデルが保存されます。(フォルダがない場合、自動で作成されます)
キー入力を求められるので、テキトーに何か入れて画面を閉じます。
【補足】
自分でのリポジトリ指定の入力方法について、よく分からない場合はcolab版の下にある「hugging face上のモデルを指定する場合にどこ見たらいいのかについて。」にジャンプしてみてください。
ローカルファイル指定は絶対パスでも相対パスでも多分いけます。私は絶対パス使ったけど。お好きな方を使ってください。
実行時、フォルダ削除時点でエラーが出る場合、huggingface_hub ライブラリが古い可能性があります。その時は以下を試してください。
update_huggingface.bat を実行してライブラリをアプデする
C:\Users\ユーザーID\.cache\huggingface\hub\以降のフォルダにリポジトリidフォルダが出来てるので、削除する。(例:animagineの場合C:\Users\ユーザーID\.cache\huggingface\hub\models--cagliostrolab--animagine-xl-3.1というフォルダ構成)
次に run_converter.bat から処理を実行した時は、ちゃんと自動でキャッシュフォルダが削除されるようになります!
google colab版
google colabの新しいノートブックを作成し、コードの挿入を使用して以下のコードをコピペしてください。
#@title ▼ FP8モデル変換ツール
model_choice = "pony-diffusion-v6" #@param ["pony-diffusion-v6", "animagine-xl-3.1", "holodayo-xl-2.1", "kivotos-xl-2.0", "clandestine-xl-1.0", "ebara_pony_1", "ebara_pony_2", "ebara_pony_2.1", "AutismMix_pony", "AutismMix_Confetti"]
custom_repo_id = "" #@param {type:"string"}
custom_model_version = "" #@param {type:"string"}
use_google_drive = False #@param {type:"boolean"}
google_drive_path = "/content/drive/MyDrive/FP8 Models/umbraMecha_v10.safetensors" #@param {type:"string"}
import os
import json
import time
from pathlib import Path
from typing import Dict, Any
from google.colab import drive
from huggingface_hub import hf_hub_download
from safetensors import safe_open
from safetensors.torch import save_file
import torch
from tqdm.auto import tqdm
from google.colab import runtime
SAVE_DIR = "/content/drive/MyDrive/FP8 Models"
SLEEP_TIME = 5
print("Google Driveをマウントしています...")
if not os.path.exists('/content/drive'):
drive.mount('/content/drive')
print("必要なライブラリをインストールしています...")
!pip install -q huggingface_hub torch safetensors tqdm
print("モデル変換の準備をしています...")
model_options = {
"pony-diffusion-v6": ("AstraliteHeart/pony-diffusion-v6", "v6.safetensors"),
"animagine-xl-3.1": ("cagliostrolab/animagine-xl-3.1", "animagine-xl-3.1.safetensors"),
"holodayo-xl-2.1": ("yodayo-ai/holodayo-xl-2.1", "holodayo-xl-2.1.safetensors"),
"kivotos-xl-2.0": ("yodayo-ai/kivotos-xl-2.0", "kivotos-xl-2.0.safetensors"),
"clandestine-xl-1.0": ("yodayo-ai/clandestine-xl-1.0", "clandestine-xl-1.0.safetensors"),
"ebara_pony_1": ("tsukihara/xl_model", "ebara_pony_1.bakedVAE.safetensors"),
"ebara_pony_2": ("tsukihara/xl_model", "ebara_pony_2.safetensors"),
"ebara_pony_2.1": ("tsukihara/xl_model", "ebara_pony_2.1.safetensors"),
"AutismMix_pony": ("WhiteAiZ/autismmixSDXL_autismmixConfetti", "autismmixSDXL_autismmixPony.safetensors"),
"AutismMix_Confetti": ("WhiteAiZ/autismmixSDXL_autismmixConfetti", "autismmixSDXL_autismmixConfetti.safetensors")
}
def read_safetensors_metadata(path: str) -> Dict[str, Any]:
try:
with safe_open(path, framework="pt", device="cpu") as f:
metadata = f.metadata()
return metadata if metadata is not None else {}
except Exception as e:
print(f"メタデータの読み取り中にエラーが発生しました: {str(e)}")
return {}
try:
print("モデルの選択と読み込みを開始します...")
