
データ戦略の会社が考える「ビジネスでのデータ活用に必要な”データ戦略”の4要素」

2020/04/30追記:
データ戦略に必要な4要素 --> データ戦略の7要素にUpdateしました!
以下のリンク先記事が最新版ですのでご覧ください。
----
はじめに:データ戦略とは
弊社は「データ戦略」の会社であり、社名にDataStrategyと名付けています。私も、自分の肩書に、それなりに意味を持って「データストラテジスト」と付けています。
実は英語圏でも、「データ戦略(Data Strategy)」という言葉は、一部のプレーヤーがそれぞれの定義で使うことはあれど、確立された定義が存在する訳ではありません。しかし、世の中には様々な機能戦略として、「マーケティング戦略」「営業戦略」「知財戦略」があります。それと同様にデータというものが経営上重要になってきたとき、また私自身が起業前に流しのデータサイエンティストとして活動をする中で、データについても戦略的なアプローチが求められるのではという直感があり、法人を設立する際にはその直感をそのまま社名にしました。
以下、私の考える「データ戦略」を定義してみます。
まず、ここでいう戦略については「目的を達成するための、資源(リソース)利用の指針」という定義を採用します*。マーケティング戦略で言えば、例えば凄くざっくり言うと「ある人数の新規顧客の獲得顧客」を目的としたとき「顧客ターゲット選定・ブランドとして一貫して発信するメッセージの選定・クリエイティブ/メディア選定」などを戦略として定義されることが多いでしょう。
*厳密に言うと、どの必要なリソースを獲得するかといったことも含まれます。
データ戦略の4要素
データ戦略における「目的=ビジネス上の成果」は、マーケティング戦略等の特定の機能戦略と比べても、極めて多伎に渡ります(例:売上が増える、コストが下がる、マーケティングのROIが改善する、UXが向上して転換率が改善する、等)。それらの目的を、限られた時間含む資源の中で達成していくためには、適切な戦略策定を行い実行することが必要だと考えるようになりました。
さて、データ活用のための「データ戦略」と言ったときには、以下の4つの要素を定義していくことで、戦略がはっきりします。どんなに複雑なデータ活用事例でも、この4つ視点からデータ戦略を捉えていくことで、他者の事例を分析するときになにが「肝」だったのか、あるいは自社のデータ戦略を考える際に「何を決めていけばよいのか」がはっきりして来ます。
Input: どんなデータを入れるか
Algorhythm: どんな処理を行うか
Output: どんな結果を得るか
User Interface: データの入力や出力結果の取得をどのように行うか
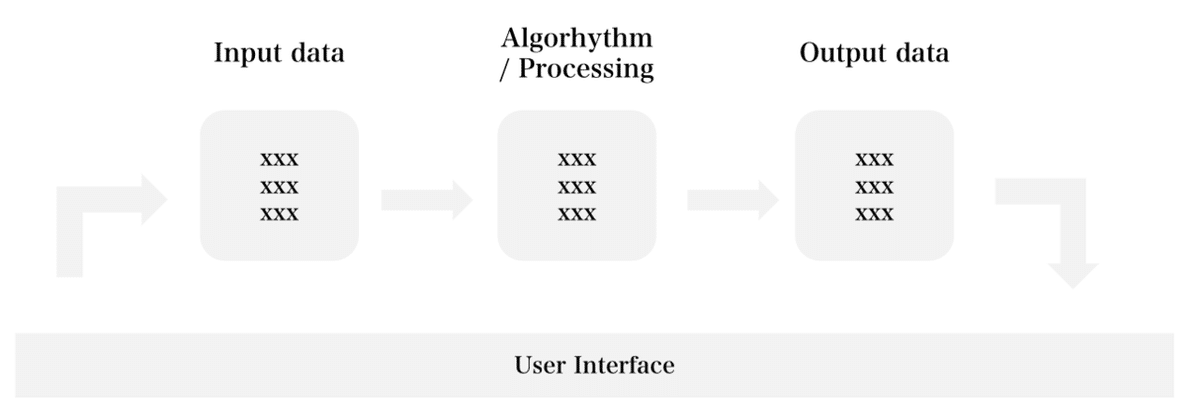
*ちなみに、この4要素は私が経験上導き出したものです。類似する概念の提唱は少しずつ色々なところで行われるようになってきましたが、私はこの4要素が現時点では最も使いやすいと思います
これは、機械学習や深層学習を使うようなデータ分析でも、あるいは単純なクロス集計で済むようなデータ分析でも、IoTのように沢山のデバイスからデータを収集する場合でも、基本的に同じ考え方でアプローチできます。「データ活用」となると、データをどのようなアルゴリズム(例: AI技術など)で分析しようか?という視点に思考がいきがちですが、私は最も重要かつ最初に考えるべきなのはOutputだと考えています。
Outputでは、どんな結果を得られれば自社のビジネスの成果に直結するか?を考えます。成果につながらない分析結果は出力しても意味がないので、どのような結果を出力するかを最初に考えます。その上で、Outputを出力するための必要なデータ(Input)と、その処理方法(Algorhythm)を検討する、という流れを踏んでいきます。
