
【アプリ開発日記59週目】狙ったキャラを自分の絵柄&好きなポーズで作成する〈SD後編〉

「自分の絵柄でキャラ絵をいろいろ創りたい!」
いよいよ今回で最初の区切りにしようと思います。というのもこの分野、毎日のように新技術が生まれてきているので、同じ目標にしていても次々と試す余地が出てきてキリがないのです笑
といっても今後も画像生成は続けるつもりなので、これからまた画像生成日記が出てきた時は何卒よろしくお願いいたします!
そこで今回は「自分の絵柄でキャラ絵をいろいろ創りたい」を、今までの「DreamArtist」「ControlNet」そして今まで触れていなかった「HyperNetwork」「LoRA」を組み合わせて試行錯誤していきます。

(HyperNetworkがあまりに長くなってしまったため、結果が気になる方は画像を中心にご覧ください!笑)
※2023/3/9追記:57~59週目の内容を、備忘録としてまとめました。Stable Diffusionが使える状態で「自分の絵を学習させたい!」の結論が気になる方は、以下の記事をご覧ください!
1,Hypernetworksを試してみる
まず、前回見つけた「キャラが割と高い精度で再現できる!」と噂のHyperNetworkさんを試してみます。
そもそも追加学習についてよくわかっていなかったので、いろいろ調べてみると
追加学習には様々な手法があり今回は大きく分けて 3 つあり、今回はその『転移学習』『ファインチューニング』『蒸留』についてそれを使うメリットとデメリット、簡単な概要を…
そしてファインチューニング手法の中にもいくつかあり、Textual inversion や Dream Boothが代表的です。DreamArtistもTextual inversionの応用系。一方、以前からちらちらと見かけていた「Hypernetworks」も数枚~数十枚で高い再現性を持つ(特に同じキャラを再現するのが得意)とのことだったので、さっそく実験していきます!
【各学習モデルのファイル格納場所】
・checkpoint(.ckpt, .safetensors)
/stable-diffusion-webui/models/Stable-diffusion/ フォルダ内に格納
最初にweb uiを起動するときに別でダウンロードしたものです。Waifu-diffusionなど。
起動後、一番左上欄の下矢印をクリックするとモデルを数秒程度で変更できる。
・VAE(.vae.pt)
/stable-diffusion-webui/models/VAE フォルダ内に格納
Settingsタブの中央列、Stable DiffusionのVAEで使用したいものを選択した後に「Apply settings」を押すことで複数のVAEを切り替えて使用できる。一つしか入れていない場合は自動で登録されているので作業は不要。
【追加学習】
・Textual inversion(.pt, .bin)
\stable-diffusion-webui\embeddings フォルダ内に格納
ファイルサイズ2桁KB~3桁程度と小さい
(DreamArtistの)trainで作成されるのもこれです。ファイル名をpromptに入力することで使用使います。(例:girl, test-10, )(前々回検証)
・Hypernetworks(.pt, .bin)
\stable-diffusion-webui\models\hypernetworksフォルダ内に格納
ファイルサイズは85,713KB~。最新のアップデート(SD v2.1)では(花札マークから)に入力することで使えます。
特定のキャラというよりは全体に影響するような絵柄の学習によく使われてるっぽい?(今回検証)
・LoRA(.ckpt, .safetensors)
/stable-diffusion-webui/models/LoRA/フォルダに格納
最新のアップデート(SD v2.1)では(花札マークから)に入力することで使えます。作成自体はweb uiは使いません。
特定のキャラの再現に向いている?(今回検証)
・Dreambooth、Imagic(.ckpt, .safetensors)
/stable-diffusion-webui/models/Stable-diffusion/フォルダに格納
Dreambooth利用時はプロンプトに学習時に指定した固有名詞と汎用名称を入れる(例:汎用名称:dog、固有名詞:hanakoで学習した場合:photo of hanako dog)
Imagicは学習時にプロンプトを入力しているので不要(なので変更困難で使いづらい)。
https://programmingforever.hatenablog.com/entry/2022/11/29/154433
ということでさっそく下記を参考に開始。わかりやすい記事ありがとうございます!
いきなり…同じキャラの画像20枚もないんですが、、、仕方ないので、今までの試行や学習中に生まれたキャラを探して揃えます。

