
GoogleのCloud Pub/SubでDataflowとBigQueryと連携してみた

分析屋の下滝です。
前回は、Pub/SubとCloud Storageの連携をさらっと触ってみました。
今回は、Pub/Subに送信したメッセージを、Dataflowを通じて、BigQueryに格納する方法を試してみます。
Pub/Sub から Dataflowを使ってのBigQuery へのストリーミング
Pub/Sub には3つのタイプのサブスクリプションがあります。
・pull
・push
・エクスポートサブスクリプション
・BigQuery サブスクリプション
・Cloud Storage サブスクリプション
前回は、Cloud Storage サブスクリプションを試しました。今回は、DataflowをPub/SubとBigQueryの間に置く構成を試してみます。この構成は、BigQueryに格納する前に何らかのデータ変換処理を行いたい場合に使います。
試しとしては、まずは、何も変換処理を行わずに試します。次に簡単な変換処理を行います。
Dataflowは次のようなサービスです。
Dataflow は、統合されたストリーム データ処理とバッチデータ処理を大規模に提供する Google Cloud サービスです。Dataflow を使用して、1 つ以上のソースからデータを読み取り、変換し、宛先に書き込むデータパイプラインを作成します。
今回ベースにする公式記事は以下のものです。
Dataflowには、テンプレートという概念があります。今回は、「Pub/Sub Topic to BigQuery」というテンプレートを使います。基本的には、テンプレートに沿った内容で項目を設定していきます。
では設定していきます。Dataflowの名前に必要な準備です
使うトピックは、前回の記事と同じものを使います。test-topicという名前です。

BigQueryにもデータセットとテーブルを作成しておいてください。

「pub_sub_test」というデータセットと
「pub_sub_test_table」というテーブル
を作成しています。
また、pub/subに送るメッセージとして、idとnameのフィールドがあるメッセージを送るので、対応するフィールドをBigQuery側にも作成しておいてください。dataフィールドは不要です。
Cloud Storageのバケットも使います。「pub_sub_topic_test」というバケットを作成しています。
続いてdataflowの定義です。「テンプレートからジョブを作成」を選んでください。
テンプレートには「Pub/Sub Topic to BigQuery」を選んでください。

必須パラメータには
・入力となるトピック
・出力となるBigQueryのテーブル
・一時的な場所となるCloud Storageのファイル
を指定してください。
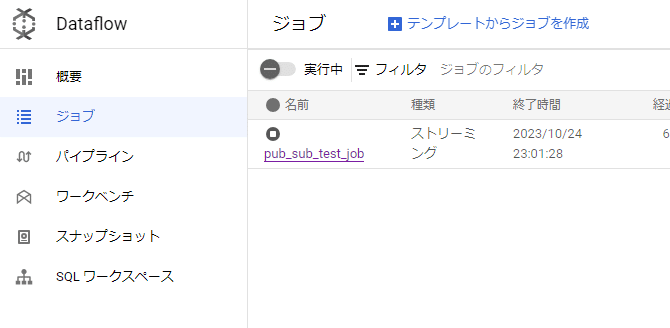
下の方にある「ジョブを実行」を押すと、ジョブが作成されます。ちなみに、作成したジョブは削除できないようです(停止はできます)。
次のようなフローからなるジョブが実行中となりました。

