
盆栽データで ML 実践してみた (+ 5/9追記)

jun@bitnengineers です。
4月になり新芽が沢山伸びました。盆栽始めて3年目の春で、成長が見えて楽しいですね。
中には新芽に紛れて、花粉のうもありました。この中に花粉が詰まっています。松の花粉もアレルゲンらしく、吸いすぎると花粉症にもなりうる危険なものです。触ってみたら花粉が目視できるレベルで舞ってました。

先月蒔いた種も発芽して春の変化を満喫しております。


さて、本題へ。
前回 AWS 上での ML を扱いました。SageMaker 上に ML 環境を構築する内容でしたが、今回は実際に取得しているデータを使ってML処理で推論を行ってみます。
勉強しながらのものなので未熟な点は多いかと思います。ほんの一例として見ていただけると丁度良いかと思います。
Dataset
これまで取得したデータの column は主にメタデータ、稼働状態の確認・管理データ、水やり管理用の秤設定・重さ、環境データなどです。
メタデータ
timestamp データ取得時刻
clientId 鉢毎の対象識別子
稼働管理
voltage バッテリー電圧。残量の算出に使用。
charge_current 充電電流。充電状態確認に使用。
current 消費電流。voltage と合わせて残り稼働時間の推測等に使用。firmware 実装の改善にも。
重さデータ
scale_zerooffset 秤の0[g] 時のセンサー値。オフセット。
scale_lsb センサーの1bit が何g かに用いる
scale_gain センサーの設定。 27bit 出力モード。ずっと固定の予定。
weight_value 秤で量った値。 scale_lsb * weight_value = 実際の重さ[g]
環境データ
env_temperature 環境温度(試験的に使用)
env_humidity 環境湿度(試験的に使用)
env_light 環境光(試験的に使用)
env_temperature, env_humidity, env_light は試験的に一部の鉢でのみ収集してます。
取得頻度は5~10分ほどです。運用上、常時稼働出来ていなかったこともあるので途中途中欠けています。
clientId は鉢毎に違うものを使っています。それぞれ鉢の大きさが違うので水やり管理はclientId 毎に行うことになります。
PreProcess
Dataset は上に書いた通りなのですが、さて、何をどう推測できたら良いか、と考えてみたところ、
温度T, 湿度H 環境においてねある時間T辺りの水分量の減り具合X
が推測できたら面白いのではないか?と。
おそらく鉢の置かれる環境によっては風が強く吹いていたり、また鉢の大きさによっても露出している土の表面積が違う、などで減る水分量は左右されそうですが、取得したデータに基づいてそれっぽい値になるのではないか、と期待します。
ということで進めていきます。
まず、データを前処理していきます。元データは以下の感じです。
>>> bonsai_df.describe()
water_level soil_temperature soil_humidity env_temperature \
count 56133.000000 53810.000000 53810.000000 53780.000000
mean 197.204710 15.411294 12.711647 7.911630
std 710.797958 821.563250 538.890179 11.128406
min 0.000000 -45.000000 0.000000 -45.000000
25% 0.000000 0.000000 0.000000 0.000000
50% 0.000000 0.000000 0.000000 0.000000
75% 0.000000 0.000000 0.000000 20.704106
max 4095.000000 64784.000000 61236.000000 89.154648
env_humidity env_light current charge_current voltage \
count 53780.000000 53744.000000 58683.000000 58993.000000 59224.000000
mean 16.916929 193.379447 28.673737 2.261431 328.906775
std 23.424874 297.789435 136.418199 49.916886 1023.435489
min 0.000000 0.000000 0.000000 0.000000 0.000000
25% 0.000000 0.000000 0.000000 0.000000 4.100801
50% 0.000000 0.000000 0.000000 0.000000 4.117301
75% 39.205006 404.000000 0.000000 0.000000 4.131600
max 97.486839 1015.000000 1154.000000 1427.000000 3962.000000
weight_value scale_zero_offset scale_gain scale_lsb timestamp
count 5.070300e+04 5.070000e+04 50703.0 50703.000000 5.615600e+04
mean 7.183342e+06 4.496463e+06 27.0 0.001474 1.645493e+09
std 6.806322e+07 7.302036e+06 0.0 0.004459 4.485871e+06
min -1.677720e+07 0.000000e+00 27.0 0.000000 1.632751e+09
25% 4.096000e+03 7.562100e+04 27.0 0.000940 1.643365e+09
50% 1.371520e+05 1.467360e+05 27.0 0.001740 1.646522e+09
75% 1.725830e+05 1.672694e+07 27.0 0.001910 1.648894eどの行も全体では50000データ以上あります。ここから不要な column を消します。(以前土壌センサーを使って計測していた column ですが、今は使っていません)
bonsai_df = bonsai_df.drop(columns=[""water_level", "soil_temperature", "soil_humidity"])温度、湿度などの 環境データ env_* は1鉢にしかないので、clientId で filter します。
blackpine_bunzan = bonsai_df.query("clientId == 'blackpine_bunzan'")timestamp (epoch time) では直感的に分からないので人に読みやすい datetime に変更します。その際にデータの順序を過去から未来の並びにもします。
bonsai_df = bonsai_df.sort_values(by=["timestamp"], ascending=True)
blackpine_bunzan["datetime"] = blackpine_bunzan.apply(lambda x: pd.to_datetime(x.timestamp, unit="s"), axis=1)weight_value はロードセルのセンサー値をオフセットしたものをそのまま保存しているので、分かりやすいように Gram に変換します。
blackpine_bunzan["weight_gram"] = blackpine_bunzan.apply(lambda x: x.weight_value * x.scale_lsb, axis=1)
blackpine_bunzan.weight_gram.hist()ヒストグラムを見てみると大きく外れた値があるので除去します。

wg_min = blackpine_bunzan.weight_gram.quantile(0.001)
wg_max = blackpine_bunzan.weight_gram.quantile(0.999)
print(f"wg_min = {wg_min}, wg_max = {wg_max}")
# wg_min = 243.64554302000002, wg_max = 308.23633906000026blackpine_bunzan = blackpine_bunzan.query("weight_gram > @wg_min & weight_gram < @wg_max")この調整でヒストグラムは綺麗になりました。