生成中さらに漁っていると
Hypernetwork training #2284
学習に使う画像は 20 枚前後で、早ければ 3,000 ステップ、遅くても 10,000 ステップ未満で学習が終わる。
画風を学習させる場合は左右反転や回転を使うと学習画像を水増しできる。
Hypernetwork Style Training, a tiny guide #2670
量より質。画像は 20 枚前後でよい
画像サイズは 512x512 がよい
ラベルの作成に BLIP や danbooru を使う
すべてのラベルをチェックする
というメモを見つけました。左右反転とか回転ありなんですか!? 次回からはこれも活用するかもです笑 以上250枚+αから20枚を厳選した結果

比較的、髪型・画風・服装が近いキャラが集まったのではないでしょうか。途中で「HyperNetwork繰り返して固めていくのもありなんじゃないか」とも思いましたが、これはこれで一応納得のいく画像が集まったので、とりあえずこのまま進めていきます!
(結果、今回の方法でよかった気がします。10000stepほどのHyperNetworkの学習だとキャラは似るものの画風が少し離れてしまうので、まずHyperNetworkの得意なキャラ固定に集中して1,2発でキャラ決めし、それから後に紹介する方法で塗りかたを近づけるとより確実かなと感じました。もちろん未検証なので、気になった方はぜひHN繰り返しも試してみてください!)
さらに
ファインチューニングは学習データの質がすべてだ。
キャラを学習させたい場合は、背景を除去した方がいい。テキストや台詞、エフェクトもない方がいい。キャラを学習させる場合でも画風を一致させた方がいい。
よいデータを作るためには加工が必要だ。
・背景を白にしたり、テキストやエフェクトなど余計な情報を除去する
・アスペクト比が1:1になるよう画像をクロップする
・解像度が低い場合はアップスケールする
ということで背景を透明に加工します。しかもめちゃくちゃ便利なツールを発見!

背景を一瞬で消してくれる。細かいところは手描きで修正
今や「好きな絵を準備する」「出力結果から好きな絵を選ぶ」「好みで修正・補正」以外はほとんどすべて機械でできるようになりました。今後はAI同士をはしごする、AI同士をAPIでつなぐといったことも盛んになってきそうです!
というわけで

背景なしの素材が無事20枚集まりました!
あとで比較して分かったのですが、この時画像は「背景は透明ではなく白」にしておくと無難です。透明の場合、後の「前処理」で背景が黒と認識されるようになってしまう?場合があり、学習結果も暗い雰囲気になってしまいました。今回は画像処理ソフトでひたすら白とキャラを重ねて再保存していましたが、もっと楽な方法もあるかもしれません、、、笑
さっそく空のHyperNetworkファイル(.pt)を作成して

上記の画像を学習させるため、下画像のように配置して(フォルダ名は何でもいいです)



再び上記サイトを参考に設定して


ボタンを押してしばらく待てば完成! txt2img画面に花札マークがない(最近更新していない)場合は設定タブ>Stable DiffusionからHyperNetworkファイルも切り替えて「設定を適用」ボタン、一応UIを再読み込みしてtxt2imgで作成してみると…


▼ HyperNetwork適用後 ▼


うーん、かわいいしキャラ自体の統一感はすごくいい! ただ、プロンプト指定は必須ですね。仮に外すと

こんな感じで何の名残もないので、初発はうまくいかなかったという結果に。途中の設定でどこかずれたのかもしれません。ちなみに、前回DreamArtistで作成したembeddingを適用させると、HyperNetworkがオフの状態では前回のような結果になりましたが、今回は以下のようになりました。

