
Snowflakeさわってみた。Snowparkのpython試してみた。

分析屋の下滝です。
Snowflakeさわってみよう、の5回目です。
あまりよくわかってないのですが、Snowpark Pythonという機能を試してみました。APIという位置づけです。
Snowparkライブラリは、データパイプライン内のデータをクエリおよび処理するための直感的な API を提供します。このライブラリを使用すると、アプリケーションコードが実行されるシステムにデータを移動することなく、Snowflakeでデータを処理するアプリケーションを構築できます。Snowparkには、他のクライアントライブラリとの差別化をもたらすいくつかの機能があります。
Snowflakeコネクタとの違いもあまり分からないのですが、とりあえず使ってみます。詳しい特徴は公式ドキュメントを参照してください。
公式ドキュメント通りにまずはインストールしていきます。どうやらpython3.8の環境が必要のようです。
公式ドキュメントの例と同様に、condaで環境を作成します。
conda create --name py38_env --override-channels -c https://repo.anaconda.com/pkgs/snowflake python=3.8 numpy pandas作成した環境に切り替えます。
conda activate py38_envsnowparkをインストールします。
pip install snowflake-snowpark-pythonsnowflakeに接続してクエリを実行してみます。
from snowflake.snowpark import Session
connection_parameters = {
"account": "kw71477.ap-northeast-1.aws",
"user": "shimotaki",
"password": "mypassword",
"database": "テスト",
"warehouse": "テストウェアハウス",
}
session = Session.builder.configs(connection_parameters).create()
result = session.sql("SELECT * FROM product").collect()
print(result)接続用のパラメータを指定しています。ここでは、「テスト」というデータベースと「テストウェアハウス」というウェアハウスが作成されていることが前提です。過去の記事を参照してください。
パラメータをもとに、セッションを作成し、クエリを実行しています。
productというテーブルが存在しているとして、以下のデータが入っています。

以下の箇所でクエリを実行しています。
result = session.sql("SELECT * FROM product").collect()実行結果は以下となります。
[Row(ID=1, NAME='aaaa', PRICE=1000), Row(ID=2, NAME='bbbb', PRICE=2000), Row(ID=3, NAME='cccc', PRICE=3000)]
テーブルのデータが取得できています。
sqlメソッドは、DataFrameオブジェクトを返すようです。pandasのDataFrameと関係あるのかと思いましたが、違うようです。ただ、pandasのDataFrameに変換するメソッドは用意されているようです(to_pandas)。
DataFrameオブジェクトは、公式ドキュメントによると「DataFrame は、遅延評価されるリレーショナルデータセットを表します。これは、特定のアクションがトリガーされたときにのみ実行されます。ある意味で、 DataFrame は、データを取得するために評価する必要があるクエリのようなものです。」とあります。
collectメソッドは、このDataFrameが表すクエリを実行し、結果として、Rowオブジェクトのリストを返すようです。
sqlメソッド以外にも、tableメソッドを使うとテーブル名を直接指定する形でデータを取得できます。
result = session.table("product").collect()実行結果は以下となります。先程と同じです。
[Row(ID=1, NAME='aaaa', PRICE=1000), Row(ID=2, NAME='bbbb', PRICE=2000), Row(ID=3, NAME='cccc', PRICE=3000)]
tableメソッドは、Tableオブジェクトを返します。Tableクラスは、DataFrameのサブクラスです。
取得したDataFrameオブジェクトに対して、様々な変換処理を行えます。
・行の選択
・列の選択
・結果のフィルタリング
・並べ替え
・グループ化
・など
ここでは例として、filterメソッドを使って、行の選択を試してみます。
from snowflake.snowpark.functions import col
result = session.table("product").filter(col("id") == 1).collect()列を指定するには、col関数を使います。ここでは、id 列を指定し、idが1の行を選択しています。
実行結果は以下となります。
[Row(ID=1, NAME='aaaa', PRICE=1000)]
なお show メソッドを使うとテーブル形式で出力してくれます。
session.table("product").filter(col("id") == 1).show()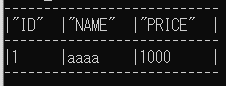
今回は以上です。
今回紹介した以外のトピックが公式ドキュメントで紹介されています。機会があれば試していきます。
・Pythonでの DataFrames 用ユーザー定義関数(UDFs)の作成
・PythonでのDataFramesのユーザー定義テーブル関数(UDTFs)の作成
・PythonでDataFramesのストアドプロシージャを作成
・Snowpark Pythonでの関数とストアドプロシージャの呼び出し
・Snowpark Pythonを使用した機械学習モデルのトレーニング
株式会社分析屋について
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。