
15.LoRAの作成(キャプションのタグ付け)

SD3やFluxも出てきて、LoRAを作ろうとする人が(たぶん)増えてきたから、トリガー、タグ付け、キャプション、について説明していこうかな
(トリガーを含むタグを束ねたのがキャプション…かな)

初めに
画像を説明するためのキャプション(トリガー、タグ)を設定するのだけれど、画像について説明が多いのがこまごまとした単体、説明が少ないのがトリガーに対して大まかなものになる。
逆に言えば、各画像で設定してあるキャプションを全部入れて生成すると、その画像に近いものが生成されるという事。

部分学習の場合は、トリガーが部分的な扱いになるので、使い勝手が良くなる。
顔だけトリガーで学習されていれば、トリガーだけでは顔しか出ないから、服や背景はベースモデルから選ばれることになる。

全体学習の場合は、トリガーが画像内全ての扱いになるので、使う場合は学習された絵から書き換えていくという状態になる。
汎用性が少なくなるけど1単語で済む。
①一般的な考え方(部分学習)
絵を構成する部分としてトリガーをつける
一度、画像にあるものをなるべく詳細に単語として並べて、
学習させたいところだけをひとつの単語に置き換える。
そのことで、bare foot,white scarf,aqua ribbon,scrunchie,maid like fluffy hat with frills ,bare shoulder,hair ribbon,long clothes なんて長いものを入れなくても、
fluffymaiddressを入れるだけでこの服が生成されるように学習しようということ
同じ感じで、説明できないものもこれで学習させることができる
なので、他を説明する文章がなければ、fluffymaiddressで髪型とかポーズなども学習されてしまうので、black hairやsitなど詳細に書こうというのが一般的なやり方。
(トリガーはベースモデルにない固有の名前の方が、元の学習に押しつぶされて、変わらないと言う事が少なくなる)

通常
black hair,yellow eyes,river,lake,road,riverbank,sit,smile,long hair,black hair,screnery,tree,grass,wood,cloud,pastel color,bare foot,white scarf,aqua ribbon,scrunchie,maid like fluffy hat with frills ,bare shoulder,hair ribbon,long clothes,
↓覚えさせたい服の部分を1単語にしてトリガーとして先頭に
fluffymaiddress, black hair,yellow eyes,river,lake,road,riverbank,sit,smile,long hair,black hair,screnery,tree,grass,wood,cloud,pastel color,bare foot,white scarf,aqua ribbon,scrunchie,maid like fluffy hat with frills ,bare shoulder,hair ribbon,long clothes,

black hair,yellow eyes,blue eyes,riverbank,sit,smile,long hair,black hair,tree,grass,wood,star,pastel color,bare foot,white scarf,aqua ribbon,scrunchie,maid like fluffy hat with frills ,bare shoulder,hair ribbon,long clothes,cat,wood box,
↓覚えさせたい服の部分を1単語にしてトリガーとして先頭に
fluffymaiddress, black hair,yellow eyes,blue eyes,riverbank,sit,smile,long hair,black hair,tree,grass,wood,star,pastel color,bare foot,white scarf,aqua ribbon,scrunchie,maid like fluffy hat with frills ,bare shoulder,hair ribbon,long clothes,cat,wood box,
同じように何枚もやっていって、なるべく多い画像数だと安定が増していく

<難しくて、ルレィナちゃんが諦めた!!>
②ここあてぃな考え方(全体学習)
絵を説明するトリガーとしてつける単語を沢山並べるのがめんどくさい私はAIに丸投げします。人物や背景やポーズなどもコミコミプランでトリガーとして設定。
なので、トリガーだけを入れれば学習に使った絵がそのまま出てくることになる。
作った画像やフリー画像ならセーフかもだけど、インターネットから適当に入手したものを入れこむのには適さないやり方とも言える。
※なぜなら同じ絵=贋作=著作権を問われる
学習させたいものに一番近い単語を探すところから始まり、
その単語がプロンプトに出てきたらここぞとばかりに描いてもらう感じかな
(一般的なやり方と逆で、ベースモデルで学習されてるものから強引に別のものに差し替えてしまおうというもの)

