
【Dify初心者講座】RAGの作り方

RAG(Retrieval Augmented Generation)とはLLMに情報検索機能を与え、特定の情報源を元に回答を生成させる手法です。
RAGによって特定のWebページや資料を元にハルシネーションの危険性を最小限に抑えた回答をさせることができます。
DifyにはRAGを簡単に構築する機能が備わっています。
ここではRAGを使った簡単なチャットボットとワークフローを作成し、その作り方を学んでいきます。
ナレッジデータベースの作り方
まず、RAGに必要なナレッジデータベースの作り方を説明します。
ナレッジデータベースとは、特定のWebページやPDFなどのドキュメントを元に作成された、検索システムのことです。
作成したナレッジデータベースをチャットボットなどに登録することで、チャットボットがクエリを作成→検索→参照して回答するような動きが可能になります。
ナレッジデータベースを作成は、まず画面上部のナレッジボタンでナレッジ管理画面に移動し、「ナレッジを作成」ボタンをクリックします。
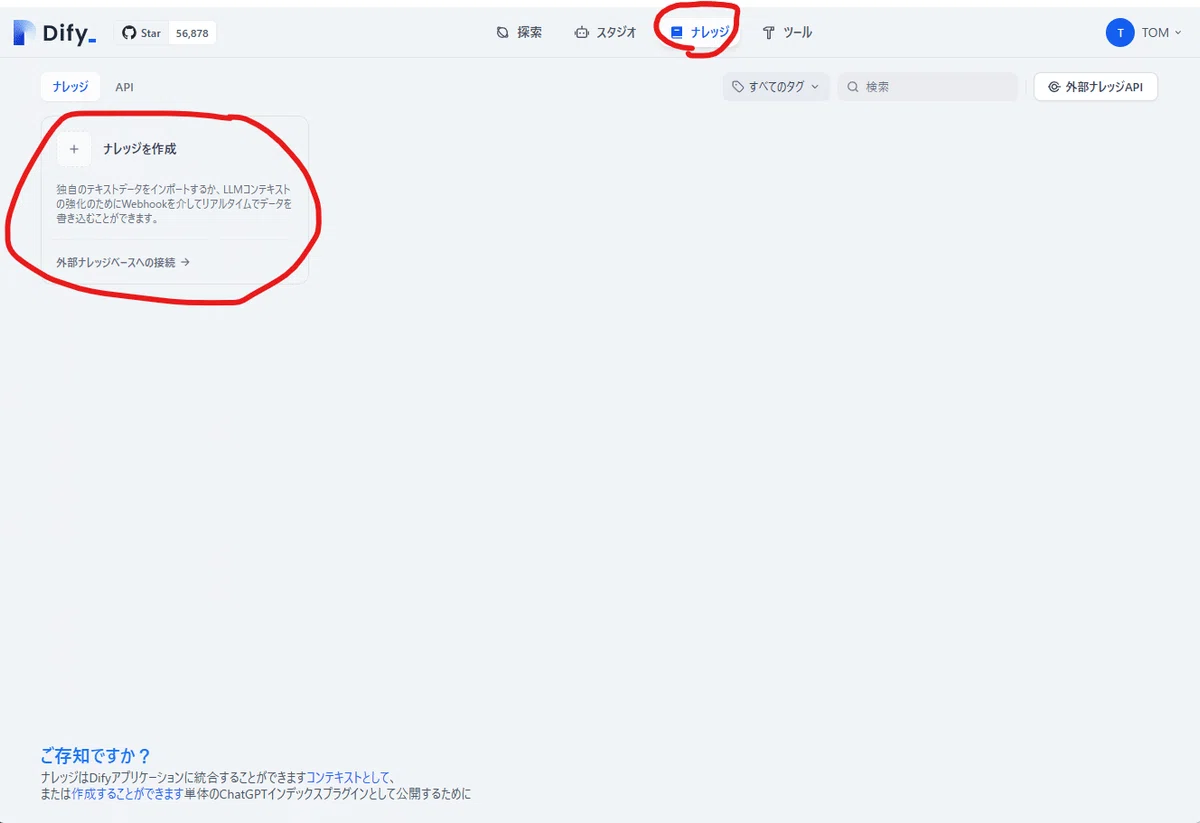
ナレッジデータベースは以下の3つの作成方法が選べます。
テキストファイルからインポート
txt, md, pdfなど、様々な形式のファイルから作成する方法
最も手軽にRAGを実践できる
Notionから同期
Notionと連携したデータベースを作成する方法
手動更新ではあるが、簡単にデータベースの管理・更新が可能
marumarumaruさんの解説がわかりやすかった
ウェブサイトから同期
特定のウェブサイトと連携したデータベースを作成する方法
特定のウェブサイトを深堀スクレイピングしてナレッジデータベースを作成できる
Jina readerかFirecrawlツールとの連携が必要
今回は最も簡単な「テキストファイルからインポート」を選択します。

