
データの匿名化処理についてーデータを適切に扱うためにー

分析屋の大谷津と申します。
よろしくお願いいたします。
データを扱う業務をしている上で、気をつける点の一つとしてあるのが個人情報の扱い方だと思います。
データを活用したビジネスが社会的になりつつある昨今において、個人を特定できる情報をどのようにして扱うべきかを、データに関わる業務をしている皆さんも一度くらいは考えたことがあるかもしれません。
そこで今回は、「データの匿名化処理」というテーマで、その考え方や手法などについて書かせていただきます。データの匿名化処理について、Pythonを用いて行う方法も解説しておりますので、ぜひ参考にしていただけばと思っております。
技術ブログは初めての執筆になりますので、至らない点等あるかと思いますが、その際はぜひともご意見等いただければ幸いです。
データの匿名化処理とは
データの匿名化(マスキング)処理とは、データを扱う業務を行う中で、不正アクセスや個人情報の流出リスクに備えて、データの保護や匿名加工の技術をデータに対して、適用させること(あるいはそのプロセス)をいいます。*1
データ匿名化処理のイメージとしては、以下のようになります。

実際は特定のアルゴリズムにもとづいて、匿名化加工を行うことが一般的ではありますが、上記では「契約者名」を特定のIDあるいは文字列に変更することで個人名を抽象化させています。
個人を特定できるデータを抽象化することで、情報の解像度を落としてセキュリティを担保できるため、個人情報を含むデータを活用する上で重要な役割を果たします。データの匿名化加工やその考え方を身につけることは、非常に意味のあることだと、私個人的にではありますが考えております。
データの匿名化がなぜ必要か
個人情報は、特定の個人情報を識別できる情報になります。個人情報を含むデータは、適切に保護されないまま利用するとプライバシーの侵害を引き起こす可能性があります。
特に、個人識別情報(PII: Personally Identifiable Information)*2や機密情報を取り扱う際に、個人の同意なしに情報を漏洩させてしまうリスクが発生します。こうした個人情報に関するデータをそのまま扱うのは、危険であることは理解できると思います。データの匿名化は、このようなリスクを回避するための有効な手段となります。
また、データを外部や社内セキュリティの範囲外への持ち出しで、データに含まれる個人情報を漏洩させてしまい、悪用されてしまう可能性が考えられます。データの持ち出しあるいは、外部の利害関係者に対して、個人情報を匿名化させて匿名加工情報として、データや分析内容を共有することで、個人情報の漏洩を防ぐことにもつながります。
他にも、医学研究やマーケティングリサーチなどの学術研究においても、個人情報を匿名化してデータを提供することも考えられます。そのため、データの匿名化を行うことで、研究や分析用途で幅広く共有することが可能になります。
データの利用者は個人情報をそのまま扱わずにコンプライアンス違反を避けながら、分析を行うといった観点においてもデータの匿名化を行うことは非常に意味があります。
匿名化の考え方と匿名化処理させるべき項目について
匿名化処理させるべき項目としては、主に個人を特定できる情報を持つデータの項目が一般的とされています。
また、「個人情報に関する法律」では、匿名化すべき個人情報の定義として下記のように定義されています。
一 当該情報に含まれる氏名、生年月日その他の記述等(文書、図画若しくは電磁的記録(電磁的方式(電子的方式、磁気的方式その他人の知覚によっては認識することができない方式をいう。次項第二号において同じ。)で作られる記録をいう。以下同じ。)に記載され、若しくは記録され、又は音声、動作その他の方法を用いて表された一切の事項(個人識別符号を除く。)をいう。以下同じ。)により特定の個人を識別することができるもの(他の情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む。)
二 個人識別符号が含まれるもの
上記の定義から以下のようなデータや情報に関して匿名化すべきであると考えられます。
1の氏名、生年月日、その他の記述等では、住所、電話番号、勤務先、メールアドレス、顔写真などが該当します。
2の個人識別符号が含まれるものでは、契約者ID、カスタマーIDなどの顧客番号(一意で個人の特定が可能なIDである場合)、顔認識データ、マイナンバー、運転免許証番号など、個人を識別できる識別子が匿名化の対象となります。
どのデータ(項目)をどの程度抽象化するべきかといった考え方などは当然、企業や案件・プロジェクトなどによって異なります。一般的な対応としては、個人情報の項目を利用せずにデータから取り除く(あるいは空白にする)ことやIDを特定のアルゴリズムにしたがって、匿名化加工(マスキング)を行うことが考えられます。
データの活用とセキュリティはトレードオフ*4となるのが一般的であるため、データの活用シーンに応じて、情報をどの程度抽象化させるかを案件、プロジェクトの中で議論するあるいはルール、制約に従い決めておく必要があります。
例えば、以下のようにAからCのように情報を抽象化させるケースを考えてみましょう。
A. 神奈川県藤沢市藤沢484−1 藤沢アンバービル4F
B. 神奈川県藤沢市
C. 神奈川県

