
機械学習:R言語(Tidymodels)チュートリアルの和訳⑤

病院の再入院を公平に予測する:機械学習の公平性ケーススタディ
YARDSTICK
FAIRNESS
TUNING
CLASSIFICATION
糖尿病患者の入院時の情報(人口統計、診断結果、支払い、薬など)をもとに、病院は患者が30日以内に再入院するかどうかをかなり正確に予測する機械学習モデルを訓練することができます。しかし、そのようなモデルを使用することによって患者にどのような害が生じる可能性があるのでしょうか?
2019年に、Obermeyerらは、医療提供者が資源を配分するために使用する機械学習モデルの予測に関する分析を発表しました。このモデルの出力は、高リスクケア管理プログラムへの患者の推奨に使用されます:
これらのプログラムは、訓練された提供者からのより多くの注意を含む追加リソースを提供することで、複雑な健康ニーズを持つ患者のケアを改善することを目的としています。ほとんどの健康システムは、人口健康管理の取り組みの柱としてこれらのプログラムを使用しており、効果的に成果と満足度を向上させながらコストを削減するものと広く認識されています。[…] これらのプログラム自体が高額であるため(専任の看護師チーム、追加のプライマリケア予約枠、その他の希少なリソースにコストがかかるため)、健康システムはアルゴリズムを広範に使用して最も利益を受ける患者を特定しています。
彼らの分析では、問題のモデルは大きな人種バイアスを示しており、「アルゴリズムによって同じリスクレベルに割り当てられた黒人患者は白人患者よりも病気である」と主張しています。実際には、これにより「追加ケアに指定された黒人患者の数が半分以上減少する」結果となりました。
この記事では、高リスク患者を特定する機械学習モデルを訓練するための公平性指向のワークフローを示します。モデル開発プロセス全体を通じて、そのようなモデルが文脈で展開されたときに異なるモデリング決定が社会に与える影響を考慮します。
この分析で使用するデータは、糖尿病患者の71,515件の入院に関する情報を含む公開データベースです。このデータは、Strack et al. (2014) の研究に基づいており、著者は特定の検査が再入院を予測する効果をモデル化しています。そのデータのバージョンは、readmission Rパッケージで利用可能です。
以下はそのデータを読み込み、セットアップするためのコード例です:
library(readmission)
readmission
#> # A tibble: 71,515 × 12
#> readmitted race sex age admission_source blood_glucose insurer duration
#> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <dbl>
#> 1 Yes Afric… Male [60-… Referral <NA> <NA> 7
#> 2 No Cauca… Fema… [50-… Emergency Normal Private 4
#> 3 Yes Cauca… Fema… [70-… Referral <NA> Medica… 5
#> 4 No Cauca… Fema… [80-… Referral <NA> Private 5
#> 5 No Cauca… Fema… [70-… Referral <NA> <NA> 4
#> 6 No Cauca… Male [50-… Emergency Very High <NA> 2
#> 7 Yes Afric… Fema… [70-… Referral <NA> Private 3
#> 8 No Cauca… Fema… [20-… Emergency <NA> <NA> 1
#> 9 No Cauca… Male [60-… Other <NA> <NA> 12
#> 10 No Cauca… Fema… [80-… Referral <NA> Medica… 1
#> # ℹ 71,505 more rows
#> # ℹ 4 more variables: n_previous_visits <dbl>, n_diagnoses <dbl>,
#> # n_procedures <dbl>, n_medications <dbl>このデータの最初の変数 readmitted は、患者が退院後30日以内に再入院したかどうかを示しています。この変数を「追加ケアが必要だったかどうか」を示す代理変数として使用します。つまり、1ヶ月以内の再入院は、入院中に追加の注意があった方が良かった可能性を示します。もし機械学習モデルがあるサブグループに対して非再入院を予測することで一貫して少ない必要性を示すなら、そのサブグループは本来受けるべきケアを受けないことになります。
私たちは、人種グループを公平に扱いながら、可能な限り高性能なモデルを訓練したいと考えています。tidymodels フレームワークは、このような不公平を識別するために必要なツールを提供します。
library(tidymodels)
library(baguette)
library(desirability2)
library(GGally)探索的分析
まずは、いくつかの説明的な要約とプロットから分析を始めましょう。まずは、結果変数(readmitted)を見てみます。
