
オープンテーブルフォーマットのIceberg試してみた

分析屋の下滝です。
snowflakeを調べる流れでIcebergのことを聞くことが増えてきました。
snowflakeがIcebergに対応するということで、以下の記事を読んだのですが、詳細がよく分からなかったので、Iceberg自体を試してみます。
Iceberg
Apache Icebergは、巨大な分析データセットのためのオープンなテーブルフォーマットである。IcebergはSpark、Trino、PrestoDB、Flink、Hive、Impalaなどの計算エンジンに、SQLテーブルと同じように動作する高性能なテーブルフォーマットを使ってテーブルを追加します。
オープンなテーブルフォーマットという概念があまりピンと来ないのですが、Icebergの仕様書では次のように説明があります。
これはIcebergテーブル・フォーマットの仕様であり、分散ファイル・システムやKey-Valueストアにおいて、大規模で変化の遅いファイルの集合をテーブルとして管理するために設計されている。

このテーブル・フォーマットは、ディレクトリの代わりにテーブル内の個々のデータ・ファイルを追跡する。これにより、ライターはデータファイルをその場で作成し、明示的なコミットでのみファイルをテーブルに追加することができる。
図で見ると、カタログが最上位にあり、
その下がメタデータレイヤーであり
メタデータレイヤーには、
メタデータファイルがあり
メタデータファイルは、スナップショットをもち
スナップショットは、マニフェストリストをもち
マニフェストリストはマニフェストファイルをもち
マニフェストリストファイルは、
データレイヤーの
データファイルをもつ
よくわかりませんが、詳しい仕様は、仕様書を読むのがよさそうです。
テーブルの状態はメタデータ・ファイルで管理される。テーブルの状態を変更すると、新しいメタデータ・ファイルが作成され、古いメタデータはアトミック・スワップで置き換えられます。テーブル・メタデータ・ファイルは、テーブル・スキーマ、パーティショニング設定、カスタム・プロパティ、テーブル・コンテンツのスナップショットを追跡します。スナップショットは、ある時点におけるテーブルの状態を表し、テーブル内のデータ・ファイル一式にアクセスするために使用されます。
スナップショット内のデータ ファイルは、テーブル内の各データ ファイルの行、ファイルのパーティション データ、およびそのメトリックを含む 1 つ以上のマニフェスト ファイルによって追跡されます。スナップショット内のデータは、そのマニフェスト内のすべてのファイルの結合です。マニフェスト・ファイルは、変化の遅いメタデータの書き換えを避けるため、スナップショット間で再利用されます。マニフェストは、テーブルの任意のサブセットを持つデータ・ファイルを追跡することができ、パーティションとは関連付けられません。
スナップショットを構成するマニフェストは、マニフェスト・リスト・ファイルに格納されます。各マニフェスト・リストには、パーティション統計およびデータ・ファイル・カウントを含む、マニフェストに関するメタデータが格納されます。これらの統計は、操作に必要のないマニフェストの読み取りを回避するために使用されます。
今回は仕様書を詳しく見ていくというよりも実際に動かしてみます。
Sparkの例を動かしなからみていきます。
Sparkのインストールなどの準備はこのページを参考にしました。
今回はPySparkを使うわけではありません。
試してみる
まずはカタログを作ります。次のようにすることでlocalというカタログが作られるそうです。
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.4_2.12:1.3.1
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog
--conf spark.sql.catalog.spark_catalog.type=hive
--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog
--conf spark.sql.catalog.local.type=hadoop
--conf spark.sql.catalog.local.warehouse=warehouse3.4_2.12:1.3.1のバージョンは、インストールしたバージョンに合わせてください。
warehouseは、作成するテーブルに関するファイルの置き場所となります。
このコマンドを実行すると、以下のディレクトリとファイルが作成されます。
・metastore_db ディレクトリ
・derby.log ファイル
metastore_db の中のファイルとフォルダはほとんどバイナリなのでよくわかりません。どこかにlocalカタログに関するデータが書き込まれているのかもしれません。
上記のコマンド実行後、SQLを実行できるようなりましたので、テーブルを作ってみます。ここではmytableというテーブルを作りました。
CREATE TABLE local.db.mytable (id bigint, data string) USING iceberg次のようなディレクトリとファイルが作成されます。
warehouse
└ db
└ mytable
└ metadata
└ v1.metadata.json
└ .v1.metadata.json.crc
└ version-hint.text
