
ローカルチャットボットAI「Chat with RTX」の導入方法と、その印象とか

たまにはここで、自作ゲーム「Crystalled Bullets」以外のことも書いてみる。
というわけで、2月13日にリリースされた、「Chat with RTX」についての解説です。英語の記事として私がいつも見ているサイトのTechPowerUpの詳細なレビュー記事がありますが、日本語のものはまだ無いので、それについて書いてみることにしました。
推奨スペックについて
RAM: 16GB以上
GPU: バージョン535.11以上のドライバーをインストールしたNvidia GPU
16GB以上のVRAMを備えたRTX 30/40 GPU (言語モデル:Llama2の場合)
(RTX 3090, RTX 4080, RTX 4090などのハイエンドモデル)
8GB以上のVRAMを備えたRTX 30/40 GPU (言語モデル: Mistralの場合)
(RTX 20シリーズ、モバイル版RTX 2060/3060/3050は残念ながら対象外)
ストレージ:SSDほぼ必須。Mistralをインストールする場合90GB。Llama2の場合120GB。
ここでは主にMistralについて書いていきます。実際、RTX 3090以上のGPUを持っている人はほぼ居ないでしょうし・・・(筆者はRTX 3080 12GBモデルを使用しています。)
導入方法について
こちらのNvidiaのダウンロードリンクから"Download Now"と表示されているボタンをクリック。

すると30GBあるこちらのインストーラーのzipファイルのダウンロードが始まるので、気長に待ちましょう。

先ほどダウンロードしたzipファイルを解凍できたら、"setup.exe"をクリックしてインストーラーを起動してください。

Nvidiaのソフトウェアを使っていれば、見慣れたであろうこちらの画面が出てきました。(Windows Vista時代も同じUI使ってたような・・・)
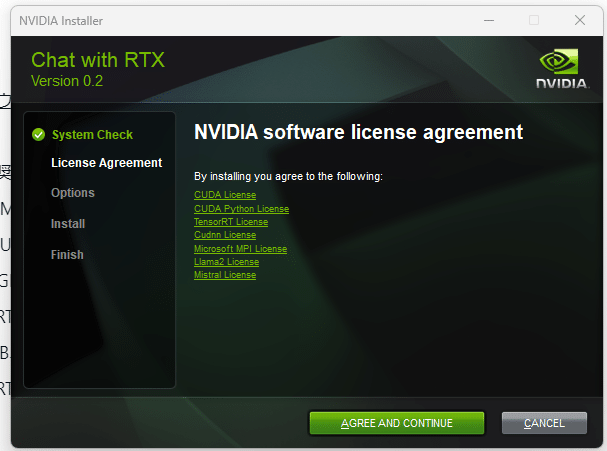
"Agree and Continue"を押せば、16GB以上のVRAMを積んだGPUであれば、Llama2をインストールするか、Mistralをインストールするか聞かれます。
今回は12GBのGPUを使ってるのでMistral以外の選択肢は出ないはずです。
ちなみに"Perform a clean installation"にチェックを入れるとNvidiaコントロールパネルの設定などが初期化されます。何かトラブルが無い限り外しておきましょう。

ここから他のインストールするために必要なソフトウェアのダウンロードが始まりますのでまた気長に待ちましょう。
途中でMistralに関するコンパイルが始まって、CPUをバリバリ使い始めるので、そのパソコンで動画を見ながら待っていると急に動作がガックガックになるので、その待ち方は避けましょう。

初回起動時はPythonなどに関わるセットアップがコマンドプロンプトを通して始まります。

セットアップが終われば、こちらの画面がWebブラウザ上のUIで出てくるはずです。

使い方
標準設定でインストールする場合、次から起動する際は、「C:\Users\<ユーザー名>\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main」内の"app_launch.bat"をクリックして起動が可能です。
学習データを追加するには「C:\Users\<ユーザー名>\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\dataset」に.txtファイルを放り込んでWebUIの「Dataset」の再読み込みボタンをクリックすれば学習してくれます。
字幕のあるYouTube動画であれば「Dataset」のYouTube URLから"Enter URL"で動画の内容を瞬時にまとめてくれる・・・はずなんですが、私の環境では動作しませんでした。TechPowerUpの記事では動いてたので、Llama2限定の機能みたい?
標準でついてくる学習データはあまりないので、学習させるのはほぼ必須でしょう。
使った印象について
「ポテンシャルはあるが、使う用途としては難しい」
という事に尽きる。
応答速度に関しては、RTX 3080 12GBモデルの場合速度は問題なしといった感じ。VRAMもそこまで使わなかった。OpenAIにデータを送らず動かすことができる、インターネット接続がなくても使えるという点はセキュリティの観点から強みがあるが、元々の学習データの少なさや、要求するスペックの高さ、日本語非対応などの使いづらさがネック。
個人的にはOpenAIに頼らなくていいのでCrystalled Bulletsに関する英語記事を作ってもらうのにはいい感じかな・・・と、思っている。
おわり。
この記事が気に入ったらサポートをしてみませんか?