readmission %>%
count(readmitted)
#> # A tibble: 2 × 2
#> readmitted n
#> <fct> <int>
#> 1 Yes 6293
#> 2 No 6522230日以内に再入院した患者は全体の8.8%でした。これは、結果変数の一つの値が他の値よりもはるかに一般的であるクラス不均衡のモデリング問題の例です。次に、各保護されたクラス(例えば、人種や性別など)におけるカウントを見てみましょう。
readmission %>%
count(race)
#> # A tibble: 6 × 2
#> race n
#> <fct> <int>
#> 1 African American 12887
#> 2 Asian 497
#> 3 Caucasian 53491
#> 4 Hispanic 1517
#> 5 Other 1177
#> 6 Unknown 1946患者の大多数は「Caucasian」(74.8%)または「African American」(18%)とラベル付けされています。残りの人種カテゴリーのカウントはかなり小さく、データをリサンプリングに分割すると、これらのカウントはさらに減少します。その結果、「Asian」、「Hispanic」、「Other」、「Unknown」に関連する推定値の変動は、「African American」と「Caucasian」のそれよりも大きくなります。
readmission %>%
# randomly split into groups
mutate(., group = sample(1:10, nrow(.), replace = TRUE)) %>%
group_by(race, group) %>%
# compute proportion readmitted by race + random `group`ing
summarize(prop = mean(readmitted == "Yes"), n = n()) %>%
# compute variation in the proportion by race.
# note that, by default, the output from above is grouped by race only.
summarize(mean = mean(prop), sd = sd(prop), n = sum(n))
#> # A tibble: 6 × 4
#> race mean sd n
#> <fct> <dbl> <dbl> <int>
#> 1 African American 0.0849 0.00713 12887
#> 2 Asian 0.0825 0.0295 497
#> 3 Caucasian 0.0900 0.00369 53491
#> 4 Hispanic 0.0805 0.0285 1517
#> 5 Other 0.0680 0.0265 1177
#> 6 Unknown 0.0720 0.0178 1946観測数 nnn が少ないグループでは、平均割合が似ていても標準偏差 sdsdsd がはるかに大きくなります。この変動は、グループ間の変動を測定する公平性メトリックに影響を及ぼします。観測数が少ない人種グループで計算された割合に関連するノイズが、これらのグループにおける実際のケアの不公平に関連するシグナルを圧倒する可能性があります。
以下はこの問題に対処する際のいくつかの選択肢です:
まれなクラスからの行を削除する: この例では、「白人」と「アフリカ系アメリカ人」以外の人種値を持つ行をすべて削除することを意味します。これは、元の研究や他の公開されたデータ分析で取られているアプローチです。このアプローチによる分析では、「白人」と「アフリカ系アメリカ人」以外の人種グループに関するケアの格差を無視します。
カスタムの公平性メトリクスを構築する: 小規模なカウントに関連する増加した変動性に対処するためのカスタムの公平性メトリクスを構築します。各人種グループの推定値の変動性をスケーリングしてから公平性メトリクスを計算します。
まれなクラスの値をビンにまとめる: これにより、「白人」と「アフリカ系アメリカ人」以外の人種の値を1つの因子レベルにまとめます。このアプローチは上記の2つのアプローチのハイブリッドと言えます。その結果、特定の人種グループに関する情報の詳細さは失われますが、「白人」と「アフリカ系アメリカ人」以外のグループに関連する推定の変動性を減少させることができます。
readmission_collapsed <-
readmission %>%
mutate(
race = case_when(
!(race %in% c("Caucasian", "African American")) ~ "Other",
.default = race
),
race = factor(race)
)
readmission_collapsed %>%
count(race)
#> # A tibble: 3 × 2
#> race n
#> <fct> <int>
#> 1 African American 12887
#> 2 Caucasian 53491
#> 3 Other 5137readmission_collapsed %>%
ggplot(aes(x = age)) +