└ .version-hint.text.crc
.crcはファイルの整合性を確認するための値が保持されたファイル形式です。ということで中身が気になるのはこの2つです。
・version-hint.text
・v1.metadata.json
version-hint.textの中身は
1でした。
v1.metadata.jsonの中身はこのようになっていました。これがメタデータファイルに対応するようです。
{
"format-version" : 1,
"table-uuid" : "19f3de3e-cfd4-44d1-82ba-73bf020e5f91",
"location" : "warehouse/db/mytable",
"last-updated-ms" : 1694017142009,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "yourname"
},
"current-snapshot-id" : -1,
"refs" : { },
"snapshots" : [ ],
"statistics" : [ ],
"snapshot-log" : [ ],
"metadata-log" : [ ]
}
続いてレコードを一行追加してみます。
INSERT INTO local.db.mytable VALUES (1, 'a')次のようなディレクトリ構造になりました。crcファイルは除いてます。
warehouse
└ db
└ mytable
└ metadata
└ v1.metadata.json
└ v2.metadata.json
└ version-hint.text
└ 4bf6f5ba-437f-4406-98fd-ac9516f9eb19-m0.avro
└ snap-8113230320273666344-1-4bf6f5ba-437f-4406-98fd-ac9516f9eb19.avro
└ data
└ 00000-0-17bf8e95-4028-406e-8713-f029ed5180d0-00001.parquet
dataディレクトリが新たに作られました。parquetファイルが作られています。parquetは、列指向データファイル形式です。
metadataのファイルがv2のものが作られています。
また、avroファイルが2つ作られています。Avroは、データシリアライゼーションのシステム、とのことです。
各ファイルを見ていきます。
version-hint.textの中は1から2になりました。
v2.metadata.jsonはこのようになっていました。
{
"format-version" : 1,
"table-uuid" : "19f3de3e-cfd4-44d1-82ba-73bf020e5f91",
"location" : "warehouse/db/mytable",
"last-updated-ms" : 1694017825235,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "yourname"
},
"current-snapshot-id" : 811323032027366344,
"refs" : {
"main" : {
"snapshot-id" : 8113230320273666344,
"type" : "branch"
}
},
"snapshots" : [ {
"snapshot-id" : 8113230320273666344,
"timestamp-ms" : 1694017825235,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1694015990420",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "643",
"changed-partition-count" : "1",
"total-records" : "1",
"total-files-size" : "643",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "warehouse/db/mytable/metadata/snap-8113230320273666344-1-4bf6f5ba-437f-4406-98fd-ac9516f9eb19.avro",
"schema-id" : 0
} ],
"statistics" : [ ],
"snapshot-log" : [ {
"timestamp-ms" : 1694017825235,
"snapshot-id" : 8113230320273666344
} ],
"metadata-log" : [ {
"timestamp-ms" : 1694017142009,
"metadata-file" : "warehouse/db/mytable/metadata/v1.metadata.json"
} ]
}
v1との違いは、snapshots というスナップショットに関わる項目が増えている点かもしれません。
"manifest-list" : "warehouse/db/mytable/metadata/snap-8113230320273666344-1-4bf6f5ba-437f-4406-98fd-ac9516f9eb19.avro",
とあるので、snap-~~~avroファイルがマニフェストリストファイルのようです。

