
【Python学習日記1】 ペンギンデータの二項分類

こんにちは。プログラミング初心者で、Pythonを使ったデータ分析を習い始めたばかりの ひよっこ分析者B(Book358)です。今回はスクールでPythonの機械学習の基礎を教わったので、その実践としてkaggleの南極ペンギンの種類を予測する初心者向けのコンペにトライしてみました。
※ このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を
満たすために公開しています。
※ 開発環境
Python3,Windows11 ,Chrome,Google Colaboratory
1. 概要
1.1 題目
Palmer Penguins for binary classification
(二項分類用のパーマーペンギン)
1.2 目的
南極パーマー島に生息する2種類のペンギンデータを用いて、生息地・くちばしやヒレの長さ・体重・性別といった特徴量からペンギンの種類を予測する機械学習モデルを構築すること。
1.3 ペンギンの特徴
ジェンツーペンギン (Pygoscelis papua)
生息地:主に南極半島と近隣の島々に生息
身体的特徴:明るいオレンジがかった赤のくちばしと、頭頂部に広がる白い
縞模様によって識別可能。ペンギンの中でも大型種の一つ。
食事:主にオキアミを食べるが、魚やイカも食べる。
行動:速い泳ぎと、採餌中に長く深く潜ることで知られている。

アデリーペンギン (Pygoscelis adeliae)
生息地:南極海岸全体に広く分布
身体的特徴:ジェンツー ペンギンよりも小さく、特徴的な黒と白の羽毛と青
黒いくちばしが特徴
食事:主にオキアミを食べ、魚やイカも食べる。
行動:非常に社交的で、繁殖期には大音量の鳴き声と攻撃的な行動で
知られている。

1.4 データセット
・南極半島の北西海岸沖にある島々のグループであるパーマー諸島で収集さ
れた。
・数種のペンギン、アザラシ、海鳥など、多様な野生動物が生息している。 ・この群島は、地球上で最も急速に温暖化が進んでいる地域の 1 つであるに
もかかわらず、気温が低く、強風があり、氷に覆われていることが特徴。
2. モデル構築
以下の手順で、分類のアルゴリズムにLogisticRegression (ロジスティック回帰)を用いたモデルを構築しました。
2.1 ライブラリのインポート
使用するライブラリをインポート。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score ・pandas
Pythonのデータ解析ライブラリ
・seaborn
Pythonの可視化ライブラリ
・matplotlib.pyplot
Pythonのグラフ描画のためのライブラリ
・train_test_split
データセットや配列を訓練データとテストデータに分割するための関数
・LogisticRegression (ロジスティック回帰)
出力変数が「1」もしくは「0」の2値になる二値分類を予測する手法
(任意の値を「0」から「1」に置き換えるシグモイド関数を用いて、与
えられたデータから2つに分類)
・accuracy_score (正解率)
予測結果全体がどれくらい真の値と一致しているかを表す指標
2.2 データセットの読込
pd.read_csv()でkaggleのinputからデータセットを読込みます。今回は274行, 7列のデータセットがあります。一番左の「species (種族)」が機械学習モデルで予測(二項分類)できる様にしたい項目です。
df = pd.read_csv('/kaggle/input/palmer-penguins-for-binary-classification/penguins_binary_classification.csv')
df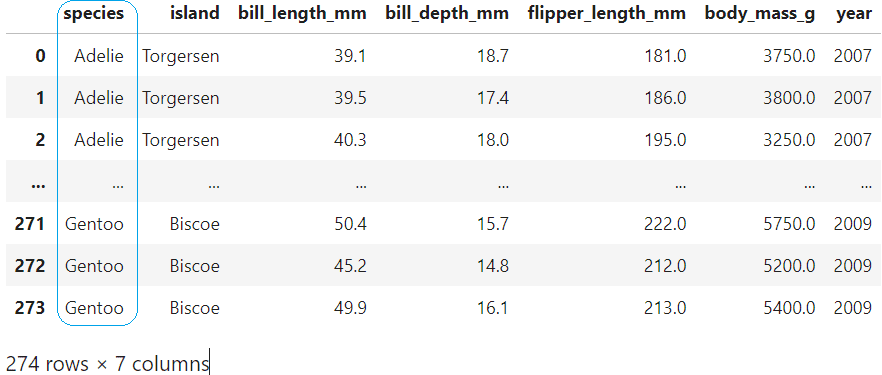
species :ペンギンの種族 (Gentoo, Adelie)
island :島 (Torgersen, Biscoe, Dream)
bill_length_mm :くちばしの長さ (㎜)
bill_depth_mm :くちばしの奥行き (㎜)
flipper_length_mm:ヒレの長さ (㎜)
body_mass_g :体重 (g)
year :オス(male), メス(female)
2.3 欠損値の補完
.isnull().sum()で欠損値の有無を確認します。初心者向けのコンペなので、データに欠損値はない様です。
df.isnull().sum()
2.4 カテゴリカルデータの変換
カテゴリカルデータ(数値でない列)があると解析時にエラーが出る事がある為、.replace()で「species」と「island」の列を数値データ(ダミー変数)に変換します。
df['species'] = df['species'].replace('Adelie', 0)
df['species'] = df['species'].replace('Gentoo', 1)
df['island'] = df['island'].replace('Torgersen', 0)
df['island'] = df['island'].replace('Dream', 1)
df['island'] = df['island'].replace('Biscoe', 2)
df ・species (種族)
「Adelie」 →「0」
「Gentoo」→「1」
・island (島)
「Torgersen」→「0」
「Dream」 →「1」
「Biscoe」 →「2」

