
DeepSeek R1 671Bモデルは普通のゲーミングPCで一応動く(1.58bit量子化)

しぴぴぴ!
Vtuberのしぴちゃん (https://www.youtube.com/@CP-chan) です。
YouTubeではゲームとか麻雀とかの話しかしてませんが、今回はローカルAI関連の連載企画です。
今回は箸休め回です。気軽に読んでください。
連載の第一弾で、ローカル環境でDeepSeek R1の14Bモデルを動かしてみました。
この14Bというのはモデルのパラメータ数のことで、14Bとは14 billion、つまり140億パラメータのことです。
元々のDeepSeek R1は671B、6,710億パラメータあるのですが、それを蒸留という手法を使って小さいモデルに移植して小型化しています。もちろんその際に多少性能が落ちますが、第一弾を読んで実際動かして頂ければ14Bでもなかなか賢いということがわかります。
その後、Unslothという団体?から、DeepSeek R1
(蒸留していない671Bパラメータのもの。以降フルモデルと言います)
を1.58-bit 量子化したものが公開されました。
https://unsloth.ai/blog/deepseekr1-dynamic
量子化とは、パラメータの精度を落としてモデルのサイズを減らし、小さいマシンでも動くようにする技術です。元々16bitのモデルを8bit, 6bit, …と精度を落としていくと、モデルサイズは小さくなりますが、その分LLMとしての性能も落ちるとされています。
上のURL(以降、Unslothのブログポスト、または単にブログポストと書きます)によれば、1.58-bit 量子化によってモデルのサイズが80%削減され、一方でフラッピーバードゲームを実装させることができるなど、性能はある程度維持されているということです。
80%削減されたといっても130GBもあるんだし、普通のゲーミングPCでは動かないでしょ…と思っていたのですが、同ブログポストによれば
You don't need VRAM (GPU) to run 1.58bit R1, just 20GB of RAM (CPU) will work however it may be slow.
GPUがなくても20GBのメモリがあれば動く、ただし遅いかも…
ということです。
動くというのなら動かしてみましょう。そしてどのくらい遅いのか見てみましょう。
動作環境
Windows 11
メインメモリ 32GB
GPU NVIDIA RTX 3080 VRAM 10GB
実際に動かす
1.
第一弾の記事を参考に、CUDA版のllama.cppを導入します。
2.
モデル本体をダウンロードします。
unsloth の huggingface リポジトリから、三つのggufファイルをダウンロードします。131GBあります。
3.
ブログポストの計算式(下記)を参考にして、GPUに載せるレイヤー数を計算します。ブログポストに書いてあるように、n_layers=61です。
RTX 3080のVRAMは10GBなので、0です。悲しいですね。
0でも本体以外のレイヤーをGPUに載せることで多少高速化できるので、ないよりマシです。
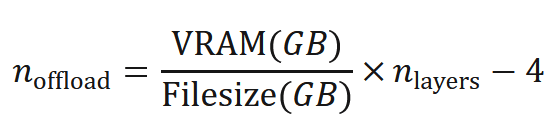
4.
ブログポストのコマンド例を参考にして本体を起動します。w64webkitは日本語を正しく入力・表示できないので、ブログポストにあるllama-cliではなくllama-serverを起動します。
また、min_p = 0.1 or 0.05がよいとブログポストに書いてありますが、llama.cppのデフォルト値は0.05なので問題ないでしょう。
llama-server.exe -m ../LLM-models/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf --cache-type-k q4_0 --threads 12 --prio 2 --temp 0.6 --ctx-size 8192 --verbose -ngl 0モデルが巨大なので、まず準備のために数分待ちます。準備が完了したら、タスクマネージャーを睨みながら対話を開始します。
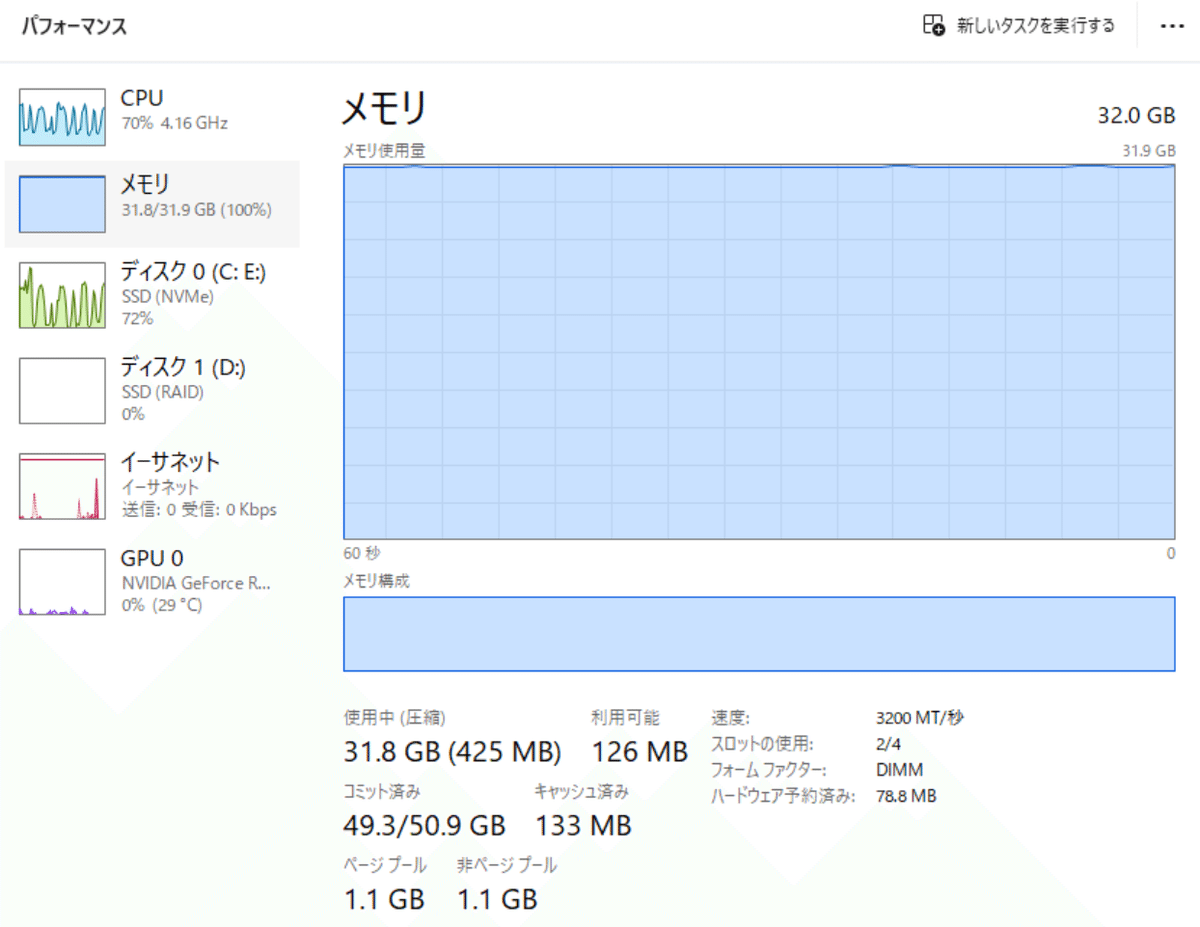
メモリがMAXに張り付きながらもギリギリ動きます。
VRAMとメモリを合わせてもモデルが載りきらない場合、毎回モデルのロードアンロードが繰り返されるため、モデルが保存されているディスク0(NVMe SSD)にも大量の読み出しが走ります。