今回の場合、一番難しそうなのは頭の「説明できない帽子」であること、
fluffyは表現できる。
ハットかフードと迷うけど、フードだと長袖になったりする可能性が経験上高いので hat を選択。
後は基本の maid
覚えなかったらbare shoulder入れればいいやってことで、
fluffy hat maid にトリガーを決定。
これの何が良いって…
基本的に他の画像も同じキャプションで済むと言う事!🥳
ただ、今回の場合座っているポーズの学習が強くて、立たなくなっちゃったりしたら、トリガーのfluffy hat maidだけじゃなくて、sitとかを入れると、立ちやすくなるね。ポーズだけ切り離して学習させる感じかな。

素直でよろしい。
TensorArtで実践
設定とかは以前の記事を参考にしてね
https://note.com/cocoat/n/n29d4ca336d1f#8e049276-f7aa-4932-8b1a-cd6f84eadbfb


今回はせっかくなので、SD3で作ってみた。
↓↓↓↓ 作ったLoRAを使ってSD3で生成 ↓↓↓↓
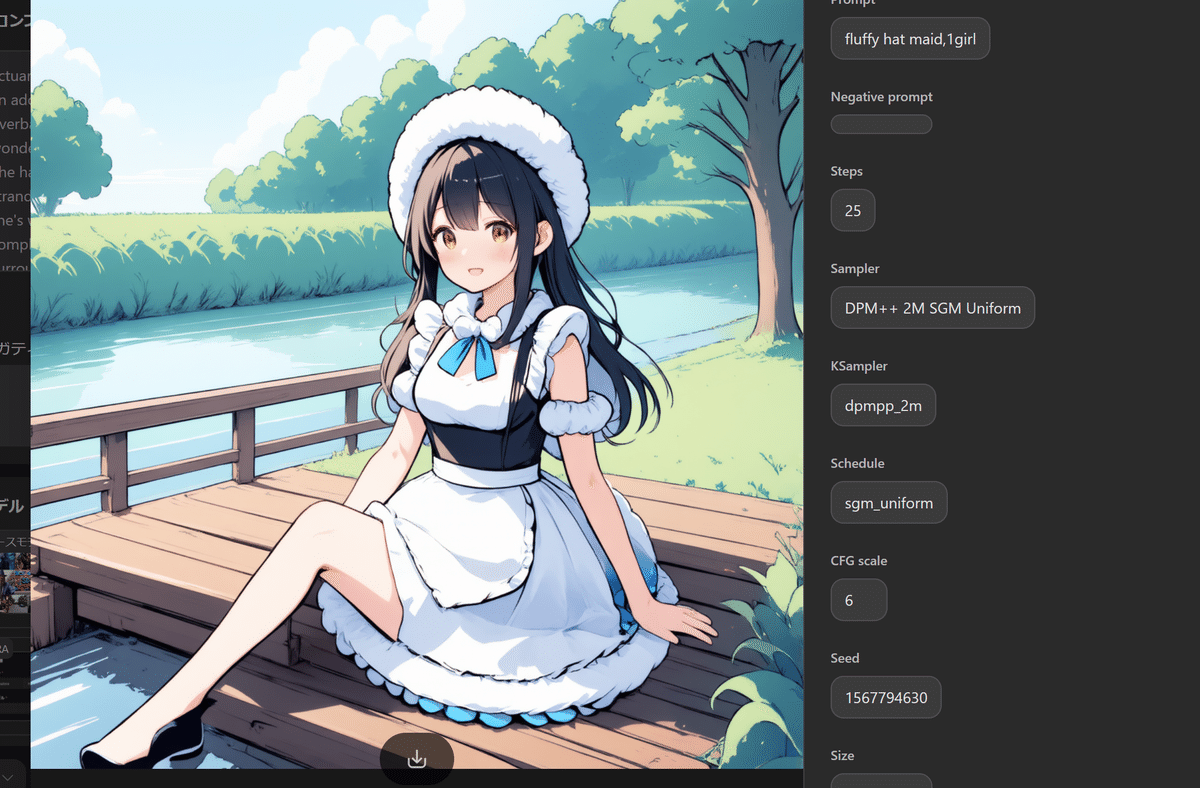
ところどころアレなのはアレなので察していただけると…
今回の目的は学習させると言う事で、足を2本にするという議題ではないので…ハイ。
(※ガチャ運がないんです)


補足
キャプションに入っている単語でその絵が出るように学習させるから、
覚えさせたいもの以外は、単語を入れて切り離してねってこと。
例えば…


という事…なんだけど

おしまい!
最後まで読んで頂きありがとうございます。何かの参考になれば嬉しいです