if use_google_drive and google_drive_path:
path = google_drive_path
print(f"Google Driveからモデルを読み込みます: {path}")
repo_id = "Google Drive"
model_version = os.path.basename(path)
else:
if custom_repo_id and custom_model_version:
repo_id = custom_repo_id
model_version = custom_model_version
else:
repo_id, model_version = model_options[model_choice]
filename = f"{model_version}"
print(f"{repo_id}からファイルをダウンロードしています...")
path: str = hf_hub_download(repo_id=repo_id, filename=filename)
print(f"{repo_id}からファイルのダウンロードに成功しました")
print(f"ファイルパス: {path}")
model_file = Path(path)
print("モデルのメタデータを読み込んでいます...")
metadata = read_safetensors_metadata(path)
if metadata:
print("モデルのメタデータ:")
print(json.dumps(metadata, indent=4, ensure_ascii=False))
else:
print("メタデータが見つかりませんでした。")
print("モデルの変換を開始します...")
sd_pruned = {}
with safe_open(path, framework="pt", device="cpu") as f:
for key in tqdm(f.keys(), desc="テンソルを変換中"):
tensor = f.get_tensor(key)
sd_pruned[key] = tensor.to(torch.float8_e4m3fn)
print("変換したモデルを保存しています...")
model_name = os.path.splitext(os.path.basename(model_version))[0]
output_filename = f"{model_name}-fp8.safetensors"
os.makedirs(SAVE_DIR, exist_ok=True)
output_path = os.path.join(SAVE_DIR, output_filename)
save_file(sd_pruned, output_path, metadata={"format": "pt", **(metadata or {})})
print(f"ファイルが正常に保存されました: {output_path}")
# ... (以下のコードは変更なし)
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
import traceback
traceback.print_exc()
if 'output_path' in locals():
print(f"保存しようとしたパス: {output_path}")
if 'SAVE_DIR' in globals():
print(f"ディレクトリの存在: {os.path.exists(SAVE_DIR)}")
print(f"書き込み権限: {os.access(SAVE_DIR, os.W_OK)}")
finally:
print(f"{SLEEP_TIME}秒後にランタイム接続を解除します...")
time.sleep(SLEEP_TIME)
runtime.unassign()Colab版の使い方
(※直感で分かるなら飛ばしてOK)


視覚的にも分かりやすいようにメッセージとか色々出るようにしました。
▶ hugging face上にあるモデルの場合
model_choice のドロップダウンメニュー内にモデルがあれば選択。2.3の手順はスキップし4へ進む。自分で指定したい場合は2の手順に進む。
custom_repo_id でモデルリポジトリIDを入力する。(例:Animagine XL 3.1の場合は cagliostrolab/animagine-xl-3.1)
custom_model_version で変換するモデル名を入力する。(例:Animagine XL 3.1の場合は animagine-xl-3.1.safetensors)
▶ボタンを押して実行すると処理が始まります。
ドライブマウントのポップアップが出るので、必ず承認してください。
変換が成功すれば /content/drive/MyDrive/FP8 Models/ フォルダに変換後のモデルが『元のファイル名-fp8.safetensors』という名称で保存されます。(フォルダがディレクトリ上にない場合、自動的に作成されます)
処理が終わると5秒後、自動的にランタイム接続が解除されます。
▶ googleドライブ上にあるモデルの場合
googleドライブ上に変換したいSDXLモデルを配置する。(※/content/drive/MyDrive/FP8 Models/上に配置を推奨)
use_google_drive チェックボックスをONにする。
google_drive_path に変換するモデルのパスを入力する。(/content/drive/MyDrive/FP8 Models/変換したいモデル名.safetensors)
▶ボタンを押して実行すると処理が始まります。