次にテキストファイルを選択してアップロードしてください。
とりあえず試してみたい方は、総務省が出している情報通信白書でもアップロードしておきましょう。
ちなみに、情報通信白書のフルバージョンはサイズが大きすぎてアップロードできませんでした。
そういった場合、私はI LOVE PDFというツールで分割して使用しています。
ファイルをアップロードして「次へ」を選択すると、テキストの前処理とクリーニング画面に遷移します。
ここではテキストを数百文字程度のチャンクと呼ばれる塊に分割する設定を行います。
とりあえず、以下のように設定してください。
チャンク設定 : 自動
インデックスモード : 高品質
埋め込みモデル : text-embedding-3-small
検索設定 : ハイブリッド検索
Rerankモデル : rerank-v3.5
トップK : 3
スコアしきい値 : OFF

設定内容を一つずつ説明していきます。
チャンク設定 : 自動
チャンクの長さや区切り文字などをデフォルト設定のまま使う設定です。
チャンク設定をカスタムにすると、区切り文字やチャンクあたりの最大文字数、オーバーラップのサイズを設定できますが、こちらは精度を上げるための最後の手段と考えて良いと思います。
とりあえず、チャンク設定は自動にしておきましょう。
インデックスモード : 高品質
OpenAIなどの外部APIを用いてチャンクのベクトル化や、リランキングなどを行う設定です。
外部APIを使うため、利用料に応じたコストが発生します。
インデックスモードを経済的にすると、APIを使わずにベクトル化などを行って検索を実行できますが、日本語ドキュメントでこれを使っても実用的な精度はでませんでした。
基本的には高品質の設定一択だと思います。
埋め込みモデル : text-embedding-3-small
検索をするときには、クエリを検索に用いるベクトルデータに変換するEmbeddingという処理を行います。このときに使うモデルの設定がこれです。
OpenAI APIの場合、text-embedding-3のsmallかlargeが選択肢に上がると思いますが、基本的にはsmallで十分かと思います。
APIや検索時の計算リソースの観点から、largeはだいぶコスパが悪いので、どうしても検索精度が出ないときだけlargeを検討しましょう。
検索設定 : ハイブリッド検索
こちらは検索に使用する手法の設定です。
ベクトル検索、全文検索、ハイブリッド検索の3つが選べます。
ベクトル検索は文章全体の意味に着目して類似したチャンクを取得します。
全文検索は同じ文字列に着目して類似したチャンクを取得します。
ハイブリッド検索は、ベクトル検索と全文検索を同時に行い、Rerankingという手法で2つの検索結果から、より検索クエリにマッチしたチャンクを取得する方法です。
大抵のユースケースでは、文章全体の意味が大事な場合と、特定の単語が大事な場合の両方があるので、基本的にはハイブリッド検索が良いです。
Rerankモデルの選択肢にrerank-v3.5が表示されない場合は、モデルプロバイダー設定画面からcohereを選択し、APIキーなどを設定してください。