これまでの結果をまとめると「いいHyperNetworkが作れればDreamArtist以上に同じキャラ・絵柄を再現しやすい。逆にいろいろなキャラや背景を、絵柄をそろえながらいろいろ試したいときはDreamArtist」という感じです!
その後もあれこれ試行錯誤していると、

背景を白にして、HyperNetworkの設定を



あまり関係ないかもしれませんが、途中の試し生成時に使われるプロンプトを
(masterpiece, best quality:1.2), HDR, ultra-detailed, girl, semi short hairstyle, beige shawl, blond hair, blue eyes
neg : EasyNegative, (worst quality, low quality:1.4), (monochrome:1.2),にして生成したところ

かなりキャラが固定できるようになってきました! 今回8回目で、設定していたHyperNetworkを前回生成したもののままにしていたので、結果的にHyperNetworkを積み重ねていてキャラが近づいて行ったのかもしれません。
さらに、前回DreamArtistで作成した学習モデル(塗りが安定していた)を今回(キャラが安定)に適用(プロンプトにtest10を加えるだけ)すると

キャラの安定性はやや失われましたが、塗りはぐっと近づいてきました。あともう少し。この後、まったく同じ設定で8回目の結果に9回目のHyperNetworkを重ねたところ、少しキャラは近づいた? 正直あまり分からないので、誤差かもしれません。


それでも9回目の結果に、今度はプロンプトにtest10(自分の塗りを学習させたもの)を加えた状態で10回目、さらに同様の設定で11回目を行うと




いずれにしても、自分の塗りかたの学習モデル(test10)を入れると塗りは近づくがキャラが少し変わる、という感触だったので、このモデルの髪型をもっと統一してあげればいいかもですね。そもそも学習させた絵が振り返りというややトリッキーな構図だったせいかも、、、

こっちのほうが結果の発色はいいんですよね。
ということで、HyperNetworkを使った場合「キャラは統一できる。ただし塗りは少し離れる」といった結果になりました! 現段階では、最初に学習元として大量生成&厳選された結果が一番近いです笑

続いてLoRAいきます!
2,LoRAを試してみる
記事によってやり方なども異なるのですが、最終的には以下の記事を参考にさせていただきました!
「24GBもGPU積んでるんだから大丈夫でしょ」と調子に乗ってエラー出しながらも…
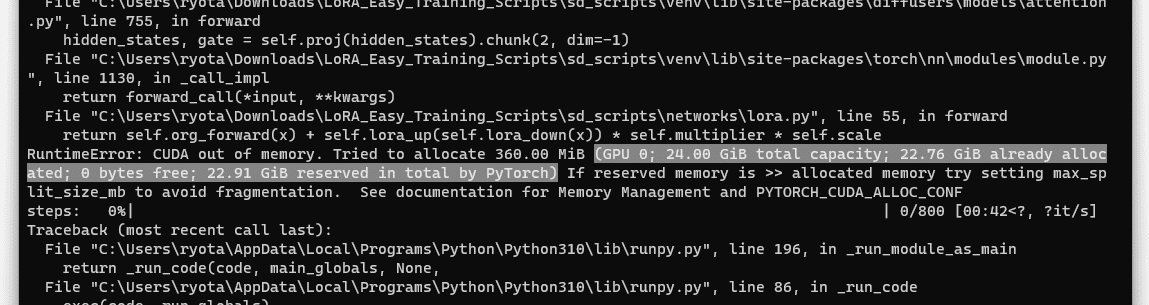


あ…明らかに過学習!! 鮮やかすぎるし、めちゃくちゃテカテカしてます。これが20epochなので、ためしに過学習が起こる前と思われる1epoch目はどうでしょうか?

