
SnowflakeからAWSのS3バケットにテーブルを保存の手順

こんにちは!! コグラフSSD−2事業部のルイスです。
本日、Snowflakeのアウトプット出力テーブルをAWSのS3バケットに保存する方法を紹介したいと思います。この方法は、Snowflakeで外部ステージを作成することです。
この手順を実行するには、SnowflakeとAWSの両方のアカウントが必要です。
S3バケットを作成
最初のステップでは、ファイルを保存するため、S3バケットを作成する必要があります。S3バケットを作成するには、AWSコンソールを開いて、検索バーでS3を記入してください。次に、通常オレンジ色で表示されるバケット作成ボタンを押します。
設定としては、snowflake_outputやexternal stage outputなど適当な名前をつけて、create bucketを押します。重要な点は、AWSのリージョンがSnowflakeのアカウントと同じである必要があります。

CSVフォーマットを作成
次のステップは、ファイルフォーマットを作成することです。この例では、cvsファイルフォーマットを使用します。フォーマットを作成するには、Snowflake アカウントのワークシートに移動し、以下のコードを記述します。
CREATE OR REPLACE FILE FORMAT my_csv_format
TYPE = CSV
FIELD_DELIMITER = ','
SKIP_HEADER = 0
NULL_IF = ('NULL', 'null')コードによると、この後、選択するオブジェクトは、csvファイルに変換され、ヘッダを保持し、区切り記号はカンマで、テーブルにNULL値がある場合は、nullという単語が表示されます。
外部ストレージインテグレーション
ファイルフォーマットを作成すると、同じワークシートでストレージインテグレーションを作成します。このストレージはSnowflakeとAWSのS3を接続するために必要です。
下記の通りをストレージを作成できます。
CREATE OR REPLACE STORAGE INTEGRATION INTEGRATION_READ_FILE
TYPE = EXTERNAL_STAGE
ENABLE = TRUE;外部ストレージを作成するため管理アカウントまたは特権持っているアカウントで作成しないといけません。またはAWSのIAMロールは同じくSnowflakeと接続するためにもS3バケットのアクセス許可を設定してください。やり方はこちらのSnowflakeのサイトで参照してください。
設定を完了するとARNのポリシーやS3バケットのリンクをストレージに追加をします。
USE ROLE ACCOUNTADMIN ROLE;
CREATE OR REPLACE STORAGE INTEGRATION INTEGRATION_READ_FILE
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
SOTRAGE_AWS_ROLE_ARN = ' ' ### COMENT1
STORAGE_ALLOWD_LOCATION = ' ' ### COMENT 2STORAGE_AWS_ROLE_ARNはは作成したロールのAmazonリソース名(ARN)です
'arn:aws:iam::001234567890:role/myrole'
STORAGE_ALLOWED_LOCATIONはデータファイルを保存するS3バケットの名前です。例えば's3://<bucket>/<path>/'。(前のステップに作成したバケットです)
S3バケットをアップグレードするための外部IDの取得
DESCRIBE INTEGRATIONコマンドを実行して、Snowflakeアカウント用に自動作成されたAWS IAMユーザーのARNを取得します
DESC INTEGRATION INTEGRATION INTEGRATION_READ_FILEアウトプットはこんな感じになります
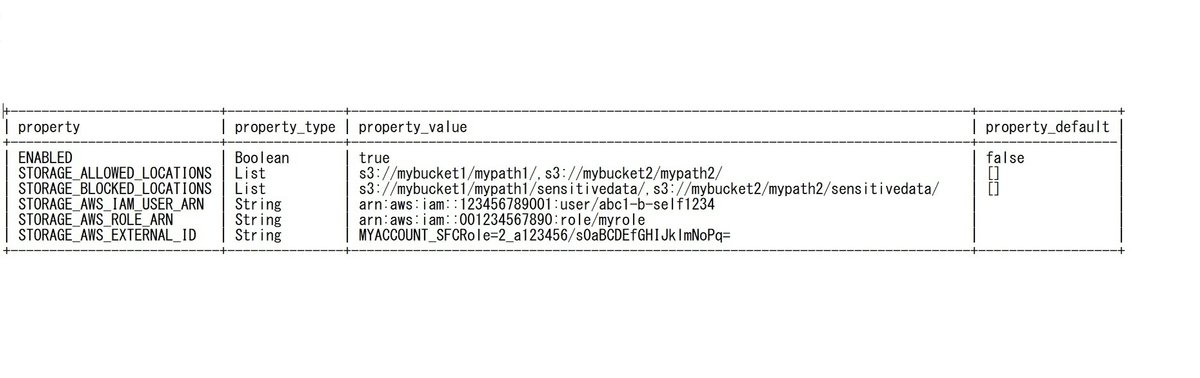
s3に接続するには次の2つの値が必要です。
storage_aws_iam_user_arnとstorage_aws_external_id。
IAMユーザーにバケットオブジェクトへのアクセス権限を付与する。
AWS Management Console にログインし、Identity & Access Management (IAM) に移動してください。左側のナビゲーションペインからRolesを選択します。リストの中にはSnowflakeとs3の接続に使用しているロールをクリックし、[Trust relationships]タブをクリックします。
信頼関係を編集し、DESC STORAGE INTEGRATION 出力値でポリシードキュメントを修正します。最後に信頼ポリシーを更新することです。


ステージを作成する
先ほど作成したS3ストレージインテグレーションを参照する外部ステージを作成することは必要です。コマンドは下記で書いています
CREATE OR REPLACE STAGE FILECSV url = "s3://bucket1/path1/'" #s3バケットのURLを記入してください
STORAGE_INTEGRATION = INTEGRATION_READ_FILE
FILE_FORMAT = my_csv_format;このステップに2つ注意点はあります
1)URL 値にスラッシュ(/)を追加して、指定したフォルダーパスにフィルターをかけます。スラッシュを省略すると、指定したパスのプレフィックスで始まるすべてのファイルとフォルダーが含まれます。2)ステージ内の非構造化データファイルにアクセスして取得するには、スラッシュが 必須 であることに注意してください。
使い方の例
snowflakeの出力をcsvファイルに変換し、s3に保存するには、前のステップで作成したステージを使用する必要があります。TEST_RESULTSというテーブルがあり、同じ名前でs3に保存したい場合、以下のコードを実行する必要があります。
COPY INTO @FILECSV/test_results
FROM
(SELECT * FROM TEST_RESULTS)
FILE_FORMAT = my_csv_format
SINGLE = TRUE
HEADER = TRUE
DETAILED_OUTPUT = TRUE;このコードでは、test_resultsテーブルから取得したすべてのデータをコピーし、test_resultsとして保存している。先に作成したステージを使っているので、自動的にs3バケットにcsvとして保存されます。
single_trueは指定した名前で保存、FALSEは自動生成、headerはテーブルのヘッダを保存したいのでTRUE、detailed_outputはs3に保存した後に詳細を見たいのでTRUEになります。
おわり
この記事が、awsでsnowflakeを使用する際の日々のタスクに役立つことを願っています。
次回はExcelからSnowflakeにデータを登録することを学びますので次回もお楽しみしてください。

この記事が気に入ったらサポートをしてみませんか?