特定のあるサービス利用者で市町村単位(都道府県単位)の粒度情報(BまたはC)をデータとして、予測や分析に利用するだけ充足するケースもあれば、正確な位置情報(A)がデータとして必要となるケースもあります。場合によっては、Aの情報を活用したいが、セキュリティなどの制約があるため、BやCの形でしか利用できない、あるいは住所情報を利用できないことも考えられます。このようなことが、「データの活用とセキュリティにおけるトレードオフ」となることを示しています。
したがって、その企業や案件が扱う個人情報を活用シーンに応じて、どの程度抽象化させて活用するべきかといった視点は、データを活用する業務において非常に重要です。*5
主な匿名化処理手法
一般的なデータの匿名化技術として、暗号化とハッシュ化があります。
暗号化は、データを復号すること、つまり匿名化したデータをもとの情報に戻すことが可能な処理であり、主にデータの機密性を保護するために行われます。

ハッシュ化は、データを復号することが不可能な処理であり、匿名化を行うと匿名化の情報から匿名化前のもとの情報に戻すことができなくなるため、主にデータの完全性を確保するために行われます。

暗号化とハッシュ化は、それぞれ匿名加工の方法、アルゴリズムが異なります。ざっくりではありますが、匿名加工をしたデータを元に戻す必要がない場合は、ハッシュ化技術を利用する、匿名加工をしたデータをもとの匿名加工前の状態に戻す必要がある場合は、暗号化技術を利用すると理解しておきましょう。*6
Pythonでデータの匿名化処理を行う
Pythonで提供されているモジュールで「hashlib」*7というモジュールがあり、「SHA-256」という技術を用いてデータを匿名化する目的で使用されます。今回はこちらのモジュールを利用して、Pythonで匿名化(ハッシュ化)を行う方法について説明します。
まず以下のような、架空のなんらかの会員情報、例えばですがフィットネスクラブの会員情報があり、匿名加工情報を用いた分析を行うケースを想定していただければと思います。
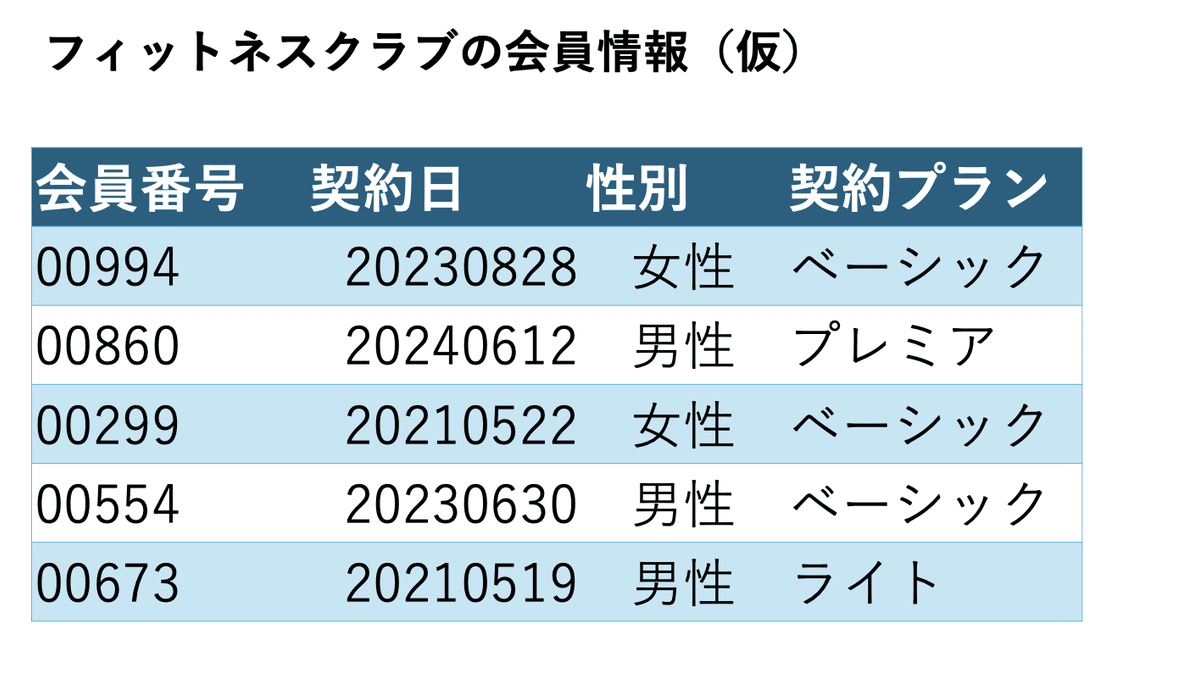
「在宅環境で社内のデータを扱う際は個人情報を匿名加工(マスキング)することが必要」といった制約があり、項目としてある「会員番号」を匿名化情報に加工したデータにすることが今回のシナリオになります。イメージとしては以下のようになります。

