
LLMの民衆化を加速した広義のモデル開発(RAG、Prompting、Agent)とは?

CubecではLLMを段階的に理解できるように「医療に特化した大規模言語モデルを紹介する」全7回をシリーズでお届けしています。
第3回は「LLMの民衆化が加速した理由である、広義のモデル開発とは?」という疑問を博士に聞いてみます。
民衆化したLLM:その理由を探ろう

博士、最近「LLMの民衆化」という言葉を耳にしますよね。
今さらな質問かもしれないですが、LLMはなぜこんな急に広まったのでしょうか?

急速に広まった理由はLLMの使いやすさもありますが、これまでのAIとは大きく異なる特徴があるからです。それは、利用者一人一人が開発に参加できることです。自分の目的に合わせて工夫ができる参加型のAIだからこそ、多くの人に受け入れられています。今や、みなさんの生活やお仕事のさまざまな場面に、LLMは深く入り込んできていますよね。
では、LLMが広がっていった背景を詳しく解説していきましょう。新しい技術の活用方法や、これからの可能性も見ていきます。
広義のモデル開発:みんなで作るAIの新時代

利用者が開発に参加できるって、どういう意味ですか?AIの開発というと、まだまだ専門家にしかできない気もしますが・・・。

たしかに、生成AI時代前のディープラーニングが全盛の頃は、開発は一部の専門家だけのものでした。統計家やデータサイエンティストのような、一部のスペシャリストがモデリングをしていたのです。数学的な知識や技術的な経験が欠かせなかったからですね。
ところが生成AIの時代に入り、状況は大きく変わりました。LLMの登場により、誰もが開発に関われるようになったのです。
身近な例を挙げてみましょう。みなさんがChatGPTやGeminiを使うとき、どんな風にプロンプトを書いていますか?
実はこれもモデリングの一部と言っていいのです。
工夫次第で、思いもよらない使い方が見つかりますよね。LLMの可能性を引き出す拡張(Augmentation)の一つと言えるでしょう。うまくプロンプトを与えることで、LLMの使い方が広がるのです。
これは、第2回で説明した因数分解の式でいうと、最後の「α」となっている部分にあたります。

以前は狭義のモデリングであったのに対し、生成AI時代は広義のモデリングが可能になったと言えます。
3 種のLLM拡張:みんなの工夫でAIの可能性を広げよう

LLMの可能性を引き出す拡張(Augmentation)って、具体的にどんなことをするのですか?

広義のモデル開発であるLLMの拡張について、注目を集めている具体的な方法を紹介していきますね。それは、RAG、Prompting、Agentの3つです。
一つずつ、詳しく見ていきましょう。
📌 RAG:Retrieval-Augmented Generation
RAG はLLMに新しい知識を教える画期的な方法です。RAGの直訳は「検索拡張生成」です。参照してほしいデータを用意して、LLMに新しい情報を渡す方法です。そうすることで、LLMが持っていない知識や情報にも答えられるようになります。
例えば今週に起こった出来事など、学習を終えた後の新しい出来事にも対応できます。LLM自体に情報はありませんが、RAGで情報を与えることにより、LLMは答えられるようになるのです。これを用いると、例えば、自社内専用のLLM拡張ができます。RAGにより社内にたまったナレッジや履歴情報などをまとめることで、LLMで活用可能です。

RAGの世界は日々進化を続けています。最も基本的な形はNaive RAGです。より複雑な仕組みはAdvanced RAGと呼ばれています。知識グラフを使ったGraph RAGのような発展的な手法もあります。
Cubecではこのような発展的な開発をリサーチしつづけ、開発ナレッジをためています。
📌 Prompting
プロンプトは、LLMが持っている設定や能力を最大限に引き出すことを促進(Prompt)するような言葉選びの技術です。すでに使っている方も多いと思います。
例えば「あなたは優秀なエンジニアです。○○アプリを作る場合の、手順を教えて」などのように、役割や意図をLLMに伝えるものが一般的でしょう。
プロンプトの手法にはいくつか種類があります。
Zero-shot:例を見せずに聞く方法
Few-shot:いくつかの例を見せてから聞く方法
Chain of Thought:考えの道筋を示す方法
Tree of Thought:より複雑な思考の木を使う方法
参考 Tree of Thoughtのフレームワーク