学習前すぎて逆にすごいシンプル! 何回か試していて

「もしかしてHyperNetworkでは問題なかった白背景が邪魔してる?」
ということで背景除去前の20枚を改めてセット。5epoch回したところでさっきまでと同じように試してみると

一気に絵柄の再現度が高まりました! なぜか背景を紅葉に指定すると

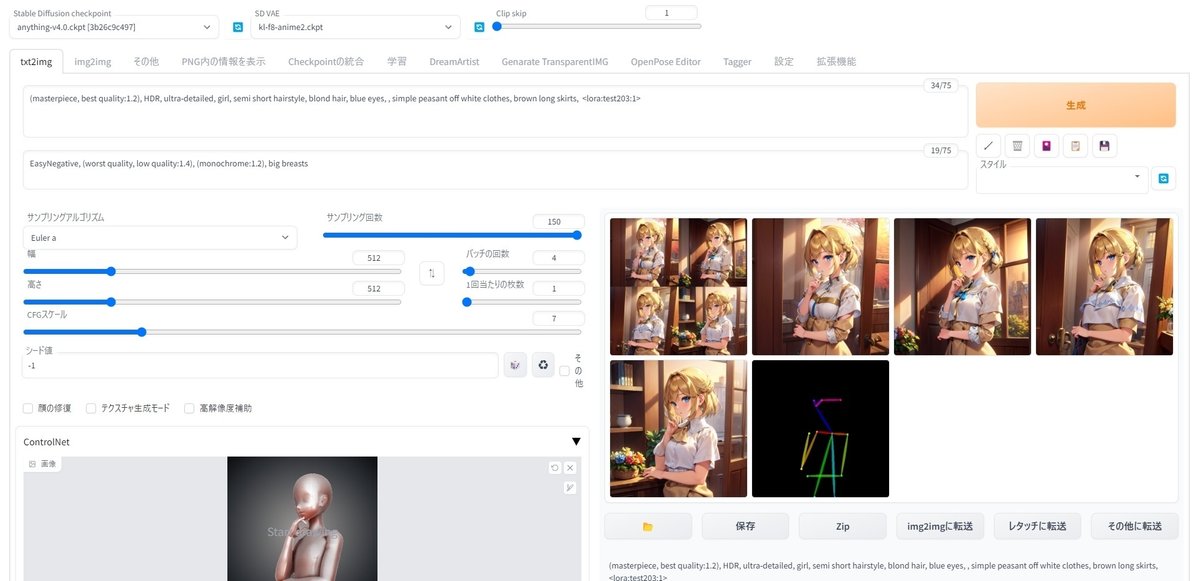
このように全く別のキャラになってしまいますが…逆に今回のモデルに使ったプロンプト(セミショートなど)を入れてあげれば

かなりの高確率で狙ったキャラを出せるように!! これこそ、まさにこの連載の最初に狙っていたことです。途中は地道な作業もありましたが、結果的には何とかまとまってくれて一安心です笑



3,より正確にポーズを抽出する
ここからはおまけです! 先日ControlNetのdepthを使い、openposeでは難しい、具体的には腕に奥行きがある構図をどう再現するか悩んでいました。例えば手前に向かってパンチをする構図などはただ腕を伸ばしただけ、そもそも全然違うポーズになる、などの問題があったのです。

ところが、先日ControlNetで「openposeとdepthを同時に使えるよ」というアップデートが入りました! もちろん、設定タブ>ControlNetから3,4つ以上に調整できます。以下のツイートで具体的に述べられていました。
ということでopenposeとdepthのどちらも適用します
— Lu:Na:Clock(AI術師) (@clock_luna) February 22, 2023
(1・2枚目のように両方のEnableにチェック入れときます)
若干の誤差はありますが打率が体感でも分かる程度には安定します(構図だけなら10枚中6-7枚いけるくらい)
また、足の本数が増えたり不要な描写も減っていると感じました pic.twitter.com/UC6T1sMMjV
ということで早速試してみた結果

見事にポーズが統一されました! かなり精度も上がってきたので光源の位置なども調整できれば、漫画などにも応用しやすくなりそうですね。ただ、多少openposeとdepthがずれると