avroファイルはバイナリなので、中身は直接はエディタで確認しにくいです。ビューアーで表示しました。
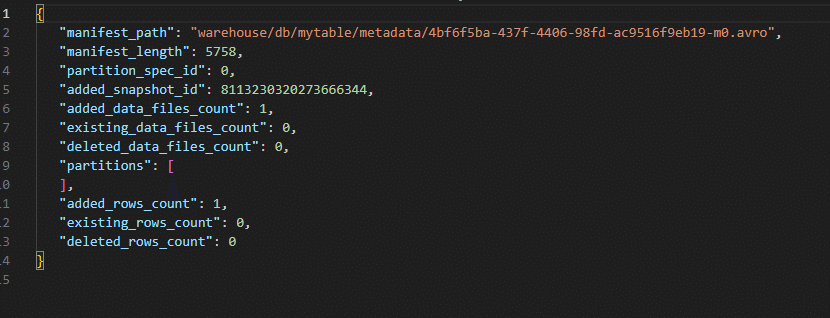
manifest_pathがwarehouse/db/mytable/metadata/4bf6f5ba-437f-4406-98fd-ac9516f9eb19-m0.avroとなっていますので、このファイルがマニフェストのようです。

4bf6f5ba-437f-4406-98fd-ac9516f9eb19-m0.avro
の中身はこうです。

data_fileフィールドのfile_pathが
warehouse/db/mytable/data/00000-0-17bf8e95-4028-406e-8713-f029ed5180d0-00001.parquet
となっています。これがデータファイルです。
このデータファイルはバイナリですが、ビューアーでみるとこうでした。
{"id":1,"data":"a"}
インサートしたデータが格納されています。

