
第1回 DataFrameとIndexの関係

DataFrameとは
DataFrameとは、データ行列を扱うクラスです。Pandasを利用する際に必ず利用するクラスと言っていいでしょう。DataFrameは便利な関数を持っており、中身を意識せずに、様々な処理を実現できます。ただし、きちんと理解していないと、より良いPandasコードを書くことはできません。そして、Pandasをきちんと理解する為のポイントとなるのは、PandasのIndexクラスなのです。
皆さんの中にもよく分からないけどDataFrameのオブジェクトからreset_index関数を呼び出している人がいると思います。reset_index関数は、一体何をしているのか?これを理解するために、今回はDataFrameとIndexの関係を解説します。
DataFrameの構造
先ほどDataFrameは、データ行列を扱っていると説明しましたが、正確には、DataFrameは行名と列名も管理しています。そして、行名と列名を管理するクラスこそが、Indexクラスなのです。具体的には下記の図のような構造になっています。

行名は、DataFrameオブジェクトのindexプロパティにIndexオブジェクトとして保持しています。同様に、列名は、DataFrameオブジェクトのcolumnsプロパティにIndexオブジェクトとして保持しています。(ちなみに、DataFrameオブジェクトのaxesプロパティにアクセスすれば、indexとcolumnsのリストとしてまとめて取得できます。)
データ行列は、DataFrameオブジェクトの_seriesプラパティに全データ列のdictオブジェクト(keyは列名、valueはデータ列のSeriesオブジェクト)として保持しています。ただし、_seriesプロパティは直接利用することは推奨されていません。その代わりに、DataFrameオブジェクトのvaluesプロパティを利用することで、numpyのndarrayとして全行列のデータ値を取得できます。
DataFrameの構造を確認するコード





DataFrameへのアクセス
valuesプロパティでDataFrameの全データ値を取得することができますが、特定の列や行を指定して取り出すための関数も提供されています。このような関数はいくつか使い方に応じて提供されていますが、しっかり理解しないと混乱を招きます。その理解の大きな手助けになるのは、Indexクラスを経由したアクセスなのか、Indexクラスを経由しないアクセスなのかを把握することです。
Indexクラスを経由しないアクセス
Indexクラスを経由しないということは、つまり行名と列名を用いないでアクセスするということです。その場合、行番号または列番号を用いてアクセスすることになります。
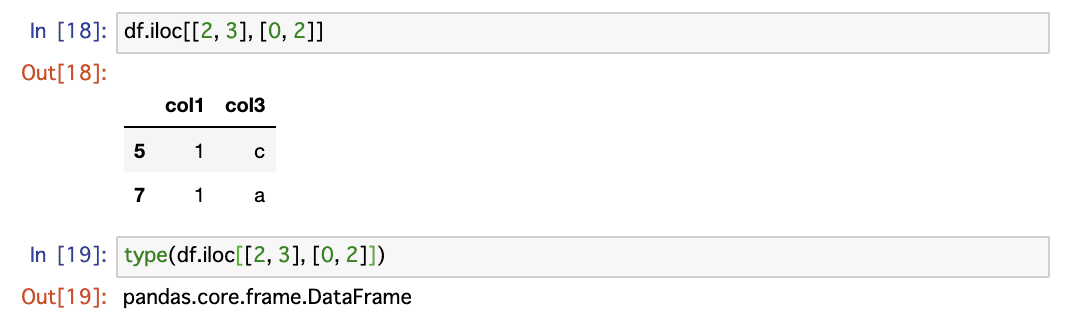
アクセスする関数の一つとして、iloc関数があります。iloc関数は、行番号と列番号を指定して、データを取得する関数です。具体的には、下記の通りです。
// 指定した行番号のSeriesオブジェクトを取得。
df.iloc[行番号]
// 指定した行番号のリストのDataFrameオブジェクトを取得。
df.iloc[行番号リスト]
// 指定した列番号のSeriesオブジェクトを取得。
// :は、全ての行/列番号のリストの指定を意味します。
df.iloc[:, 列番号]
// 指定した行番号と列番号のデータ値を取得。
df.iloc[行番号, 列番号]
// 指定した行番号リストと列番号リストのDataFrameオブジェクトを取得。
df.iloc[行番号リスト, 列番号リスト]
iloc関数は、1次元目に行番号、2次元目に列番号を指定することで、データを取得できる関数です。指定方法で、返り値のデータ型が異なることに注意してください。
iloc関数だけでなく、iat関数でも行番号と列番号を指定してデータ値を取得することができます。ただし、iat関数は、必ず行番号と列番号を1つずる指定して、1つのデータ値を取得する関数です。
// 指定した行番号と列番号のデータ値を取得。
df.iat[行番号, 列番号]行番号、列番号を利用したデータ取得を行う関数は、関数の最初にiが基本的についています。iがついていたら、行番号、列番号の取得だなと意識しましょう。
// 指定した行名のSeriesオブジェクトを取得。
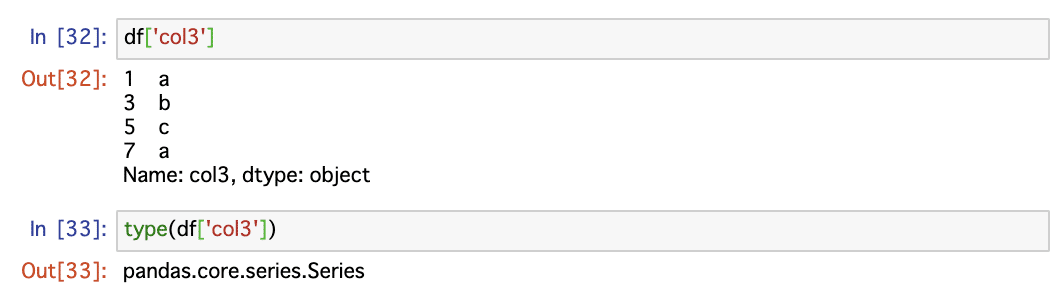
df[列名]
// 指定した列名リストのDataFrameオブジェクトを取得。
df[列名リスト]Indexクラスを経由しないアクセスのサンプルコード