具体的には、それぞれ以下のような内容と流れで定義します。
<Outputの構成要素>
・出力する具体的なデータ項目
・望ましい頻度・速度
・ビジネスへの活用方法
↓ (Outputに必要なデータを定義する)
<Inputの構成要素>
・入力する具体的なデータ項目
・各項目の収集方法
・必要な前処理・データ加工
↓ (Input -> Output の変換に必要な要素を定義する)
<Algorhythmの構成要素>
・アルゴリズムの概要(機械学習モデル等)
・アルゴリズムの構築方法(自前or外部調達等)
・必要な計算リソース・計算環境
↓ (Outputを見る画面と、InputとOutput に必要なシステムを定義する)
<User Interfaceの構成要素>
・ユーザーが使用するインターフェースの概要
・既存システムとの連携方法(アーキテクチャ)
データ戦略の検討例(ケーススタディ)
ここからは、簡単な例を踏まえながら考えたいと思います。
例えば、あるタクシー会社が「自社のドライバーの走行ログを活用して、普段とは異なる運転をしたドライバーを検知することで、事故を未然に防ぐための予防策を行いたい」というケースを考えます。すなわち、この際の目的は「自社のタクシーにおける事故を減らすこと」です。
では、この目的を達成するためのリソース利用の指針として、上のデータ戦略の4要素を順に考えていきましょう。
まず、Outputとして以下のような項目を考えます。
<Output>
出力する具体的なデータ項目: 全従業員別の、昨日までの運転と比較をした場合の異常値スコア
望ましい頻度・速度: 日報とセットで毎日確認しているので、日次で出力できれば良い
ビジネスへの活用方法: 現状で指導員が日次で日報をチェックしているので、その時にスコアが出力されていれば声かけや面談の優先度が決まる。見逃しは大事故に繋がる可能性があり、全員分の日報を細かくチェックできないので、指導員の業務負荷の軽減にもなる
次に、Inputとして「何があれば普段とは異なる運転を検知できそうか」を考えます。この場合は、例えば以下のように考えられます。
<Input>
・入力する具体的なデータ項目: 走行ログ(実際は、例えば速度を見るとしても単純に平均速度を見れば良いのか、速度の変化を見れば良いのか、などの細かいテクニックを踏まえて入力項目を決める必要があります)
・各項目の収集方法: 既存の運行管理システムからAPI連携(要開発)
・必要な前処理・データ加工: 生ログからxxxという処理を加えて特徴量を追加する。運転者により運行時間は異なるので、xxx時間分をx分ごとにずらしながら利用する。
<Algorhythm>
・アルゴリズムの概要: 異常検知の手法(従前のデータと比較をして、大きな変化があったかどうかを検出する。工場の異常や、WEBアクセスの異常を検知する際によく用いられるアプローチ)のうち、Autoencoderの手法を検討する。異常が無いと確認されたxxx時間分のデータでモデルを構築し、再現率から異常を検出する手法を検討する。
・アルゴリズムの構築方法: 自前で構築。過去xx年分のデータから検討
・必要な計算リソース・計算環境 : 全てクラウドを想定し、分析環境 xxx, 運用時環境 xxxとする。GPU必須。
というように決めることができます。
実際はInputデータを詳細に検討する必要はありますが、大まかには以上のような流れになります。
最後にInterfaceです。実際に試験的に運用する際には、データを入力・出力する何らかのシステムが必要です。あるいは、初期段階はPoC(コンセプト検証のための試験導入)として、人が介在して運用することもあります。
