
【論文紹介】専門用語に強いRAGにするGolden-Retriever

みなさん、はじめまして。
私は現在、神戸大学大学院システム情報学研究科で研究をしながら、医療AIのスタートアップ、Cubecでデータサイエンティストをしています。
4月には大手企業に就職が決まっている私が、なぜCubecで働くのか、もし興味があれば下記noteを読んでみてください。
Cubecでは、かかりつけ医が意思決定するための関連情報を、認められたエビデンスから提供するLLM(大規模言語モデル)の開発に取り組んでいます。医療のような専門領域における知識をLLMに加える代表的な戦略の1つにRAG(RAG:Retrieval-Augmented Generation)があります。
RAGとは、質問に関連する文章を参照させることで、より正しい回答をLLMが生成するようにする仕組みです。ですが、専門領域において、固有の専門用語や略語は多数含まれています。それに加え、同じ略語であっても、文脈によって違う意味になることがあります。
わかりやすい例だとACは、Air Conditioner(エアコン)やAlternating Current(交流)になることです。このような専門用語や略語が、関連する文章の参照を困難にし、LLMが誤解した出力を生成する可能性があります。
そこで、RAGに専門用語や略語に対しても、精度の高い回答ができる手法として注目されているGolden-Retrieverの論文を読み、今後の言語モデル開発に活かせるところを探したいと思いました。
少し長いのですが、できるだけわかりやすく説明をしてみたいと思います。
概要
Golden-Retrieverは、質問に含まれる専門用語の意味を明確にしてからドキュメントの検索を行うことで、精度の高い回答生成を実現する。
提案されている機能概要
・LLMを用いてチャンクの説明を追加する
・LLMを用いて質問から専門用語・略語を抽出しリスト化
・LLMを用いてリストから質問のコンテキストを特定
・コンテキストから略語を特定し、質問に詳細な説明を追加する
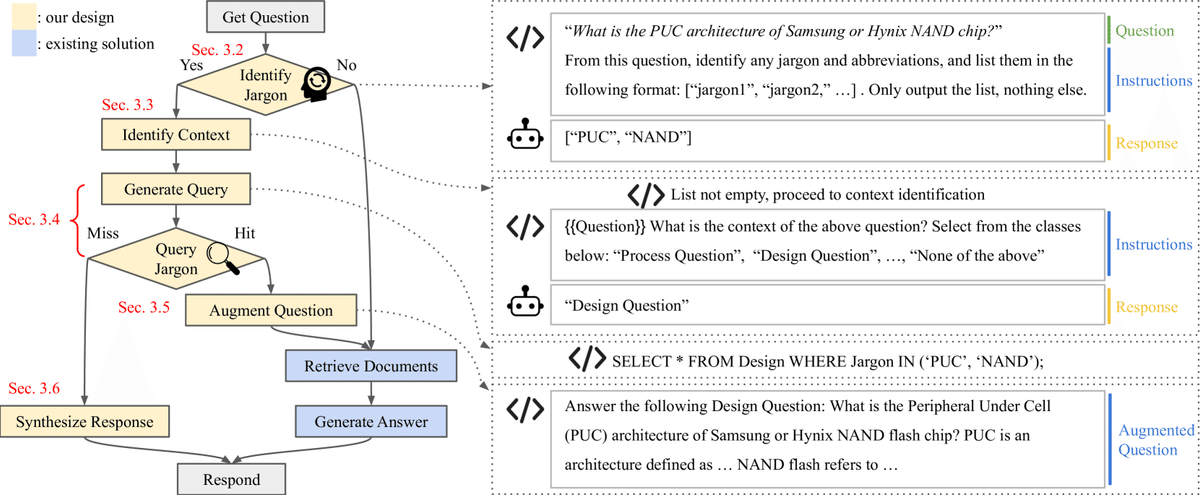
本文
1.はじめに
専門分野の文章には、技術コミュニティに固有の略語や専門用語が多数含まれている。大規模言語モデル(LLM)は、一般的な質問応答に対しては優れたパフォーマンスを有しているが、上記のような知識に対するLLMのパラメータ微調整には計算コストが掛かる、古い知識を上書きしてしまうなどの問題点がある。
RAGはLLMを再トレーニングする必要なく動的に更新できるメリットがある。しかし、専門用語や略語は独自の文章にしか含まれないため、誤解する可能性がある。
💡これまでの対策方法
Corrective RAG Yan ら (2024)および Self-RAG Asai et al. (2023) は、検索後の LLM の応答を強化
▶️曖昧な専門用語が含まれている場合、関連度の高いドキュメントを検索できず、有効性が制限される。Kochedykov ら (2023) は、抽象構文木(AST)に分解し、クエリの忠実度を向上
▶️対象が自然言語ドキュメントではなくSQLに限定
▶️実際のユーザーの質問文にはコンテキスト情報は含まれていないKochedykovら (2023) は、テキスト分類機を利用し、事前定義された一連のコンテキストに分類
▶️トレーニングデータセットが必要である