Indexクラスを経由するアクセスのサンプルコード
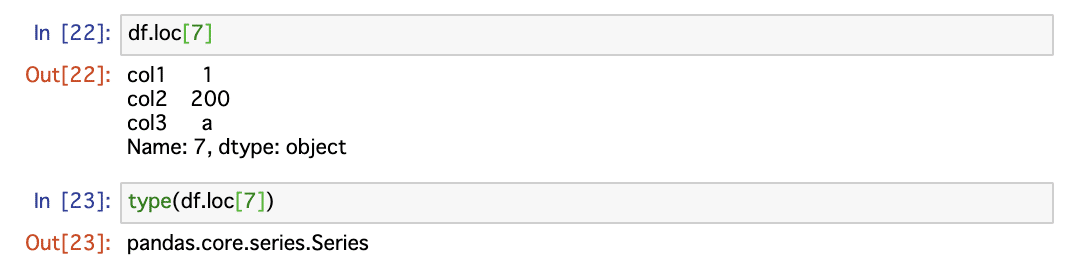
Indexクラスを経由して、つまり行名と列名を用いてアクセスする関数には、loc関数があります。loc関数は、行名はDataFrameオブジェクトのindexプロパティのIndexオブジェクトの値から判定され、列名はDataFrameオブジェクトのcolumnsプロパティのIndexオブジェクトの値から判定されます。
// 指定した行名のSeriesオブジェクトを取得。
df.loc[行名]
// 指定した行名のリストのDataFrameオブジェクトを取得。
df.loc[行名リスト]
// 指定した列名のSeriesオブジェクトを取得。
// :は、全ての行/列名のリストの指定を意味します。
df.loc[:, 列名]
// 指定した行名と列名のデータ値を取得。
df.loc[行名, 列名]
// 指定した行名リストと列名リストのDataFrameオブジェクトを取得。
df.loc[行名リスト, 列名リスト]
iloc関数とiat関数の関係と同様に、loc関数に対してはat関数が存在します。at関数は、必ず行名と列名を指定して、1つのデータ値を取得する関数です。
// 指定した行名と列名のデータ値を取得。
df.at[行名, 列名]
また関数を用いず、直接1次元目に列名を指定してデータを取り出す方法もあります。特定の列だけ取り出したいケースは、データ分析においては多く、よく利用するので覚えておきましょう。
Indexクラスを経由するアクセスのサンプルコード





関数による行名の変更
DataFrameオブジェクトのindexプロパティに直接Indexクラスを設定することもできますが、関数を使って変更することができます。その関数は、set_index関数とreindex関数とreset_index関数です。
set_index関数は、引数に指定した列名のデータ列を行名(indexプロパティ)に設定する関数です。
// 指定した列名のデータ列を行名に設定。
df.set_index(列名)
// 指定した列名リストの複数のデータ列を行名に設定。
df.set_index(列名リスト)
reindex関数は、引数に指定したデータ値を行名(indexプロパティ)に設定する関数です。同じ行名が存在しているデータ行は、元のデータ値が格納されており、存在しなかったデータ行は、空のデータ値が格納されている。axis=1に指定することで、対象を行から列に変更することができます。columns引数に値リスト指定することでも、対象を列に変更することができます。
// 指定した値リストを新たな行名/列名に設定。
df.reindex(値リスト, axis=0 or 1)
reset_index関数は、設定されている行名(indexプロパティ)をリセットして、新たな行名を設定する関数です。オプションパラメータdropをTrueにすると設定されていた行名は破棄されます。dropをFalseにすると設定されていた行名はデータ行として追加される。新たに設定される行名は0からの連続値が設定されています。(型は、RangeIndexが採用されています。詳しくは第2回で解説します。)
// 設定されている行名を破棄して、新たな行名を設定。
df.reset_index(drop=True or False)
関数による行名の変更のサンプルコード



まとめ
DataFrameとIndexの関係は分かりましたか?DataFrameの行名と列名を関するのがIndexクラスの大きな役割です。特に行名を扱うのは直感的でなく、違和感があるかもしれません。そのため多くの人は行名を意識しないで済むように、reset_index関数を定期的に呼び出しているのが実態なのでしょう。しかし、Pandasの処理はこの行名こそが多くの変換処理の実現を担っており、これらを理解すれば1つ上のレベルのPandas使いになれるでしょう。
この記事が気に入ったらサポートをしてみませんか?