詳しいコードに関しては、サンプルのノートブックを準備しておりますので、ぜひご確認いただければと思います。
Google Colab「hashed_with_python.ipynb」
https://drive.google.com/file/d/1oZIqENnjOK2gjH_mbhqvvVM2BXi07DLK/view?usp=sharing
手順としては、ざっくり以下のようになります。
「hashlib」モジュールをインポートする
SHA-256技術でハッシュ化させるメソッドを呼び出す
ハッシュ化(匿名化)させたい項目(文字列)をバイトに変換
ハッシュ値を16進数形式で取得
それでは、やっていきましょう。
1. 「hashlib」モジュールをインポートする
まずは、以下のコードで「hashlib」モジュールをインポートします。
import hashlib2. SHA-256技術でハッシュ化させるメソッドを呼び出す
その前にデータを確認しましょう。データは以下のようになっています。

「hashlib.sha256()」という形で、SHA-256という技術でハッシュ化させる「.sha256()」メソッドを呼び出します。
hasher = hashlib.sha256()3. ハッシュ化(匿名化)させたい項目(文字列)をバイトに変換
ハッシュを計算するデータはバイト形式で追加する必要があるため、ハッシュ化させるデータの項目(文字型)を「encode()」メソッドを使用して文字列をバイトに変換して、データをハッシュオブジェクトに追加します。
※下記のコードでは任意の文字列(単一レコードのあるカラムの値を想定)を「encode()」メソッドに渡している形になります。
member_id = '00994'
hasher.update(member_id.encode())4. ハッシュ値を16進数形式で取得
「hasher.hexdigest()」メソッドで、追加したデータ項目をハッシュ値で取得します。匿名化したデータは通常16進数形式の文字列として出力されます。
hasher.hexdigest()②から④の処理を関数としてまとめると以下のようになります。
def hash_col(col):
"""
指定したカラムに対して、SHA-256を用いてハッシュ化する。
Args:
col(str): ハッシュ化する会員番号(文字列形式)。
Returns:
str: 会員番号のハッシュ値(64文字の16進数文字列)。
"""
hasher = hashlib.sha256() # SHA-256ハッシュオブジェクトを作成
hasher.update(col.encode()) # バイト形式にエンコードした項目を追加
return hasher.hexdigest() # ハッシュ値を16進数形式の文字列として取得参考として、複数のカラムをハッシュ化させたい場合は以下のように関数を改良させます。(もっと簡素な書き方があるかと思いますが、あくまで一例としてみていただければ。。。)
# 複数のカラムをハッシュ化させる場合
def hash_columns(df, columns):
"""
DataFrame内の指定されたカラムに対して、SHA-256を用いてハッシュ化。
カラムは単一の文字列または文字列のリストとして指定可能。
Args:
df (pandas.DataFrame): データフレーム。
columns (str or list): ハッシュ化するカラム名、またはカラム名のリスト。
Returns:
pandas.DataFrame: カラムがハッシュ化されたデータフレーム。
"""
if isinstance(columns, str):
# カラム名が単一の文字列であればリストに変換
columns = [columns]