geom_bar() +
facet_grid(rows = vars(admission_source))
このデータでは、ほとんどの患者が60代から70代であり、多くの入院は緊急事態によるものですが、紹介やその他の原因による入院もあります。
readmission_collapsed %>%
ggplot(aes(x = insurer)) +
geom_bar()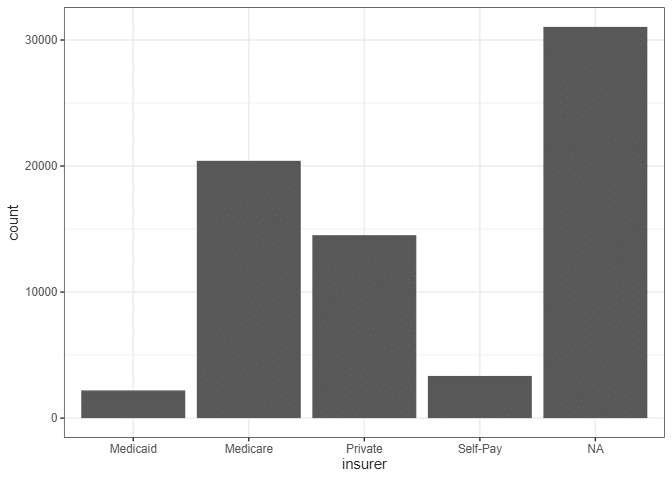
このデータでは、ほとんどの患者の支払い情報が欠落していますが、ほとんどの患者がメディケアの下でカバーされています。
支払い方法は、保護されたグループ自体の変数以外で、社会的な不公平がソースデータに反映される可能性がある方法の1つです。メディケイドのカバレッジは所得が一定以下の人にのみ利用可能であり、多くの自己支払い患者は医療保険を持っていないことがあります。これは彼らがそれを負担できないためです。関連して、米国の人種グループ間で貧困率は大きく異なります。
readmission_collapsed %>%
pivot_longer(starts_with("n_")) %>%
ggplot(aes(x = value)) +
geom_histogram() +
facet_wrap(vars(name), scales = "free_x")
多くの患者にとって、これが初めての入院となる病院システムでの訪問です。彼らの滞在中、多くの患者が10から20種類の薬を服用し、いくつかの手順を経験します。
これらのデータセット内の変数の分布を把握したら、モデリングのためにデータを分割する準備ができますね。
RESAMPLING DATA
set.seed(1)
readmission_splits <- initial_split(readmission_collapsed, strata = readmitted)
readmission_train <- training(readmission_splits)
readmission_test <- testing(readmission_splits)17,879行からなる readmission_test テストセットは、分析の最後まで置いておきます。選択したモデルの最終的な評価を計算するまで、このテストセットは使用しません。トレーニングデータの53,636行を10つのリサンプルに分割します。
readmission_folds <- vfold_cv(readmission_train, strata = readmitted)
readmission_folds
#> # 10-fold cross-validation using stratification
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [48272/5364]> Fold01
#> 2 <split [48272/5364]> Fold02
#> 3 <split [48272/5364]> Fold03
#> 4 <split [48272/5364]> Fold04
#> 5 <split [48272/5364]> Fold05
#> 6 <split [48272/5364]> Fold06
#> 7 <split [48273/5363]> Fold07
#> 8 <split [48273/5363]> Fold08
#> 9 <split [48273/5363]> Fold09
#> 10 <split [48273/5363]> Fold10各分割には、モデルの適合に使用する分析セットと評価のための評価セットが含まれています。リサンプル全体で性能推定値を平均化することで、モデルがまだ見ていないデータに対してどれくらいうまく機能するかを把握することができます。
TRAINING AND EVALUATING MODELS
モデルと前処理戦略の多様なセットを定義し、それらをリサンプルに対して評価します。
モデルのワークフロー まず、欠損値に対して因子レベルを設定し、その後数値データを中心化およびスケーリングする基本的な手順を定義します。
recipe_basic <-
recipe(readmitted ~ ., data = readmission) %>%
step_unknown(all_nominal_predictors()) %>%
step_YeoJohnson(all_numeric_predictors()) %>%
step_normalize(all_numeric_predictors()) %>%
step_dummy(all_nominal_predictors())# e.g. "[10-20]" -> 15
age_bin_to_midpoint <- function(age_bin) {
# ensure factors are treated as their label
age <- as.character(age_bin)
# take the second character, e.g. "[10-20]" -> "1"
age <- substr(age, 2, 2)
# convert to numeric, e.g. "1" -> 1
age <- as.numeric(age)