また、どのタイミングで作成されたのかわかりませんが、test-topicにサブスクリプションが自動作成されています。

配信タイプがpullのサブスクリプションのようです。

続いて、トピックへのメッセージの送信を行います。これまでの記事と同じです。project_idは、適切なものを設定してください。
"""Publishes multiple messages to a Pub/Sub topic with an error handler."""
from concurrent import futures
from google.cloud import pubsub_v1
from typing import Callable
import json
# TODO(developer)
project_id = "gcp-test-1697637841257"
topic_id = "test-topic"
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_id)
publish_futures = []
def get_callback(
publish_future: pubsub_v1.publisher.futures.Future, data: str
) -> Callable[[pubsub_v1.publisher.futures.Future], None]:
def callback(publish_future: pubsub_v1.publisher.futures.Future) -> None:
try:
# Wait 60 seconds for the publish call to succeed.
print(publish_future.result(timeout=60))
except futures.TimeoutError:
print(f"Publishing {data} timed out.")
return callback
data_list = [{"id" : 1, "name" : "あああ"}, {"id" : 2, "name" : "いいい"}]
for data in data_list:
# When you publish a message, the client returns a future.
publish_future = publisher.publish(topic_path, json.dumps(data).encode("utf-8"))
# Non-blocking. Publish failures are handled in the callback function.
publish_future.add_done_callback(get_callback(publish_future, data))
publish_futures.append(publish_future)
# Wait for all the publish futures to resolve before exiting.
futures.wait(publish_futures, return_when=futures.ALL_COMPLETED)
print(f"Published messages with error handler to {topic_path}.")json形式でメッセージを2通送信します。以下2つのメッセージを送ります。
[{"id" : 1, "name" : "あああ"}, {"id" : 2, "name" : "いいい"}]
実行結果は以下となります。
>python pub_sub.py
8903378788073495
8903378788073496
Published messages with error handler to projects/gcp-test-1697637841257/topics/test-topic.送信したメッセージがBigQueryに格納されているか確認してみます。

送信した内容のメッセージで格納されています。
データ変換処理
続いて、データ変換処理を試します。
JavaScript でユーザー定義関数(UDF)を定義して、データ変換処理が行なえます。Pub/Sub Topic to BigQuery テンプレートのオプションとしてUDFを指定できます。
以下の内容で、Cloud Storageに格納します。ファイル名は、transform.jsとしました。nameの値を2つつなげるだけの変換処理です。
function process(inJson) {
const obj = JSON.parse(inJson);
obj.name = obj.name + obj.name
return JSON.stringify(obj);
}たとえば、
「あああ」は「ああああああ」に
「いいい」は「いいいいいい」に
しようとしています。
ジョブは編集できないようなので、新たなジョブを作ります。

先程と同じですが、新たにオプションパラメータに「jsファイルの場所」と「関数名」を入れます。
gs://pub_sub_topic_test/transform.js
process
先程と同じ用にメッセージを送信します。
BigQueryの中身を確認します。
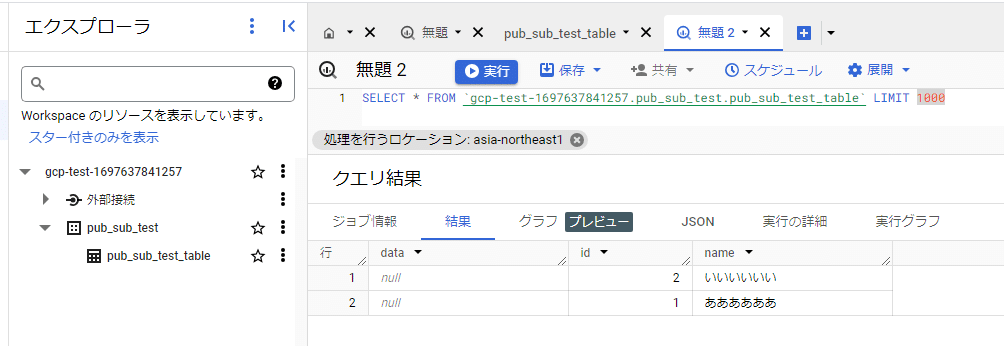
想定通りの内容で格納されたことが分かります。
「あああ」は「ああああああ」に
「いいい」は「いいいいいい」に
なっています。
今回は以上です。
株式会社分析屋について
ホームページはこちら。
noteでの会社紹介記事はこちら。
専用の採用ページはこちら。


【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。