def hash_member_id(value):
hasher = hashlib.sha256()
hasher.update(str(value).encode())
return hasher.hexdigest()
for col in columns:
# 各カラムに対してハッシュ化を適用
df[col] = df[col].apply(hash_member_id)
return df# 単一のカラム名を文字列として渡す場合
# df = hash_columns(df, '会員番号')
# 複数のカラム名をリストとして渡す場合(例:会員番号と契約日)
# df = hash_columns(df, ['会員番号', '契約日'])
「hash_col」関数を「会員番号」に当てて、ハッシュ化させます。
df['会員番号'] = df['会員番号'].apply(hash_col)「会員番号」を確認すると以下のようにハッシュ化された値になります。

これで「会員番号」がハッシュ化されて匿名加工情報になりました。
ハッシュ化された「会員番号」の各要素の文字数が64文字になっています。
注意点としては、先ほども触れたように一度ハッシュ化を行った場合、ハッシュ化した文字列をもとの「ハッシュ化する前の値に戻すことができない」ため、ハッシュ化する前のデータも保持しておくなどの対応が必要となります。
まとめ
今回は、データの匿名化処理についてブログを執筆させていただきました。
匿名化処理のことだけではなく、Pythonを用いて匿名化処理ができること理解していただけたのではないでしょうか。
匿名化処理は活用するデータを適切に保護するので分析を行う上で欠かせない技術であり、私も普段の業務からデータの扱いについて注意しながら、分析を行うように心がけたいと思っております。
今回の記事が少しでも参考になれば幸いです。
注釈・参考文献
*1 AWS 「データマスキングとは何ですか?」
*2 国民のためのサイバーセキュリティサイト
http://soumu.go.jp/main_sosiki/cybersecurity/kokumin/security/end_user/general/07/
*3 e-Govポータル 個人情報の保護に関する法律
*4 山口 利恵(2015)「ビッグデータの利活用とプライバシー保護の難しさ」『映像情報メディア学会誌69(2)』
*4 伊藤徹郎、渡部徹太郎、ゆずたそ(2021)「実践的データ基盤への処方箋」『技術評論社』
*5 個人情報の保護に関する法律についてのガイドライン(仮名加工情報・匿名加工情報編)
https://www.ppc.go.jp/files/pdf/241202_guidelines04.pdf
*6 キヤノンマーケティングジャパングループ「ハッシュ化と暗号化の違いとは?」『サイバーセキュリティ情報局』
*6 EAGLYS「暗号化とハッシュ化の違いとは。仕組みや活用例から読み解く」
*6 GMOサインブログ 「暗号化の基礎知識|仕組みとアルゴリズムの種類、メリット・注意点」
*6 安田幹・佐々木悠(2010)「暗号学的ハッシュ関数」『電子情報通信学会 基礎・境界ソサイエティ Fundamentals Review 4(1)』pp.57-67
*6 Python公式ドキュメント「hashlib --- セキュアハッシュとメッセージダイジェスト」
*7 メッセージダイジェスト関数とハッシュ関数とは?暗号技術の基本概念をわかりやすく解説
・サンプルコード Google Colab
https://drive.google.com/file/d/1oZIqENnjOK2gjH_mbhqvvVM2BXi07DLK/view?usp=sharing
ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。