2.関連研究
Corrective RAG & Self-RAG
▍概要:ドキュメント検索ステップの後に応答を修正する手法を提案
▍欠点:専門用語の誤解やコンテキストの欠如により最初の検索に欠陥があった場合、後処理では不正確さを完全に修正することができない
Kochedykovらによる関連するアプローチ(2023)
▍概要:曖昧な質問をASTに分解。それに応じてSQLクエリを合成する手法を提案
▍ 欠点:SQLクエリに限定されており、一般的な質問応答には適用されていない
3.提案手法
Golden-Retrieverは、オフラインとオンラインに分けて構成されている。
オフラインの部分:チャットボット展開前のデータ前処理
オンラインの部分:ユーザが質問するたびに実行される対話型プロセス
3.1 LLM駆動型ドキュメント拡張
▍目的:ドキュメントの関連性を向上させること
▍欠点:明確な説明が欠けているドキュメントは、検索した際に関連性スコアが低くなる可能性がある
▍概要: 各ドメインのエキスパートの観点からLLMが要約を生成し、生成された要約をデータベースに追加する。これにより、クエリ時に関連するドキュメントが取得される可能性を上げる。
具体的な手順
1)OCRを使用してドキュメントからテキスト抽出し、扱いやすいチャンクサイズに分割(Llama-3だと約4000トークン)
2)各チャンクに対して、LLMが各ドメインのエキスパートの観点から要約を生成
3)生成されたデータ(拡張データ)をドキュメントデータベースに追加する

3.2 専門用語の識別
▍目的:曖昧な可能性のある用語を認識し、後の処理で解決しやすくする
▍欠点:従来の文字列完全一致法では辞書に登録できていない専門用語を検出できない可能性があり、次の処理で誤った解釈につながる可能性がある
▍概要:LLMを使ってユーザの質問に含まれる専門用語と略語を特定し、入力された専門用語と略語をリストアップする
具体的な手順
1)入力された質問に対して、専門用語と略語を抽出してリストにするよう指示するプロンプトテンプレートを使用

2)専門用語と略語が含まれている(Yes)・含まれていない(No)で処理が分岐(Fig. 2参照)
a.(Yes)「3.3 コンテキストの特定」に進む
b.(No)「RAGの関連度の計算」に進む
3.3 コンテキストの特定
▍目的:略語の意味を正確に特定するために質問文のコンテキストを特定する
▍欠点:従来のテキスト分類機には大量のデータセットが必要になり、データセット作成に膨大な労力が必要となる
▍概要:計算コストは上がるが、LLMを使ってユーザの質問のコンテキストを特定する
具体的な手順
1)(事前)コンテキストを特定するためのプロンプトを準備する プロンプトにはコンテキスト名とその説明のリストを含む
2)1で準備したプロンプトを利用してLLMにどのコンテキストか特定させる ※パフォーマンス向上のため、CoTを利用して特定のデータ構造で応答させることもできる

3)「3.4 専門用語のクエリ」に進む
3.4 専門用語のクエリ
▍目的:専門用語の正確な解釈をLLMに提供すること
▍欠点:LLMベースによるSQLのクエリの生成は、クエリの品質と安全性に関する不確実性が生じることや、推論コストが増加することが懸念される
▍概要:特定された専門用語のリストを使用してコードベースのSQLクエリを作成し、専門用語・略語の詳細な定義を検索する
具体的な手順
1)(事前)専門用語・略語についてのSQLデータベースの準備 データ:略語・正式名称・詳細な説明・関連メモ
2)(事前)SQLクエリ作成のコード作成
3)特定された専門用語のリストからSQLクエリの作成&検索
4)検索結果により分岐
a.(Hit)「3.5 質問の拡張」へ進む
b.(Miss)「3.6 クエリミス応答」へ進む
3.5 質問の拡張
▍目的:質問に明確なコンテキストを追加することで曖昧さを減らすこと
▍概要:コンテキスト情報と詳細な専門用語の定義をユーザーの元の質問に追加することで質問を拡張する
具体的な手順
1)(事前)ユーザの質問と3.3, 3.4の結果を結合するテンプレート&コードの作成
2)上記のコードを利用してユーザーの質問にコンテキスト情報や詳細な専門用語の定義を追加することで元の質問を拡張する。
3)拡張された質問を用いてドキュメントの検索(RAG)を行う