2.5 データの可視化
sns.pairplot()で散布図行列を描画し、データを可視化します。
sns.pairplot(df, hue='species')
plt.legend()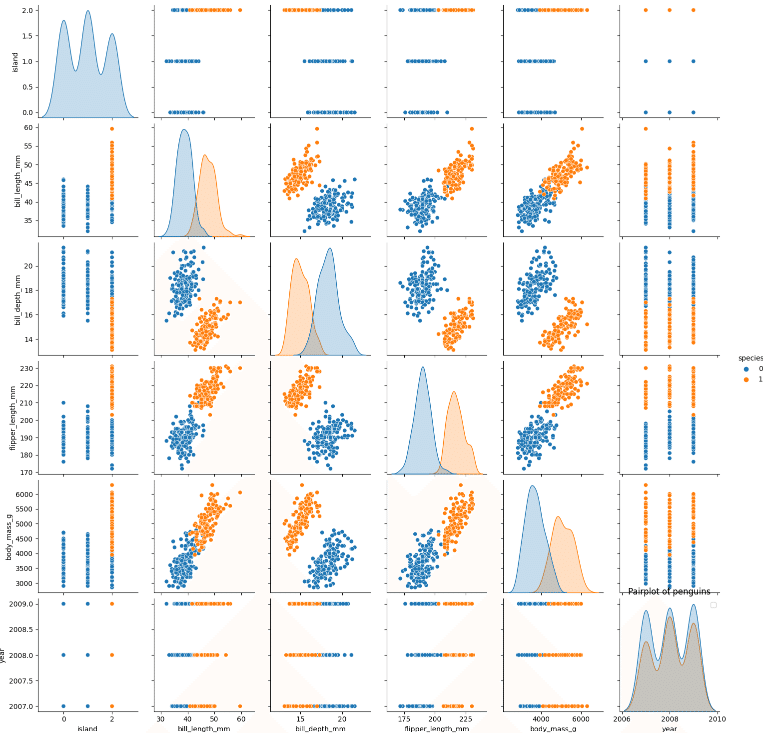
(青:Adelie (0), オレンジ:Gentoo (1))
2.6 相関係数の確認
.corr()で相関係数を算出し、各列(特徴量)間の相関関係を確認します。
(.style.background_gradient()でヒートマップ化)
df.corr().style.background_gradient(cmap='coolwarm', axis=None)
2.7 特徴量と正解ラベルの作成
データセット(df)から特徴量(X)と正解ラベル(y)を作成します。
X = df.iloc[:,1:]
X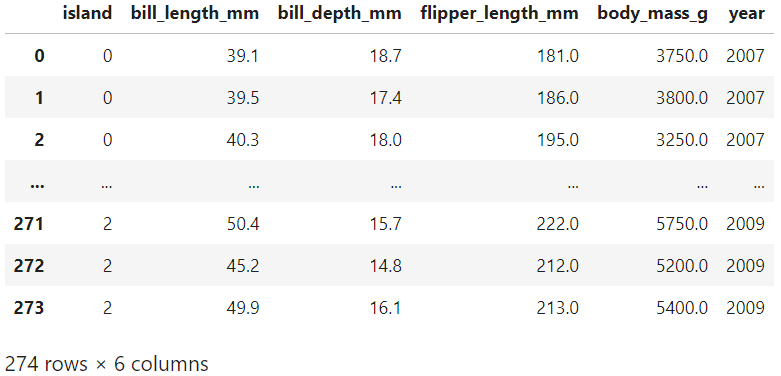
y = df.iloc[:,0:1]
y
2.8 データ分割
交差検証(ホールドアウト)を行う為、train_test_split()で全データ(特徴量(X)と正解ラベル(y))を訓練データ(x_train, y_train)と検証データ(x_test, y_test)に分割します。
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) ・test_size
検証データのデータサイズ
※今回は全データの30%(0.3)に指定
・random_state
乱数の発生機
1などの任意の値(seed)を与えると、毎回同じ乱数を発生させるため再
現性が得られる。train_test_split()では、この乱数を指定する事で、常
に同じようにデータが分割される。
2.9 機械学習
機械学習に用いるアルゴリズム(ロジスティック回帰)を定義し、.fit()で訓練データ(x_train, y_traijn)を入れて学習し、モデルを構築します。
model = LogisticRegression()
model.fit(x_train, y_train)
model
3. モデルの評価
accuracy_score()を用いて、訓練データ(x_train, y_traijn)・検証データ(x_test, y_test)それぞれに対し、学習済モデルの正解率(予測精度)を算出します。
(訓練データの場合、第一引数に「正解ラベル(y_train)」,第二引数に「特徴量からのモデル予測値(model.predict(x_train))」を指定)