# scale to bin's midpoint, e.g. 1 -> 10 + 5 -> 15
age * 10 + 5
}
recipe_age <-
recipe(readmitted ~ ., data = readmission) %>%
step_mutate(age_num = age_bin_to_midpoint(age)) %>%
step_rm(age) %>%
step_unknown(all_nominal_predictors()) %>%
step_YeoJohnson(all_numeric_predictors()) %>%
step_normalize(all_numeric_predictors()) %>%
step_dummy(all_nominal_predictors())これらの前処理手法は、それぞれロジスティック回帰、XGBoost、およびバッグドニューラルネットワークのいずれかと組み合わせます。これらはそれぞれ、基礎となるデータ生成プロセスについて異なる仮定を持っています。それぞれのモデルの仕様を定義します。
spec_lr <-
logistic_reg("classification")
spec_bt <-
boost_tree("classification", mtry = tune(), learn_rate = tune(), trees = 500)
spec_nn <-
bag_mlp("classification", hidden_units = tune(), penalty = tune())wflow_set <-
workflow_set(
preproc = list(basic = recipe_basic, age = recipe_age),
models = list(lr = spec_lr, bt = spec_bt, nn = spec_nn)
)
wflow_set
#> # A workflow set/tibble: 6 × 4
#> wflow_id info option result
#> <chr> <list> <list> <list>
#> 1 basic_lr <tibble [1 × 4]> <opts[0]> <list [0]>
#> 2 basic_bt <tibble [1 × 4]> <opts[0]> <list [0]>
#> 3 basic_nn <tibble [1 × 4]> <opts[0]> <list [0]>
#> 4 age_lr <tibble [1 × 4]> <opts[0]> <list [0]>
#> 5 age_bt <tibble [1 × 4]> <opts[0]> <list [0]>
#> 6 age_nn <tibble [1 × 4]> <opts[0]> <list [0]>ワークフローセット内の各ワークフローが評価できる準備が整いましたね。次に、これらのモデルワークフローを最良の方法で評価する方法を決定する必要があります。
Metrics
モデルを評価する際に使用するメトリクスは、公平性分析の核心です。デフォルトの分類メトリクスである accuracy() と roc_auc() に加えて、以下の公平性メトリクスを計算します:
equal_opportunity(): モデルの予測が保護されたグループ間で真陽性率と偽陰性率が同じであるときに満たされます。この例では、モデルが再入院を正しく予測し、人種グループ間で同じ割合で非再入院を誤って予測する場合に equal opportunity が満たされます。このメトリクスは患者の利益を代表し、同じ必要性がある場合、追加のケアリソースを同じように受ける可能性があることを望みます。また、不必要なケアを受ける可能性が同じくらいであることも望みますが、このメトリクスは偽陽性を考慮しないため、不必要なケアリソースを必要としない可能性のある患者に対して異なるケアリソースを提供することに対して制裁を課しません。
equalized_odds(): モデルの予測が保護されたグループ間で偽陽性率、真陽性率、偽陰性率、真陰性率が同じであるときに満たされます。この定義は equal opportunity の特別な場合であり、偽陽性率と真陰性率に制約が追加されます。この例では、モデルが再入院と非再入院の両方を正しく予測し、人種グループ間で再入院と非再入院を同じ割合で誤って予測する場合に equalized odds が満たされます。equal opportunity と同様に、このメトリクスの利害関係者はモデルの予測を受ける対象者であり、不必要なケアリソースを提供することや、必要のない追加のケアリソースを必要とする患者を正しく識別することを防ぐことを目的とします。
demographic_parity(): モデルの予測がグループ間で同じ予測陽性率を持つときに満たされます。この例では、モデルが人種グループ間で同じ割合で再入院を予測する場合に demographic parity が満たされます。このメトリクスは真の結果値、再入院に依存しないことに注意してください。このメトリクスの利害関係者は、実際には異なるグループ間でのみ、それらのリソースの提供を見ることができると考えています。
m_set <-
metric_set(
accuracy,
roc_auc,
equal_opportunity(race),