生成結果は上のスクリーンショットのようになっています。これは生成途中なので、途中で切れています。
日本語はちゃんと話せます。「層流」に対して「れんけいりゅう」と読みがなを振るなどちょっと怪しいところがありますが、内容はまあまあ正しそうです。
しかし、そんなことよりも遅すぎて実用は無理です。数秒に1ワードまたは1文字出力されるので、1プロンプトに1時間くらいかかります。
しぴちゃんは短気なので途中で諦めてしまいました。
70Bで妥協する
671Bは無理だったので、一番大きい蒸留モデルであるDeepSeek-R1-Distill-Llama-70Bを1.58bit量子化したものを動かしてみましょう。
ちゃんと誰かが量子化してくれています。
同じ量子化レベルである DeepSeek-R1-Distill-Llama-70B.i1-IQ1_S.gguf をダウンロードし、同じようにGPUにロードするレイヤー数を計算します。
このモデルのモデルサイズは14.3GB, n_layers=41なので、GPUにロードできるレイヤー数は24くらいです。
llama-server.exe -m ../LLM-models/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf --cache-type-k q4_0 --threads 12 --prio 2 --temp 0.6 --ctx-size 8192 --verbose -ngl 0こちらはまだマシです。1~2 words/sec 出ます。

長考されすぎたので途中で止めました。日本語能力にやや難があるのか、ナビエ・ストークス方程式をNavie Stokes formulaと訳してそんなものないぞ…?となり長考しています。
正しくはNavier-Stokes equationです。仕方ないので英語で話しかけてあげましょう。

英語で話しかけると、内容はまあ間違ってないけど要素が足りてない(解き方についての回答がない)し、In Japanese: と言いながら英語でそのまま繰り返すなど、正直あんまり出来が良くないと言わざるを得ない様子です。
70BのIQ1_S量子化はダメなようですね。
結論
普通のゲーミングPC (メモリ 32GB, NVIDIA RTX 3080 VRAM 10GB)では、
671B 1.58bitは動くけど遅すぎ。
70B 1.58bitは遅すぎはしないけど性能が足りてない。
生成速度と性能のバランスを考えると、普通のマシンでは14Bか32Bあたりが無難なようです。
なお、CPUでもRAMが80GBくらいあればしぴちゃんPCより速く動くと思います。
モデルがRAMにもVRAMに載りきらない場合、一部を読み込んでその部分だけ推論してメモリを開放して残りを読み込んで…と、何度もディスクにアクセスすることになります。
もしあなたが超ハイスペックマシンをお持ちであれば、この記事に従えばDeepSeek R1のフルモデル(1.58bit量子化)を快適に?動かすことができるはずです。
まともに使える速度で動かせたらコメントで自慢してください。
Appendix
なぜ70BのIQ1_S量子化がダメなのか?について、iMatrix量子化時の日本語性能を検討している記事がありました。
iMatrix量子化を行ったとき、2bitの量子化では日本語のタスク性能が顕著に低下し、また3bit以下の量子化ではモデルのperplexityが英語よりも顕著に増大することが記述されています。日本語をiMatrixデータセットに入れれば日本語性能が向上するとしていますが、海外製の汎用量子化モデルではそういうことはしてくれないですね。
なお、Perplexityは以下の記事などに説明がありますが、モデルが次に来るトークンをどの程度まで絞り込めているかの指標で、小さい方が良いです。
結論として、日本語を話させる場合、日本語用にチューニングしたものでなければ3bit以下の量子化は使わない方が無難です。
モデルサイズを下げてでもQ4_K_MやQ5_K, Q6_Kを使いましょう。