設定が完了したあとに、「保存して処理」をクリックすると、ナレッジデータベースの作成が始まります。
しばらく待てばナレッジデータベースの完成です。
次はこのナレッジデータベースを使ってチャットボットとワークフローを作成してみましょう。
チャットボットの作り方
先ほど作成したナレッジデータベースを使って、チャットボットを作成してみます。
基本的には「チャットボットの作り方」で説明した内容と同じですが、コンテキストに先程のナレッジデータベースを設定する点だけが異なります。
たとえば、「情報通信白書」のナレッジデータベースを設定する場合は、以下のように設定します。
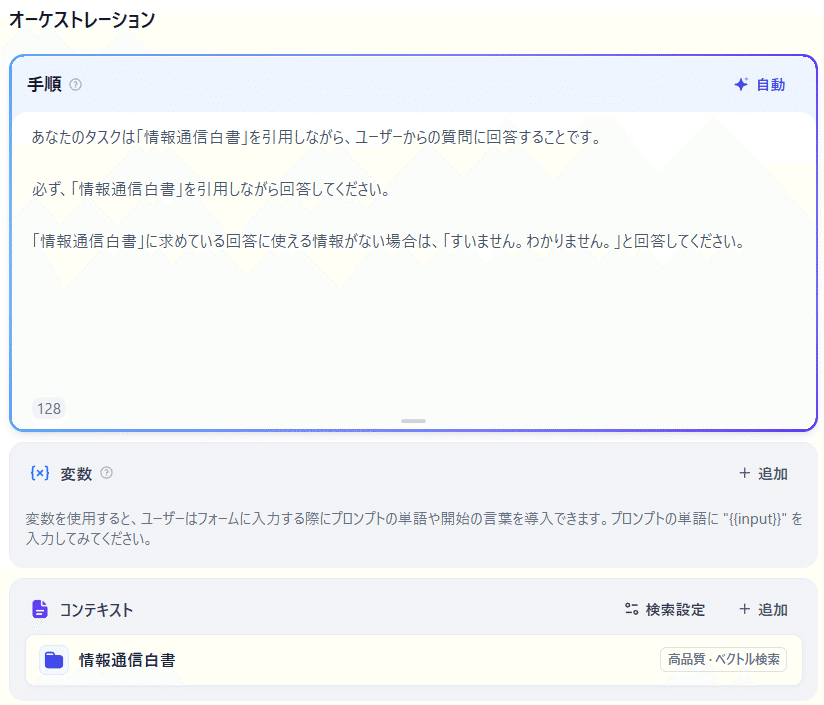
これだけで、情報通信白書の内容を参照しながら回答してくれるBotの完成です。
試しに、「今後注目すべきAI技術は?」と質問をしてみましょう。
結果は以下のようになりました。
情報通信白書によると、今後注目すべきAI技術として生成AIが挙げられます。生成AIは2022年頃から急速に普及し始めた革新的な技術で、人間のように文章や画像を生成し、多岐にわたるタスクを自律的にこなすことができます。
また、AIと他の技術を組み合わせた発展も注目されています。例えば、生成AIとXR(拡張現実)技術を組み合わせることで、教育やエンターテイメントの分野で新たな価値体験を生み出すことが期待されています。
さらに、AIはロボティクスや自動運転技術との連携も進んでおり、これらの分野でも今後の発展が期待されています。
これらの技術は、企業活動や国民生活に大きな変革をもたらす可能性があるため、今後の動向に注目する必要があります。また、コンテキストにナレッジデータベースを設定した場合は、以下のように引用元を確認できます。

同じようにコンテキストに設定すれば、エージェントも作成できるので、ぜひ試してみてください。
ワークフローの作り方
次はRAGを使用したワークフローの作り方の紹介です。
「知識取得ノード」を使うとRAGの仕組みをワークフロー内に組み込むことができます。
それ以外の部分は「ワークフローの使い方」で説明したとおりです。

「知識取得ノード」は簡単に言えばクエリを用いてナレッジデータベースから情報を取得するノードです。
これを使えば必要な知識をナレッジデータベースから取得し、ワークフロー内で使用することができます。
試しに特定テーマのレポートを情報通信白書の内容を使って生成するワークフローを作成してみましょう。
まず作成したいレポートのテーマを入力するフォームを定義します。
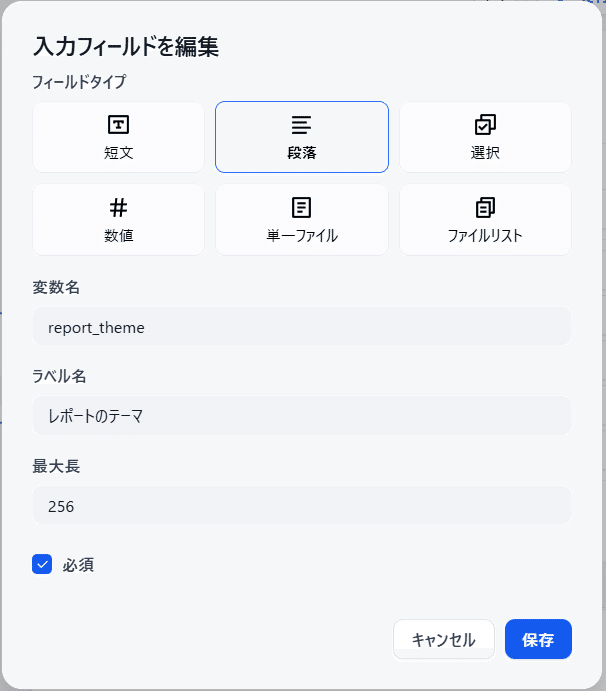
次に知識取得ノードで情報を取得します。
クエリには開始ノードで入力したレポートテーマを使用します。