equalized_odds(race),
demographic_parity(race)
)
m_set
#> A metric set, consisting of:
#> - `accuracy()`, a class metric | direction: maximize
#> - `roc_auc()`, a probability metric | direction: maximize
#> - `equal_opportunity(race)()`, a class metric | direction: minimize,
#> group-wise on: race
#> - `equalized_odds(race)()`, a class metric | direction: minimize,
#> group-wise on: race
#> - `demographic_parity(race)()`, a class metric | direction: minimize,
#> group-wise on: raceEvaluation
これで、定義したワークフローをメトリクスセットを使ってリサンプルに対して評価することができます。ワークフローを評価するために workflow_map() 関数は各ワークフローに対して tune_grid() を呼び出します。
set.seed(1)
wflow_set_fit <-
workflow_map(
wflow_set,
verbose = TRUE,
seed = 1,
metrics = m_set,
resamples = readmission_folds
)フィットされたワークフローセットは、以前見た未フィットのワークフローセットと同様に見えますが、各モデルワークフローの調整プロセスに関する情報がオプションと結果の変数に保存されています。
wflow_set_fit
#> # A workflow set/tibble: 6 × 4
#> wflow_id info option result
#> <chr> <list> <list> <list>
#> 1 basic_lr <tibble [1 × 4]> <opts[2]> <rsmp[+]>
#> 2 basic_bt <tibble [1 × 4]> <opts[2]> <tune[+]>
#> 3 basic_nn <tibble [1 × 4]> <opts[2]> <tune[+]>
#> 4 age_lr <tibble [1 × 4]> <opts[2]> <rsmp[+]>
#> 5 age_bt <tibble [1 × 4]> <opts[2]> <tune[+]>
#> 6 age_nn <tibble [1 × 4]> <opts[2]> <tune[+]>MODEL SELECTION
さまざまなメトリクスでいくつかのモデルを評価したので、最適なモデルを決定するために結果を探索できます。まず、メトリクスの分布を探索するための簡単な図を作成します。
wflow_set_fit %>%
collect_metrics() %>%
pivot_wider(
id_cols = c(wflow_id, .config),
names_from = .metric,
values_from = mean
) %>%
select(-c(wflow_id, .config)) %>%
ggpairs() +
theme(axis.text.x = element_text(angle = 45, vjust = .8, hjust = .9))
公平性メトリクスである demographic_parity()、equal_opportunity()、equalized_odds() は、多くのモデルでほぼゼロに近い値を取ります。また、これらのメトリクスの値は互いに高い相関関係にあり、一般的な性能メトリクスとの間にも相関が見られます。つまり、最もパフォーマンスの良いモデルは、最も公平性の高いモデルの中にあるようです。
具体的には、モデルの構成をランク付けして、最もパフォーマンスの良いモデルのみを調査することができます。
rank_results(wflow_set_fit, rank_metric = "roc_auc") %>%
filter(.metric == "roc_auc")
#> # A tibble: 42 × 9
#> wflow_id .config .metric mean std_err n preprocessor model rank
#> <chr> <chr> <chr> <dbl> <dbl> <int> <chr> <chr> <int>
#> 1 age_bt Preprocessor1_… roc_auc 0.605 0.00424 10 recipe boos… 1
#> 2 basic_bt Preprocessor1_… roc_auc 0.605 0.00423 10 recipe boos… 2
#> 3 age_bt Preprocessor1_… roc_auc 0.604 0.00378 10 recipe boos… 3
#> 4 age_bt Preprocessor1_… roc_auc 0.603 0.00421 10 recipe boos… 4