3.6 クエリミス応答
データベースにコンテキストが存在せず誤った生成を行わないために行う
専門用語に関連する情報が見つけれなかった場合に、専門用語のスペルの確認or新しい専門用語を追加するようにする
4.評価実験
4.1 文章に基づいてドメイン固有の質問に答える能力の評価
4.2 質問から略語を正しく識別するLLMの能力の評価
4.1 質問応答実験
実験条件:
・6領域における、新人エンジニア向けトレーニング文章から質問を作成
・1つの領域にあたり9〜10問
・質問文は1〜2文の正誤問題・選択肢問題(最大4選択肢)
・各クイズは5回繰り返し、専門家によって採点され平均スコアが計算される
▼質問文の例
・3つの手法:Vanilla LLM(何もなし)、RAG(従来手法)、Golden Retriever(提案手法)
・3つのモデル:Meta-Llama-3-70B-Instruct AI@Meta(2024)、Mixtral-8x22B-Instruct-v0.1、 Shisa-v1-Llama3-70b.2e5
実験結果:
提案手法はVanilla LLMより平均57.3%、RAGより平均35.0%スコアを向上させた。
提案手法が複数LLMモデルにおいても回答の精度を大幅に向上させることを示している。
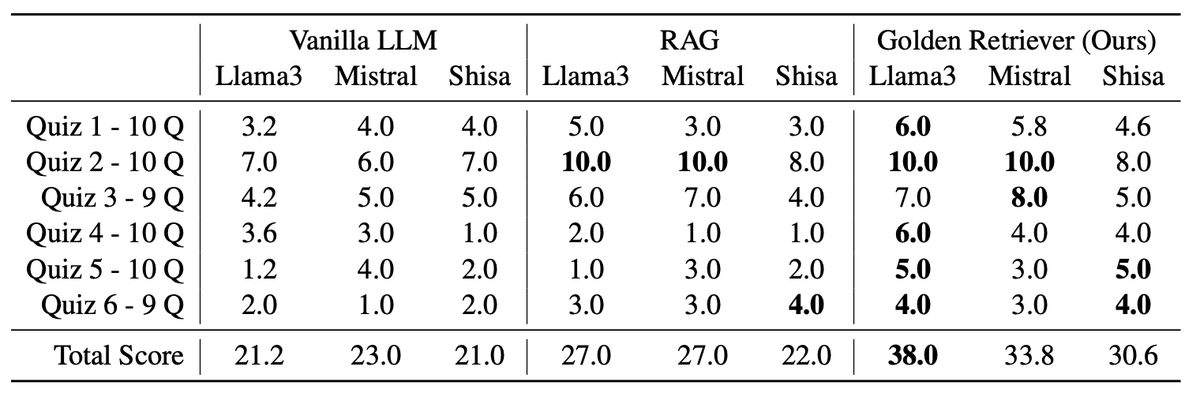
4.2 略語識別実験
実験条件:
・ランダムな略語を生成し、質問テンプレートに挿入して合成のデータセットを作成
・略語の生成には辞書から各文字の確率分布を計算して形成 詳細は付録C.1のランダムな略語生成コードに示す
・質問に含まれる略語は1〜5個
・3つのモデル:Meta-Llama-3-70B-Instruct AI@Meta(2024)、Mixtral-8x22B-Instruct-v0.1、 Shisa-v1-Llama3-70b.2e5
実験結果:
対象の3モデルが、未知の略語を識別する際に高い能力を持っていることが示された。
モデルごとに失敗が異なり、失敗ケースは付録C.2に示す。

5.結論
従来のRAGと比較してGolden-Retrieverは専門用語に対する応答性能が高いことがわかった。
これからの開発に向けて
いかがだったでしょうか。
Golden-Retrieverでは、データの準備段階(オフライン部分)や、専門用語・略語を特定し質問を拡張する流れ(オンライン部分)で、様々な工夫がされていました。
個人的には、オンライン部分の処理をLLMにさせるところ・コードにさせるところのように、お互いの対応能力や堅牢性の高さから柔軟に使い分けているところは、LLMのモデル開発に限らず、他の領域でも使えるアイデアだと思いました。
Cubecでは現在、循環器領域に特化した診療支援AIを開発中です。国家試験形式の問題だけでなく、本論文で示唆された新しい形式の問題を通して、既存の医療LLMを超える性能を持つAIを開発することを目指します。
Cubecはデータサイエンティストをはじめ、一緒にチャレンジしてくれる仲間を募集しています。興味がある方は、こちらからカジュアル面談をお申込みください。
参考文献
Cubec論文リサーチ
【論文紹介】医療AIの新たな評価軸MultifacetEval(前編)
【論文紹介】医療AIの新たな評価軸MultifacetEval(後編)
この記事が気に入ったらサポートをしてみませんか?