ここまでは、生成されたファイルをみてきましたが、これらファイルの情報に関しては、テーブル情報を確認するためのクエリが用意されています。
まずは、スナップショットです。
SELECT * FROM local.db.mytable.snapshots;カラム名 値
committed_at 2023-09-07 01:30:25.235
snapshot_id 8113230320273666344
parent_id NULL
operation append
manifest_list warehouse/db/mytable/metadata/snap-8113230320273666344-1-4bf6f5ba-437f-4406-98fd-ac9516f9eb19.avro
summary {"added-data-files":"1","added-files-size":"643","added-records":"1","changed-partition-count":"1","spark.app.id":"local-1694015990420","total-data-files":"1","total-delete-files":"0","total-equality-deletes":"0","total-files-size":"643","total-position-deletes":"0","total-records":"1"}
続いてマニフェストです。
SELECT * FROM local.db.mytable.manifests;content 0
path warehouse/db/mytable/metadata/4bf6f5ba-437f-4406-98fd-ac9516f9eb19-m0.avro
length 5758
partition_spec_id 0
added_snapshot_id 8113230320273666344
added_data_files_count 1
existing_data_files_count 0
deleted_data_files_count 0
added_delete_files_count 0
existing_delete_files_count 0
deleted_delete_files_count 0
partition_summaries []
おそらく、4bf6f5ba-437f-4406-98fd-ac9516f9eb19-m0.avro がマニフェストファイルです。
続いてデータファイルです。
SELECT * FROM local.db.mytable.files;content 0
file_path warehouse/db/mytable/data/00000-0-17bf8e95-4028-406e-8713-f029ed5180d0-00001.parquet
file_format PARQUET
spec_id 0
record_count 1
file_size_in_bytes 643
column_sizes {1:46,2:48}
value_counts {1:1,2:1}
null_value_counts {1:0,2:0}
nan_value_counts {}
lower_bounds {1: ,2:a}
upper_bounds {1: ,2:a}
key_metadata NULL
split_offsets [4]
equality_ids NULL
sort_order_id 0
readable_metrics {"data":{"column_size":48,"value_count":1,"null_value_count":0,"nan_value_count":null,"lower_bound":"a","upper_bound":"a"},"id":{"column_size":46,"value_count":1,"null_value_count":0,"nan_value_count":null,"lower_bound":1,"upper_bound":1}}
続いてデータをさらにインサートしてみます。
INSERT INTO local.db.mytable VALUES (2, 'b');次のようなディレクトリとファイル構造になりました。
warehouse
└ db
└ mytable
└ metadata
└ v1.metadata.json
└ v2.metadata.json
└ v3.metadata.json
└ version-hint.text
└ 4bf6f5ba-437f-4406-98fd-ac9516f9eb19-m0.avro
└ 1647c729-6f6f-4fd9-ba1a-7365a0a262ee-m0.avro
└ snap-8113230320273666344-1-4bf6f5ba-437f-4406-98fd-ac9516f9eb19.avro
└ snap-7006543812640496337-1-1647c729-6f6f-4fd9-ba1a-7365a0a262ee.avro
└ data
└ 00000-0-17bf8e95-4028-406e-8713-f029ed5180d0-00001.parquet
└ 00000-4-191c31f5-1a63-483e-b5ad-0af9c2b2322d-00001.parquet
メタデータファイル、マニフェストリストファイル、マニフェストファイル、データファイルが生成されました。
version-hint.textの中は2から3になりました。
v3.metadata.jsonはこうです。
{
"format-version" : 1,
"table-uuid" : "19f3de3e-cfd4-44d1-82ba-73bf020e5f91",
"location" : "warehouse/db/mytable",
"last-updated-ms" : 1694101567259,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "asato"
},
"current-snapshot-id" : 7006543812640496337,
"refs" : {
"main" : {
"snapshot-id" : 7006543812640496337,
"type" : "branch"
}
},
"snapshots" : [ {
"snapshot-id" : 8113230320273666344,
"timestamp-ms" : 1694017825235,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1694015990420",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "643",
"changed-partition-count" : "1",
"total-records" : "1",
"total-files-size" : "643",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "warehouse/db/mytable/metadata/snap-8113230320273666344-1-4bf6f5ba-437f-4406-98fd-ac9516f9eb19.avro",
"schema-id" : 0
}, {
"snapshot-id" : 7006543812640496337,
"parent-snapshot-id" : 8113230320273666344,
"timestamp-ms" : 1694101567259,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1694020484362",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "643",
"changed-partition-count" : "1",
"total-records" : "2",
"total-files-size" : "1286",
"total-data-files" : "2",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "warehouse/db/mytable/metadata/snap-7006543812640496337-1-1647c729-6f6f-4fd9-ba1a-7365a0a262ee.avro",
"schema-id" : 0
} ],
"statistics" : [ ],
"snapshot-log" : [ {
"timestamp-ms" : 1694017825235,
"snapshot-id" : 8113230320273666344
}, {
"timestamp-ms" : 1694101567259,
"snapshot-id" : 7006543812640496337
} ],
"metadata-log" : [ {
"timestamp-ms" : 1694017142009,
"metadata-file" : "warehouse/db/mytable/metadata/v1.metadata.json"
}, {
"timestamp-ms" : 1694017825235,
"metadata-file" : "warehouse/db/mytable/metadata/v2.metadata.json"
} ]
}スナップショットが2つになりました。
2つ目のスナップショットでは、
"manifest-list" : "warehouse/db/mytable/metadata/snap-7006543812640496337-1-1647c729-6f6f-4fd9-ba1a-7365a0a262ee.avro"
が指定されています。
このマニフェストリストファイルの中身はこうです。

2つのマニフェストファイルが参照されています。
新たに追加されたマニフェストは
warehouse/db/mytable/metadata/1647c729-6f6f-4fd9-ba1a-7365a0a262ee-m0.avro
です。

データファイルとして
warehouse/db/mytable/data/00000-4-191c31f5-1a63-483e-b5ad-0af9c2b2322d-00001.parquet
が参照されています。
このデータファイルの中身は以下となります。インサートしたデータに対応します。
{"id":2,"data":"b"}
今回は以上です。
株式会社分析屋について
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。