
【Python学習日記6】 タイタニック号の生存予測

こんにちは。プログラミングスクールでPythonを使ったデータ分析を学習中の ひよっこ分析者B(Book358)です。今回は「性別・年齢・乗船料金など」の乗船者データからタイタニック号の生存者を予測するkaggleの入門コンペにトライしてみました。(LightGBMで学習し、LIME(XAI)でどの特徴量が予測に大きく影響しているか検証してみました。)
※ 開発環境
Python3,Windows11 ,Chrome,Google Colaboratory
1. 概要
1.1 題目
Titanic - Machine Learning from Disaster
1.2 目的
「性別・年齢・乗船料金など」の乗船者データを用いて、タイタニック号での災害発生時の生存者を予測する機械学習モデルを構築すること
1.3 データセット
・train.csv
訓練データ
・test.csv
評価データ
・gender_submission.csv
投稿データ (フォーマット)
2. タイタニック号とは
タイタニック(RMS Titanic)は、20世紀初頭に建造された豪華客船です。 航海中の1912年4月14日深夜、北大西洋上で氷山に接触、翌日未明にかけて沈没しました。犠牲者数は乗員乗客合わせて1,513人(他に1,490人、1,517人、1,522〜23人、1609人など様々な説がある)であり、20世紀最大の海難事故です。タイタニックとその事故は、しばしば映画化されるなどして世界的に知られています。
3. ライブラリのインポート
使用するライブラリをインポート。
!pip install lime
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.metrics import accuracy_score
from lime.lime_tabular import LimeTabularExplainer
from google.colab import drive
import warnings
drive.mount('/content/drive')
warnings.simplefilter('ignore')4. データセット
訓練データ(train.csv)を読込み、乗船者の特徴(性別・年齢・乗船料金など)と生存関係をプロットし、生存に影響している特徴を把握します。
4.1 訓練データ
訓練データ(train.csv)を読込み、データ型を確認します。
train = pd.read_csv('/content/drive/MyDrive/Datasets/Titanic_train.csv')
train.head(3)
train.dtypes
Survived : 1が生存、0がそうでない
Pclass : チケットのクラス、1st=1, 2nd=2, 3rd=3
Sex : 男性(male), 女性(female)
Age : 年齢
SibSp : 兄弟、配偶者の人数
Parch : 両親、子供の数
Ticket : チケットの番号
Fare : 乗船料金
Cabin : 部屋番号
Embarked : 乗船した港 (S=Southampton, C=Cherbourg, Q=Queenstown)
4.2 統計量
カテゴリカル変数を数値型(int64)から文字列型(str)へ変換した後、統計量を確認します。
train = train.astype({'PassengerId': str, 'Pclass': str})
display(train.describe())
(Ageのcountが891になっていない → 欠損値あり)
4.3 性別による生存者数
性別(Sex)による生存者数を確認します。
sns.countplot(x='Sex', hue='Survived', data=train)
(女性よりも男性の生存率が低い)
4.4 年齢による生存者数
年齢(Age)による生存者数を確認します。
fig = sns.FacetGrid(train, col='Survived', hue='Survived', height=4)
fig.map(sns.histplot, 'Age', bins=30, kde=False)
(20代の生存率が低い)
4.5 乗船料金による生存者数
乗船料金(Fare)による生存者数を確認します。
fig = sns.FacetGrid(train, col='Survived', hue='Survived', height=4)
fig.map(sns.histplot, 'Fare', bins=30, kde=False)
(乗船料金が低いほど生存率が低い)
4.6 兄弟・配偶者の数による生存者数
兄弟・配偶者の数(SibSp)による生存者数を確認します。
sns.countplot(x='SibSp', hue='Survived', data=train)
plt.show()
(兄弟・配偶者の数が1~2人の場合は生存率が高い)
4.7 両親・子供の数による生存者数
両親・子供の数(Parch)による生存者数を確認します。
sns.countplot(x='Parch', hue='Survived', data=train)
plt.legend(title='Survived' ,loc='upper right')
plt.show()
(両親・子供の数が1~3人の場合は生存率が高い)
4.8 相関係数
数値データの相関係数を確認します。
