
ログ転送基盤のDocker移行

これはSupership株式会社の 「データソリューションスタジオ プロダクト開発グループ」における社内勉強会の発表資料を外部公開向けに再編したものになります。
アジェンダ
・ログ転送基盤とはなにか
・稼働するとはどういう状態を指すのか
・なぜDocker化する必要があったのか
・Docker化にあたっての検討事項
・構成の前提
・forwarderのバッファをどうするか
・aggregatorのバッファをどうするか
・コンテナ起動後に転送先に疎通できないときどうするか?
・現在の本番環境での構成
・Docker環境への移行の検証
ログ転送基盤とはなにか
前回書いたnoteの記事で多少触れているスマホ向けコンテンツ配信基盤で生成されたログの転送と集約を行うシステムを指します。
以下では可読性のために「スマホ向け配信基盤」を略して「配信基盤」として表記します。
具体的には以下を行うシステムです。
・配信基盤が配信したコンテンツのログの集約とS3とUSリージョンのGCPへの転送
・Nginxログの集約とS3への保存
・配信基盤が動いている環境のsyslogの集約とS3への保存
・ログ転送基盤で用いているFluentdのログの集約と保存
配信基盤が受けるトラフィックの例
毎日10時, 12時, 15時にスパイクがあり、また毎月3回大きなスパイクが発生する日があります。
そしてこの殆どのトラフィックがUSリージョンのGCPへ転送するログとなり、そのログを最終的にレポートと言う形で運用者に届けることがこのログ転送基盤の仕事です。

稼働するとはどういう状態を指すのか
・配信基盤がリクエストに対して正常にレスポンスを返す
・ログの転送可否に関わらずユーザーにはエラーを返さない
・ログをGCPまで欠損なく確実に届ける
・配信基盤が配信した内容を正確にレポーティングできる状態を維持する
なぜDocker化する必要があったのか
・構成管理はChefがで行っていたが同一の環境が再現できるか不明だった
・Chefをもう一度メンテナンスするよりコンテナ化をしたほうが効率的
・配信基盤でピークに発生する50x系レスポンスのアラートを解決する必要があった。
・より柔軟にスケールする運用を行いたかった
・配信基盤がDocker移行するのであればログ転送基盤もDocker移行したかった
Docker化にあたっての検討事項
構成の前提
ログ転送のTopologyはFluentdの log forwarders と log aggregators による構成を前提として構築しています。
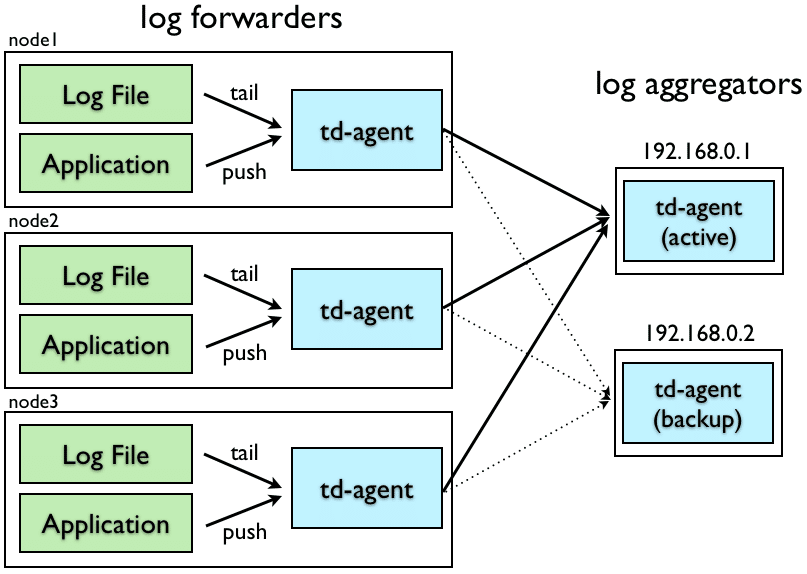
引用元: High Availability Config - Fluentd
forwarderのバッファをどうするか
・forwarderはバッファサイズを小さくする
・バッファはコンテナのファイルバッファを利用
・シャットダウンなどシグナルが届いたらフラッシュさせる
・flush_at_shutdown = true
・送信先のaggregator落ちていたら?
・SecondaryにDNSラウンドロビンしたホスト名を向ける
aggregatorのバッファをどうするか
・ログを圧縮したり、一定期間ログをバッファしてから送りたい要件があるのでバッファが必須
・ホストのディレクトリをマウントしてprimary, standbyの役割のコンテナは同じポイントを参照し続ける
例:
・/mnt/host/primary_container/
・/mnt/host/secondary_container/
・コンテナ自体にバッファを持たせないのでデプロイも容易になる
・常に同じ役割のコンテナしか参照しないため、ログファイルの不整合も起こらない
コンテナ起動後に転送先に疎通できないときどうするか?
・out_forwardはログを受け取り転送する段階ではじめてコネクションを貼るので、ログが届いてから疎通できないということが起きる
・VMのときと違ってホストのスケールアウトやスケールインに応じてFluentdのコンテナが増減するため、不安があった。
・Fluentdにパッチを送り、起動時に疎通確認をするオプションをつけた
・verify_connection_at_startup = true (Default false)
・Fluentdのバージョン1.3.1から使用可能
・疎通できない場合はログを受け取っても転送できない可能性があるので異常終了するようになった。
・Add connection check at startup when out_forward. #2184
現在の本番環境での構成

Docker環境への移行の検証
Docker環境に移行するにあたって、検証したい項目を洗い出した。
検証項目:
・正常にログ転送が行えレポート集計までおこなわれているかを確認する
検証方法:
・深夜のトラフィックが少ない時間帯で少量をDocker環境に流す
・周辺システムのログを確認して正しく動くことを検証する
検証項目:
・スパイク時の負荷の変化に耐えきれるかを確認する
検証方法:
・リソースの枯渇などが起きないかを確認する
・15:00~(スパイクも比較的ゆるくトラフィック総量もすくない)
・10:00~(スパイクはきついがトラフィックの総量が少ない)
・12:00~(スパイクもトラフィックの総量も非常に多い)
おわりに
これを読んだ方の中にはもっと良い構成をご存知のかたがいらっしゃるかと思います。
もしそんな構成をご存知であればコメントなどでいただけると助かります。