#> 5 basic_bt Preprocessor1_… roc_auc 0.603 0.00410 10 recipe boos… 5
#> 6 basic_bt Preprocessor1_… roc_auc 0.603 0.00436 10 recipe boos… 6
#> 7 age_bt Preprocessor1_… roc_auc 0.602 0.00372 10 recipe boos… 7
#> 8 basic_nn Preprocessor1_… roc_auc 0.602 0.00403 10 recipe bag_… 8
#> 9 age_nn Preprocessor1_… roc_auc 0.600 0.00431 10 recipe bag_… 9
#> 10 age_nn Preprocessor1_… roc_auc 0.600 0.00412 10 recipe bag_… 10
#> # ℹ 32 more rowsほとんどの最もパフォーマンスの良いモデル構成は、ブースティング木のモデリングワークフローから生じています。特に年齢を数値としてエンコードするモデリングワークフローの結果を詳しく調べましょう。
autoplot(wflow_set_fit, id = "age_bt")
学習率(learn_rate)が結果のメトリクスに与える影響は、ランダムに選択される予測子の数(mtry)よりも顕著であるようです。先ほどと同様に、roc_auc()に関して最もパフォーマンスの良いモデルは、公平性メトリクスに関しても最も公平性の高い傾向が見られます。さらに、上記でプロットされた各公平性メトリクスの値は高い相関関係にあります。
さまざまな利害関係者の期待を満たすことを希望する実務家の観点からすると、これらのメトリクスが高い相関関係にあるという事実は、モデル選択プロセスを大幅に容易にします。私たちは、最適化したい公平性メトリクスを1つ選び、他のメトリクスについてもほぼ最適な構成を得ることができるでしょう。
ただし、機械学習の公平性に関して、「不可能定理」によれば、「一般には数学的にも倫理的にも一致しない」とされています(Mitchell et al. 2021)。具体的には、不平等が存在する限り、多くの公平性の定義を同時に満たす方法はありません。しかし、最近の研究では、ここで使用したような3つのメトリクスのような、より限定されたセットの近くにある公平性は可能であり、重要であると強調されています(Bell et al. 2023)。
typical performance metric(roc_auc()など)と選択した公平性メトリクスの両方に関して良好なパフォーマンスを発揮するモデルを選択するために、複数のメトリクスに基づいて同時に最適化するために、希望関数(desirability functions)を利用します。
best_params <-
# extract the tuning results for the boosted tree model
extract_workflow_set_result(wflow_set_fit, "age_bt") %>%
# collect the metrics associated with it
collect_metrics() %>%
# pivot the metrics so that each is in a column
pivot_wider(
id_cols = c(mtry, learn_rate),
names_from = .metric,
values_from = mean
) %>%
mutate(
# higher roc values are better; detect max and min from the data
d_roc = d_max(roc_auc, use_data = TRUE),
# lower equalized odds are better; detect max and min from the data
d_e_odds = d_min(equalized_odds, use_data = TRUE),
# compute overall desirability based on d_roc and d_e_odds
d_overall = d_overall(across(starts_with("d_")))
) %>%
# pick the model with the highest desirability value
slice_max(d_overall)結果として得られるのは、最良のモデルを示すパラメータ値が記載されたテーブルです。
best_params
#> # A tibble: 1 × 10
#> mtry learn_rate accuracy demographic_parity equal_opportunity equalized_odds
#> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 7 0.00456 0.912 0 0 0
#> # ℹ 4 more variables: roc_auc <dbl>, d_roc <dbl>, d_e_odds <dbl>,