sns.heatmap(train[['Survived','Age','SibSp','Parch','Fare']].corr(), vmax=1, vmin=-1, annot=True)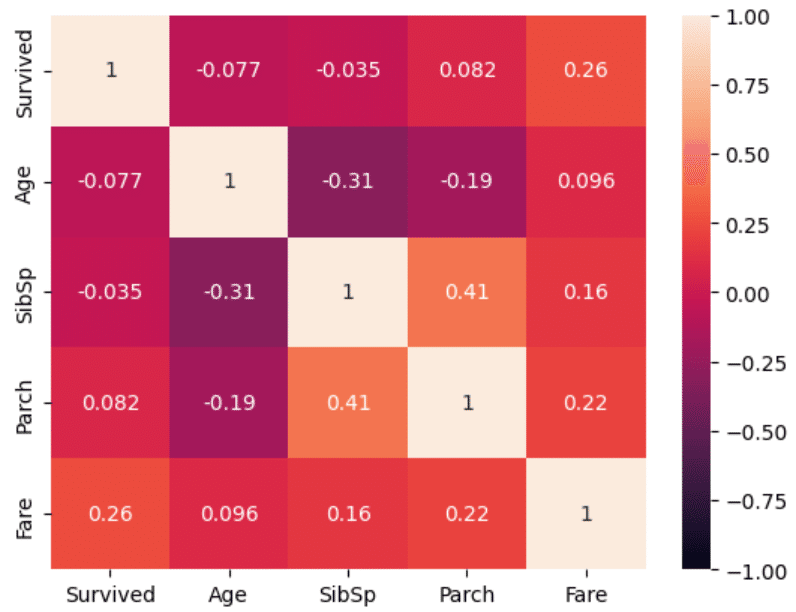
(SibSpとParch:正の弱い相関 (0.41)、SibSpとAge:負の弱い相関 (-0.31))
4.9 船室等級による生存者数
船室等級(Pclass)による生存者数を確認します。
sns.countplot(x='Pclass', hue='Survived', data=train)
plt.show()
(等級が低いほど生存率が低い)
4.10 乗船した港による生存者数
乗船した港(Embarked)による生存者数を確認します。
sns.countplot(x='Embarked', hue='Survived', data=train)
plt.show(
(乗船した港で生存率に差がある)
5. 前処理
5.1 欠損値補完
欠損値を確認し、補完します。今回は特徴量として用いる項目の内、年齢(Age)と乗船した港(Embarked)に欠損があります。
(Ageは平均値、乗船した港はNaNで欠損を埋めます。)
train.isnull().sum()
train['Age'] = train['Age'].fillna(train['Age'].median())
train['Embarked'] = train['Embarked'].fillna('NaN')5.2 One-Hotエンコード
カテゴリカルデータをダミー変数(0 or 1)に変換します。
train = pd.get_dummies(train, columns= ["Sex", "Pclass", 'Embarked'], dtype=float)
train.head(3)
6. モデル構築
予測に用いないカラムを削除し、特徴量(X)とし、交差検証(ホールドアウト)してLightGBMで学習し、モデルを構築します。
X = train.drop(['PassengerId', 'Age', 'Ticket', 'Fare', 'Cabin', 'Name', 'Survived'], axis=1)
y = train['Survived']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=0)
params = {
'boosting_type':'gbdt',
'objective':'binary',
'metric':'auc',
'num_leaves':16,
'learning_rate':0.1,
'n_estimators':100000,
'random_state':0
}
model = lgb.LGBMClassifier(**params)
model.fit(X_train, y_train, eval_set = [(X_train, y_train),(X_val, y_val)], callbacks=[lgb.early_stopping(stopping_rounds=50)])
accuracy_score(y_val, model.predict(X_val))
7. 予測説明 (LIME)
7.1 関数を定義 (predictの変換)
LIMEでLightGBMのpredict(予測値)を使える形に変換する関数を定義します。
def predict_fn(test):
preds = model.predict(test).reshape(-1, 1)
p0 = 1 - preds
return np.hstack((p0, preds))7.2 LIMEの計算
LIME計算のアルゴリズム(パラメータ)を定義します。
explainer = LimeTabularExplainer(
test.values,
mode = 'classification',
feature_names = test.columns,
class_names = ["Death", "Survival"],
verbose = True)7.3 データを指定して出力
テストデータの15番目のインデックス(女性, 2等船室, C港乗船)について、LIMEによる予測説明をアウトプットしてみます。
test[15:16]
i = 15
exp = explainer.explain_instance(test.values[i], predict_fn, num_features=5)
exp.show_in_notebook(show_all=False)
7.4 検証
Fig.9(左図のPrediction probabilities)からLIMEによる予測は「Survival (生存)」です。中央と右の図から、Sex_female (女性), Pclass_3 (3等船室), Embarked_S (S港で乗船)という特徴を基準に生存率を予測している事が分かります。

8. 考察
今回の「タイタニック号の生存予測」では、「性別・年齢・乗船料金など」の乗船者データを元に、LightGBMでモデルを構築し、タイタニック号の生存者を予測しました。交差検証(ホールドアウト)でのスコアは「0.88 (best iteration)」でした。(kaggleでのSubmitスコアは「0.77」)
生存に大きく影響している特徴は「性別」,「乗船料金」,「乗船した港」。男性、3等船室、S港で乗船といった条件では生存率が下がる傾向が見受けられました。LIME(XAI)による予測説明でも「Sex_female (女性)」が一番に挙がった事もあり、タイタニック号の海難事故では性別が最も生存率に影響している可能性があると考えられます。