
AIとOCRを使って、手書き日報をCSVデータにしたい!

日報のデータを手動で入力するのは大変です。しかし、AIとOCR技術を組み合わせることで、効率的に日報のデータを処理し、フォーマット変換を自動化するシステムを構築することができます。この記事では、その具体的な手法について紹介します。
今回は下記のような日報を取り込み処理してみます。
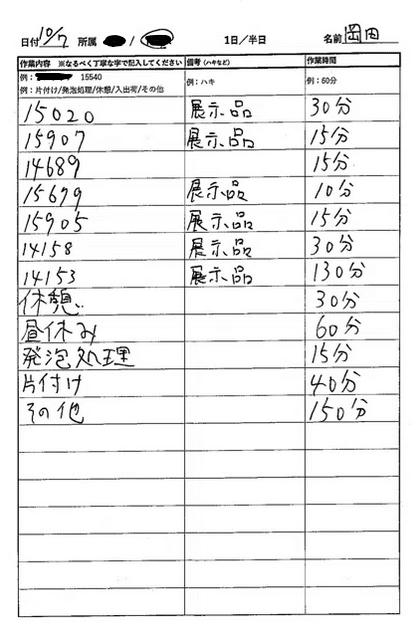
日報には作業内容、備考、作業時間の3つの項目があります。
そしてこの値を取り込んだ結果がこちら。

CSVで出力された日報データをスプレッドシートのスクリプトで転記しています。スクリプトでは転機しているだけなのでCSVと中身は全く同じです。
名前と所属、日付は日報の上記を読み取っているとして、商品企画コードはどこからきているのでしょう?
これは、OCR機能で読み取った情報を、AIに読み込ませフレキシブルに条件分岐させています。
「作業内容に5桁の数字が入っていたら、作業項目は"組立"。商品企画コードに数字を入れて」とかをプロンプトに入れておくと、AIがその指示に沿ったカテゴリ分けをしてくれるんです。
さて、ここからは、Pythonで行われている処理を順番にご説明します。
実際のコードは有料プランでご紹介しますが、chatGPTに相談したら似たようなものは出来るので、試してみても良いかもしれません。
※有料版でご紹介するコードでは
Google Cloud Vision API
OpenAI API
が必要です。どちらも別途登録と、利用料が発生しますので、それらを使える環境の方向けの記事となっています!
やっていることとしては下記。
日報をプリンタでスキャン
スキャンしたPDFを、Pythonに指定している「PDF保管場所」に保存
ここまで手動で行ったら、Pythonをスタート。
---ここからPython---
PDFをJPEGに変換。
変換するときに角度とか余白を調整
日付を取得
名前を取得
作業項目を取得
取得した情報をopenAIAPIに渡して処理。
日報CSVに保存
PDFを削除。画像をバックアップフォルダに保存
---ここまでPython---
CSVの中を見て、間違った部分や読み込めなかったところを修正。
こんな感じの流れです。
ちなみに、手動で行った場合、日報一枚3分で入力されていました。
作業者が10名居た場合。1日30分の作業です。
月20日だとすると、一月600分。10時間の作業になります。
これを自動化することによって、いまは月1時間ほどの作業になりました。
社内でDX化を目指す方の助力になれば幸いです。
1. 環境設定
まず、Pythonの環境で必要なライブラリをインストールし、APIキーを設定します。このプロジェクトでは、以下のライブラリを使用します:
pdf2image:PDFを画像に変換
google.cloud:Google Cloud Vision APIを利用して画像内のテキストを認識
OpenAI API:フォーマット変換のためにGPTモデルを利用
cv2(OpenCV)とPIL(Python Imaging Library):画像処理用
環境変数の管理にはdotenvを使用し、APIキーなどの情報を.envファイルから取得しています。
2. PDFファイルの処理
pdf2imageを使って、PDFファイルをJPEG画像に変換し、各ページを処理可能な画像フォーマットにします。この際、JPEGフォルダに保存することで、画像ファイルごとにOCR処理を行います。
3. 画像からテキストを抽出
Google Cloud Vision APIを使って、画像内のテキストを抽出します。このステップでは、画像の傾きを補正したり、エッジ検出を用いてテーブル形式のデータを識別し、各セルの情報を認識します。認識されたテキストは、後にAPIに送信するプロンプトの材料となります。
4. AIによるデータフォーマット変換
Google Cloud Vision APIで抽出したテキストデータは、そのままでは形式が不統一な場合があります。そこで、OpenAI APIを利用して、指定したフォーマットにデータを整理します。プロンプトのルールは以下の通り:
名前をカタカナから漢字に変換し、所属を特定
日付のフォーマットを統一
作業項目や商品コードを指定されたルールに基づき整理
備考や作業時間を正確に記載
5. 生成されたデータの保存
OpenAI APIから生成されたCSV形式のデータは、csvライブラリを用いてローカルファイルに保存します。保存時には、すでにファイルが存在するかどうかを確認し、ヘッダー行を追加するなど、データの整合性を保つ工夫をしています。
6. データのバックアップと管理
生成されたファイルはバックアップディレクトリに移動し、管理されています。日付ごとのフォルダを自動で作成し、ファイルの上書きなどを防止しています。
結論
このプロジェクトでは、PDFの日報データを画像に変換し、Google Cloud Vision APIを利用して手書き文字を認識、さらにOpenAI APIでデータの整形を行うことで、業務の自動化を実現しています。手書きの日報データの取り込みにおいて、AI技術を活用することで、手作業の負担を大幅に減らし、効率化を図ることができました。
日報などの手書きデータの処理に悩んでいる方は、ぜひこの手法を参考にしてみてください。
無料版では以上です。有料版では実際のコードと、使い方。
必要なAPIの概要説明も記載しています!
さらに、有料版コードにはどこの文字が読み込まれているのかがわかるViewも組み込んでいます。

赤:文字認識範囲
ここから先は
¥ 1,000
この記事が気に入ったらチップで応援してみませんか?