この右下のように不思議な感じにもなります。逆に言えば、depthでエフェクトをかけたり(オブジェクトを指定する場合は色を別にしておくと自動で判断して置き換えてくれる semantic segmentation などが便利)、意図的に棒人間の周りに棒を配置することで、腕が4本など(やりませんが笑)本来はできない表現も可能になるため、モンスターや亜人などの構図を考えるときには活かせるかもしれないですね。
(残る課題)個性的なキャラを再現できるか
さて、最大の問題は解決しました、が、前回「個性的なキャラは難しい!」という話も残っています。結論から述べると、LoRAを使っても少なくとも一枚からだけだとそのキャラを作るのは難しいのでは? という感触の一方、今回のようにさらなる進展があったので、今後もしばらく試していきたいと思います。
特に「すごい!」と感じたのが、以下のLoRA。髪型も服装も非常に独創的であるにもかかわらず、それらを見事に再現しているんです。


原作は分かりませんが、何度見ても驚異の再現率です。配布サイトに記載されていたプロンプトとシード値で試してみると



ここでさらに驚きなのですが、プロンプトをあえてシンプルにすると色以外は全く別のキャラになってしまいました。つまり、プロンプトで補強すればLoRAだけでは再現が難しいキャラもいくらでも表現できる可能性が高いという、めちゃくちゃテンション上がるような事実です!!
一方、私の語彙力が少なすぎるのも事実なのです笑
キャラの個性に限ってはchatGPTも難しいし…絵を読み込ませてプロンプトを作る拡張機能ほしいな。。。(一応あるみたいですが)
いずれにせよ、「絵を描く」だけでなく「絵を作る」という表現も違和感がなくなってきましたね。マイキャラのLoRA作り、試行錯誤してみます!
おわりに
この3週間、話題になっている機能や基本的な機械学習を試してきて、それぞれ何を表現したいときに向いているか、という感覚が少しずつ掴めた気がします。もし同じところで行き詰っている、どれを使えばいいかわからない、という方がいらっしゃればぜひこの前編~後編に似たパターンがないか探してみてください!
今回、始めたときは予想もしていなかった面白さと発見が次々と出てきて、気づけば丸一日使っていた、という休日が続いていました。それ自体も充実した感覚が残るのですが、何よりAI・AIアートに対する感覚が大きく変わったように感じます。
もちろん、今までも中編の”おわりに”で述べたようにマイキャラがより身近になる、より様々な世界に冒険できるようになる、といったことは最初も期待していたのですが、実際にその世界を見ていると「じゃあこんな世界は?」「こんな機能も欲しい!もっとキャラ寄せたい!新しい技術出てこない?」「なんなら自分でAIを構築したりAPIでつないでみようか」と、AIが普段の思考の一環に、ペンと紙のような存在になってきた、この感覚が何より大きいです。
これまでもコード使えばアプリなり自動処理なり作って楽しかったのですが、そこにAIという近未来的、今やそれが現実にやって来て、新たな武器を携えた、自分自身が新しい世界に踏み出してきたという感覚です。
汎用人工知能 (一般的に人間よりも賢い AI )の在り方について、OpenAIが具体的に話してくれてる
たしかに、意外とあっという間にくるかもしれないし、少なくともその時のAIの良さ悪さって今の動向が直結するんよね、
ドラえもんとかサイコパスのクラゲももう無縁じゃないのか
https://twitter.com/churin991116/status/1629243507331469312
もちろんbingのチャットAIが乱用される、OpenAIが今後のロードマップを表明するなど考えるべきことも山積みですが、これから私たちがどんな世界を冒険していくのか、しかも受動的でなく能動的に切り開いていく、そんな時代を肌でリアルタイムで感じて生きられているのはめちゃくちゃ嬉しいな、そんなことを感じることができた時間でした。
これからもAIアートしばしば触れるかもしれないので、その時は何卒!よろしくお願いいたします!!
ではでは!