タクシー会社の例を考えると、実際の走行ログデータは既存システムのデータベースに自動で格納されるので、それを毎日深夜に取得して解析結果をする、という一連の流れをエンジニアに構築してもらい、まずはその方法で運用をすることにしました。
<User Interface>
・ユーザーが使用するインターフェースの概要: メールによるcsvファイル添付での通知
・既存システムとの連携方法(アーキテクチャ): Inputデータについては既存システムとAPI連携。計算用サーバでスコアを計算し、メールで担当者に送付(ただしメールはGoogle Apps Script経由で実施する)
データ戦略策定の面白さと難しさ
・・・と、ここまで簡潔に書いて来ましたが、実際に決めようとなると考えるべきポイントは沢山あります。実際に考える上で最も難しいのは、データ分析の技術的な観点からの判断です。例えば、以下のようなケースがあります。
・ビジネス上望ましいOutputは決められても、それが技術的に実現可能な内容ではなかったので、その後の分析プロセスの難易度が極めて高くなり途中で頓挫してしまった。
・Outputを決めたあとに、Inputデータとして適切な情報を漏れなくカバーできていなかったので、実際に試験導入まで行ったが実運用に耐える精度にならなかった。
・Algorhythmの検討を分析会社に依頼したが、「精度が出ないので無理です」との報告をされた。社内でも分析会社での検討プロセスや報告内容の適切さを判断できないまま、プロジェクトが終了してしまった。
・分析結果は良好だったので、費用をかけUser Interfaceを開発・導入した。実際にそれなりに役に立つOutputの内容を提供できていたが、導入したシステムの使い勝手が悪く、想定しているユーザーが全然使ってくれなかった。
こうしたデータ分析の技術的な観点からの判断が難しい理由の一つには、「データ分析」と一口にいっても適用手法は幅広いことがあります。例えばデータ分析と言っても以下のような切り口があります。
・対象とするデータ
・ビッグデータ
・自然言語
・画像
・センサーデータ
・ネットワーク(人間関係・ソーシャルグラフ)など
・適用する処理手法
・モデル構築・シミュレーション
・機械学習・強化学習・深層学習・オートメーション
・上記の内容を踏まえたシステム開発
いまチャレンジしようとしている内容が、技術的にみて妥当かどうか等の視点は、なるべく個々のケースに即したナレッジや技術を持っている人がジャッジをした方が、当然良い結果に繋がりやすくなります。ただ、実際は適切な人にアクセスできていない場合も実際には多くあります(世の中全体としてデータ分析が可能なエンジニアがまだ少ない上に、技術を持った人は技術やデータを持った会社に集中しがち、ということも背景の一つにあります)。
いずれにせよ、最初のプランニングが適切でないと、コスト(費用や期間)の管理や期待値コントロールといった観点からその後のプロジェクトマネジメントが難しくなっていきます。最初のプラニングの結果によって、その後の成功確率は大きく変わるというのが実態ではないかと思います。
---
DataStrategyへ相談したい方へ
DataStrategyでは、執筆、イベント登壇、取材、サービスの改善、アドバイザリーなどの相談を受け付けています。弊社へまずは相談だけでもしてみたい、一度話を聞いてみたいという方は twitter (@motohikotakeda) でDMして下さい。
・AI可能性診断 https://datastrategy.jp/aikanousei/
・弊社ウェブサイト https://datastrategy.jp
・資料請求 https://datastrategy.jp/document/