print(f'Train_acc:{accuracy_score(y_train, model.predict(x_train))}')
print(f'Test_acc :{accuracy_score(y_test, model.predict(x_test))}')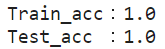
4. 予測
検証データの特徴量(x_test)を用いて、.predict()で学習済モデルによる「species (種族)」の予測を行います。
(予測結果はpd.DataFrame()でデータフレーム化)
sub = pd.DataFrame(model.predict(x_test))
sub.columns = ["species"]
sub
5. 提出ファイルの作成
.to_csv()で予測結果(sub)をcsvに変換します。
sub.to_csv('submission.csv', index=False)6. 考察
今回は、初心者向けのコンペでデータセット(特徴量)が274行, 7列と少なく、「3-5. データの可視化」のグラフからみても「0:Adelie ( )」 と「1:Gentoo」の特徴分布(位置)が概ねはっきりと分かれていました。
sns.pairplot(df, x_vars=['bill_length_mm'], y_vars=['flipper_length_mm'], hue='species')
sns.pairplot(df, legend=False)
plt.legend()
(青:Adelie (0), オレンジ:Gentoo (1))
非常に二項分類し易いデータであった為、交差検証(ホールドアウト)での学習済モデルの正解率(accuracy_score)では、訓練テータ(train)・検証データ(test)共に1.0と完全な予測精度が出ました。
7. 反省
今回のkaggleのコンペ(Palmer Penguins for binary classification)は、現在submission(投稿)できない題目でした。始める前に「Leaderboard」がまだ表示されているかなどを良く確認しておかないといけない様です。

8. まとめ
初心者の私にとって、ペンギンデータの二項分類のコンペは機械学習の
流れがとても分かり易く、勉強になりました。この調子で、少しずつ難易度の高いコンペにもトライしていきたいと思います。