ドライブマウントのポップアップが出るので、必ず承認してください。
変換が成功すれば /content/drive/MyDrive/FP8 Models/ フォルダに変換後のモデルが『元のファイル名-fp8.safetensors』という名称で保存されます。(フォルダがディレクトリ上にない場合、自動的に作成されます)
処理が終わると5秒後、自動的にランタイム接続が解除されます。
【注意】
各モードの優先度は 【 use_google_drive > custom_repo_id / custom_model_version > model_choice 】 になっています。そのため、model_choice を使用する場合は use_google_drive へのチェックOFFと custom_repo_id と custom_model_version の欄は必ず空にしておいて下さい。入っていると、そちらの変換が優先されます。
Diffusers形式には使用できません。(safetensors形式にのみ使用可能)
Civitaiからの直接ダウンロードは安定しないので見送りました。
自動でのランタイム接続解除処理を入れている都合上、以下のような表示が出る場合がありますが正常動作していても表示されてしまうので焦らないようにしましょう。(※もちろん、エラーになってても出ますが)

hugging face上のモデルを指定する場合にどこ見たらいいのかについて。
こちらの、へむろっくさんのモデルを参考にプルダウンリストにない時の設定方法を説明していきます。リンクを開くと、以下のような画面が表示されると思います。
目当てのモデルの表紙から、Files an Versionsのタブに移動して変換したいモデル名のリンクをクリックします。

この画面内の、Hemlok/REV-Mix の部分が custom_repo_id に入力すべき部分です。mainの隣に表示されているモデル名を含む文字列の Models/REV-XL-V2.safetensors が custom_model_version に入力すべき部分にあたります。
この時、REV-Mix の部分は含まれない点を注意してください。
基本的にはディレクトリのトップに.safetensorsファイルが配置されていることが殆どですが、このようにフォルダ内に階層分けされてる場合でも変換は問題なく動作します。
文字列の隣にある □ の部分をクリックすると自動で文字列がコピーされるので、それを該当箇所に貼り付けるだけでOKです。

Colab版の場合はこのように入力した状態で▶ボタンを押して実行すれば、動作します。前段から繰り返しますが、 Colab版の場合はuse_google_drive へのチェックOFFにするのを忘れないでください。
逆に、model_choiceを使用する場合はこの部分に入力があると優先変換されるので、空欄にしてから実行してください。
役に立つかもしれない情報
コードを改良する場合
もしかしたら最近流行のGGUF化とかもできるかもしれんが私にはよく分からなかったので触ってません。理論的にはggufにしたほうが同じモデルサイズでも品質が良くなるらしいです。ただし生成速度は遅くなるとのこと。(情報源→https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/1050)
古いForgeで動かす方法(未確認)
やってないんで分かりませんが、こちらの記事が参考になるかもしれません。「webui」フォルダの「webui-user.bat」のCOMMANDLINE_ARGSの行に、 COMMANDLINE_ARGS=--unet-in-fp8-e4m3fn を追加って感じ。
あとこちらの設定もなんかやった方がいいのかも?未確認です。
低VRAM(8GB)のStable Diffusion Web UI(AUTOMATIC1111)ver1.9.4でSDXLを使用する際の設定例です
— みずたま (@mizutamaaiart) June 9, 2024
①webui-user.batに「set COMMANDLINE_ARGS=--xformers --medvram-sdxl」を追記
②「FP8 weight」「Cache FP16 weight for LoRA」を有効化
③「VAE type」(encodeとdecode)を「TAESD」に変更 pic.twitter.com/kjyFFZZ6bL
今回お世話になった方(順不同)
▶ はるはる さん(X:@haruharu1105_ai)
作成されたコードを元に改造して使用しています。また記事執筆にあたりご助言をいただきました。本当にありがとうございます!
▶ あるふさん(X:@alfredplpl)
FP8版の作り方に関する Community Discussion の情報をお教え頂きました。ありがとうございます!
▶ Jukka Seppänenさん(X:@kijaidesign)
はるはるさん作成のコードの大本を Community Discussion 上にて共有して下さった方です。ありがとうございました!
▶ Stellaさん(X:@stella221125)
Kijaiさん(Jukka Seppänenさんの別名義)、Kohya Techさん(X:@kohya_tech)のコードを元に省メモリ化したスクリプトを公開頂きました。コードに組み入れてさせて貰ってます。ありがとございました!
▶ 某鯖のみんな
相談やモデルの生成テストにご協力いただきました。鯖管さんを始めとした住民の皆さんありがとう!
記事執筆にあたってそれなりに時間かけたので、イイネして頂けると励みになります! よろしくお願いいたします✨
↓↓↓それとこの機会に他の記事も読んでいってくれると嬉しいです。
この記事が気に入ったらサポートをしてみませんか?