次にLLMノードを使ってレポートを生成します。
コンテキストに知識取得の結果を利用。
プロンプトは以下のように指定します。
あなたのタスクはテーマに沿ったレポートを作成することです。
コンテキストの内容を利用して、レポートを作成してください。
レポートはマークダウン形式で出力してください。
あなたの想像ではなく、コンテキストの内容のみでレポートを作成してください。
# レポートテーマ
{report_theme}
# コンテキスト
{コンテキスト}
最後に終了ノードで結果を出力します。

作成したワークフローの全体像は以下です。

試しに「2024年に注目された新技術」のテーマで実行すると、以下のようなレポートが出力されました。
# 2024年に注目された新技術レポート
## はじめに
本レポートでは、2024年に特に注目された新技術について、コンテキストとして提供された情報をもとにまとめます。
## 1. AI(人工知能)技術
### 1.1 生成AIの進化
2022年以降、生成AIが本格的に普及し始め、画像や文章などを自動生成する技術が急速に発展しました。この動向は2024年も継続し、開発競争が激化しています。
- **産業界での活用例**:
- 保険業界では、AIアバターを活用した営業ロープレで成果を上げています。
- システム開発においては、レガシー資産のモダナイズに生成AIが活用されています。
- 建設業では、大規模言語モデルを特化させた「AKARI Construction LLM」や、建築設計の初期段階を効率化する「AiCorb®」といったツールが登場しています。
- 大林組は、AIツールを用いてビルの外観を生成し3次元化する技術を開発し、社内運用を開始しました。
- **研究開発の動向**:
- 産業技術総合研究所では、生成AIに関する研究開発が進められています。
- AIは、端末に搭載されたAIがネットワークを通じて他のAIと協調し、より複雑で高度な処理を実行する方向へ進化しています。
### 1.2 AIを活用した原子レベルシミュレーター
- **Matlantis™**:AI駆動の汎用原子レベルシミュレーターであり、材料開発の分野で注目されています。この技術により、超高速計算が可能になり、材料開発の世界に変革をもたらすと期待されています。
## 2. ロボティクス
### 2.1 ロボットとAIの融合
- ロボット技術とAI(特に大規模言語モデル)の融合が進んでいます。これにより、ロボットはより高度なタスクを実行できるようになると期待されています。
- **家庭用ロボットの登場**:
- Preferred Robotics社の「カチャカ」は、人の指示で家具を動かすことができるスマートファニチャー・プラットフォームとして注目されています。
### 2.2 ロボティクスの市場動向
- 日本はロボティクス分野で強みを持っており、特に産業用ロボットでは世界市場シェアの46%を占めています。
## 3. Beyond 5G
### 3.1 新たな情報通信技術戦略
- Beyond 5Gの研究開発、国際標準化、社会実装、海外展開を推進するための新たな戦略が策定されました。
- 情報通信審議会では、「Beyond 5Gに向けた情報通信技術戦略の在り方」最終答申が取りまとめられました。
- **重視すべき視点**:
- ネットワークオーケストレーション技術
- 無線ネットワーク技術
- オール光ネットワーク
- 情報通信装置・デバイス技術
- AIの活用
## 4. メタバース
### 4.1 メタバースの活用
- **就労支援**:
- 福岡県や東京都江戸川区では、メタバースを活用した就労支援や区役所サービスが提供されています。
- **国際的な議論**:
- 総務省は、OECDと共同で「民主的価値に基づくメタバースの実現」をテーマとしたセッションを開催し、国際的な議論に貢献しています。
## まとめ
2024年は、AI技術、ロボティクス、Beyond 5G、メタバースといった分野で、技術革新と社会実装が加速した年と言えます。特に、AIとロボティクスの融合は、今後の技術発展の重要な方向性を示唆しています。また、Beyond 5Gやメタバースといった新しいテクノロジーの社会実装も進んでおり、今後の発展が期待されます。結構うまく出力できています。
それなりに使えるものができました。
最後に
この記事はDify初心者向け講座の一項目です。
気になる方は他の講座もご確認ください。
次回はワークフローやエージェントで活用したい、初心者向けノード(ツール)の解説をします。