状況に応じて、これらを使い分けていくのです。
📌 Agent
単に質問に答えるだけでなく、特定のタスクや行動ができるようになります。
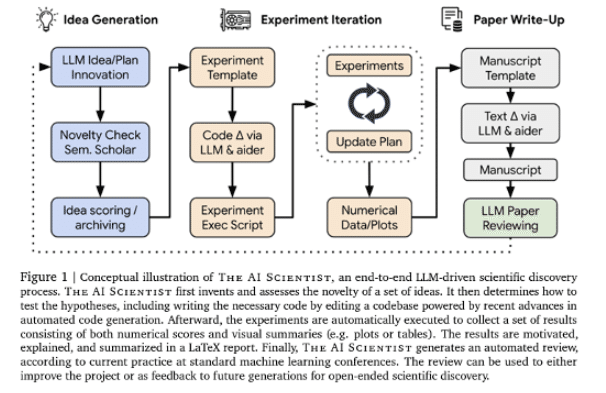
例えば、Chris Lu氏らによる完全自動化の論文(The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery)が有名です。LLM Agentが動き、リサーチや研究といういくつもの異なるタスクの組み合わせたワークフローを動かせます。
新たなLLMの取り組み:仕事も暮らしも変えていこう

博士、LLMが民衆化すると、これからどんな可能性が広がるんですか?

注目すべきことは、実はここまでお話ししてきた内容には、LLM自体の開発が一つもないということなんです。
つまり、使い方を工夫するだけでLLMの可能性が広がっていくのです。
企業で生成AIを活用する際には、基盤モデルであるGPTなど既存のRAGを利用し、プロンプトを工夫することが多いでしょう。これにより、業務効率化や新しいサービスが可能になりました。
さらに、ビジネスだけでなく、自治体業務などでも導入が進んでいます。例えば、横須賀市では職員の負担を軽くするために、RAGの実証実験をしていました。
みなさんの工夫次第で、LLMの新しい使い方が見つけられるはずです!

LLMの世界を探索しよう!今後のスケジュール
次回は「第4回:一部のプラットフォーマによる事前学習と基盤モデル(Pre-training、Foundation model)」をお届けします。
今後の予定
第1回:Cubecが医療特化の大規模言語モデル開発に着手する意味
第2回:大規模言語モデルを因数分解して解像度を上げる
第3回:広義のモデル開発がLLMの民衆化を加速した(RAG、Prompting、Agent)
第4回:一部のプラットフォーマによる事前学習と基盤モデル(Pre-training、Foundation model)
第5回:裾野が広まりつつあるファインチューニング(FT)
第6回:大規模言語モデルにおける強化学習(RLHF)
第7回:Cubecが取り組む大規模言語モデルの現状
さらに専門的な情報を知りたい人に、Cubecでは論文紹介もしています。
Cubecは一緒にチャレンジしてくれる仲間を募集しています。
興味があればぜひ、カジュアル面談も申し込んでください。
Cubecでは多様なバックグラウンドのメンバーが活躍しています。実際にどんな仕事をしているのか、メンバー紹介もご覧ください。
Cubecメンバー紹介 一覧
vol.1 【データサイエンスチーム中村】
臨床医を目指す医大生が、医療AIのCubecでデータサイエンティストとして働く理由
vol.2 【データサイエンスチーム新井田】
データサイエンティストのマインドチェンジ〜ディープラーニング時代から生成AI時代へ〜
vol.3【プロダクトマネージャー酒井】
臨床工学技士から医療AIのプロダクトマネージャーへ〜医療の現状をテクノロジーで改善したい〜
vol.4【データサイエンスチーム塚川】
大学院生が"あえて"就職前に医療LLMスタートアップで"働く"理由