#> # d_overall <dbl>We can use that tibble to finalize a workflow that we’ll use to generate our final model fit:
final_model_config <-
extract_workflow(wflow_set_fit, "age_bt") %>%
finalize_workflow(best_params)Finally, generating our final model fit:
final_model <-
last_fit(final_model_config, readmission_splits, metrics = m_set)collect_metrics(final_model)
#> # A tibble: 5 × 5
#> .metric .estimator .estimate .by .config
#> <chr> <chr> <dbl> <chr> <chr>
#> 1 accuracy binary 0.912 <NA> Preprocessor1_Model1
#> 2 equal_opportunity binary 0 race Preprocessor1_Model1
#> 3 equalized_odds binary 0 race Preprocessor1_Model1
#> 4 demographic_parity binary 0 race Preprocessor1_Model1
#> 5 roc_auc binary 0.602 <NA> Preprocessor1_Model1ここで選択したモデルは、ここで選んだメトリクスセットに対してほぼ公平性を持っています。モデルの正確度は91.16%であり、モデルが常に患者が再入院しないと予測した場合の正確度(91.2%)とほぼ同じです。roc_auc()値が0.602であることから、モデルは一部のケースで再入院を正しく予測していることを示していますが、改善の余地がまだ大きいです。さらに、これらのモデルの分析では、実際に再入院した少数クラスの観測に特化したメトリクス(例えば、sens())を使用してパフォーマンスを測定することが考えられます。
最後の_fitオブジェクトからモデルの適合を抽出します。
final_model_fit <- extract_workflow(final_model)The final_model_fitオブジェクトは、新しいデータに対して予測する準備が整いました!tidymodelsで生成されたモデルは、簡単にバージョン管理され、展開され、vetiverフレームワークを使用して監視されます。vetiverフレームワークについては、vetiverのウェブサイトで詳細を確認することができます。
この記事では、公平性指向のモデリング分析を示しました。公平性を考慮したモデリングは単なる数値最適化の問題ではなく、問題の文脈での公平性の道徳的意味を総合的に検討し、それがさまざまな数学的公平性の概念によってどのように表現されるか、または表現されないかを考える過程です。
この分析により、限られた公平性メトリクスに基づいて公平性に近いモデルをトレーニングすることができましたが、このようなモデルの使用がもたらす影響についてはまだ多くの疑問が残されています。その中には次のような点が含まれます:
私たちは人種を考慮してモデルの公平性を評価しましたが、患者の性別に関する情報もあります。このモデルは患者の性別に対して不公平な振る舞いをする可能性がありますか?人種と性別の交差点に関してはどうでしょうか? 黒人女性が患者として著しい差別を経験していることを示す研究が増えています(Johnson et al. 2019; Okoro, Hillman, and Cernasev 2020; Gopal et al. 2021)。
私たちがアクセスできる人種/民族性と性別のカテゴリは粗いものです。人種/民族性と性別/ジェンダーは多様で豊かに経験されるものであり、患者が医療の文脈で提示される(または無意識に割り当てられる)限られたカテゴリは、患者がそれをどのように経験するかの代理でしかありません。
再入院を必要とするかどうかの指標として再入院を使用しましたが、患者が自発的に再入院する要因は何でしょうか? また、最初に入院するかどうかは何が影響しますか? 特に、貧しい患者にとって医療の負担が不均衡であることに留意してください。
私たちはこのモデルの予測が実務家によってどのように使用され、患者によってどのように信頼されるかを知りません。モデルの出力は、もちろん患者の滞在中に医療チームによって収集された他の証拠と共に評価される必要があります。しかし、これを知ることで、モデルの出力は患者集団の異なるグループに対して異なるように解釈されるでしょうか? たとえば、白人男性にとって再入院の予測が追加のケアが必要な根拠としてより深刻に考えられることがあるでしょうか? さらに、歴史的な搾取や非倫理的な実践を考慮すると、保護されたグループはアルゴリズムによる追加のケアの推奨が差別的である可能性が高いと信じ、それらに提供される推奨を信頼しないかもしれません(Rajkomar et al. 2018)。
機械学習モデルは私たちの生活に重大なポジティブな影響を与える一方で、重大な害を引き起こすこともあります。私たちの社会でこれらのモデルの影響力が非常に大きいため、公平性を機械学習モデルの評価基準として含める努力は今なお必要不可欠です。