次に水やりを見ます。weight_gram 時間軸が進むに従い下がっている場合が水やり後、反対に上がった時点が水やりした時、と判定できそうです。
weight_gram の微分を見てみます。
blackpine_bunzan["weight_gram_diff"] = blackpine_bunzan.weight_gram.diff().replace(np.nan, 0)
print(blackpine_bunzan.weight_gram_diff.describe())count 14615.000000
mean 0.000369
std 1.850227
min -47.313950
25% -0.142820
50% 0.029140
75% 0.284350
max 35.222500
Name: weight_gram_diff, dtype: float64グラフかしたものが以下です。

外れ値を除外します。
wgd_min = blackpine_bunzan.weight_gram_diff.quantile(0.05)
wgd_max = blackpine_bunzan.weight_gram_diff.quantile(0.93)
print(f"weight_gram_diff min = {wgd_min}, weight_gram_diff max = {wgd_max}")
# weight_gram_diff min = -1.4412274999999966, weight_gram_diff max = 0.9346025000000111
blackpine_bunzan = blackpine_bunzan.query("weight_gram_diff > @wgd_min & weight_gram_diff < @wgd_max")
0の少し下を中央値としてバラついてます。ロードセルで量った値もホワイトノイズはどうしても乗るので多少の増加(0以上の値)を許容しています。
次に、このデータを
水やりした後、T時間後に重量xが減っていくデータ x Row
という形にします。
水やり後のデータを切り出します。
downs = []
weight_gram_quantiles_q = [0.1, 0.2, 0.4, 0.6, 0.8, 0.9]
weight_gram_quantiles = [blackpine_bunzan.weight_gram.quantile(x) for x in weight_gram_quantiles_q]
def quantile_rank(wg):
for x in weight_gram_quantiles_q:
q = blackpine_bunzan.weight_gram.quantile(x)
if q > wg:
return x
return weight_gram_quantiles[-1]
for i, r in blackpine_bunzan.iterrows():
w = r.weight_gram
q = quantile_rank(r.weight_gram)
r["quantile"] = q
if len(downs) == 0:
downs.append([r])
else:
if downs[-1][-1]["quantile"] >= r["quantile"]:
downs[-1].append(r)
else:
downs.append([r])どうやるか色々と迷ったのですが、 weight_gram の値を6個ランクに分類して比較してます。



多少の weight_gram の上昇には左右されずに下り傾向を切り出せました。
データを処理していて思うところは多々ありますが、一旦このデータを使って進めてみます。
4/30 現在、上記の処理で136本の下り傾向のデータがあるので、100 を訓練用の入力値、残り 36 をテストデータとして csv に書き込み、前処理が完了です。
def to_series(_df):
timestamp_diff = _df.timestamp.max() - _df.timestamp.min()
weight_gram_diff = _df.weight_gram.max() - _df.weight_gram.min()
temp_mean = _df.env_temperature.mean()
hum_mean = _df.env_humidity.mean()
light_mean = _df.env_light.mean()
# print(f"time diff = {timestamp_diff}, weight_gram_diff = {weight_gram_diff} temp = {temp_mean}, humidity = {hum_mean}, light={light_mean}")
return pd.DataFrame({"timestamp_diff": [timestamp_diff],
"weight_gram": [weight_gram_diff],
"env_temperature": [temp_mean],
"env_humidity": [hum_mean],
"env_light": [light_mean]})
dd = [to_series(d) for d in dataframes]
train_data = pd.concat(dd)
train_data.to_csv("train/bonsai/train.csv", index=False)
test_data = train_data.sample(36)
test_data.to_csv("train/bonsai/test.csv", index=False)Model 作成
ようやく Model にたどり着きましたが、データの前処理に苦戦してしまったので Model については深堀り出来ていません。
よくある例で試してみます。
INPUT_N = 4
HIDDEN_N = 8
OUTPUT_N = 1
class BonsaiNN(nn.Module):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(INPUT_N, HIDDEN_N)
self.l2 = nn.Linear(HIDDEN_N, OUTPUT_N)
def forward(self, x):
x = self.l1(x)
x = torch.sigmoid(x)
x = self.l2(x)
return x入力層で 4 つのデータ(温度、湿度、経過時間、環境光)を入力し、隠れ層に 8 を指定し1つの出力(重量の差)を得る Model にしてます。
作成した訓練用データを読み込み, Tensor 型にして
train_df = pd.read_csv("train/bonsai/train.csv")
test_df = pd.read_csv("train/bonsai/test.csv")
train_y = train_df["weight_gram"]
train_x = train_df.drop(columns=["weight_gram"], axis=1, inplace=False)
train_x_data = torch.tensor(train_x.values.astype(np.float32))
train_y_data = torch.tensor(train_y.values.astype(np.float32))
test_data = torch.tensor(test_df.values.astype(np.float32))train 関数を作成し、訓練開始。
def train():
model = BonsaiNN()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # , momentum = 0.9)
epoch = 100
for epoch in range(0, epoch):
running_loss = 0.0
for i, x in enumerate(train_x_data):
optimizer.zero_grad()
# print(x)
outputs = model(x)
# print(train_y_data[i])
loss = criterion(outputs, train_y_data[i])
loss.backward()
optimizer.step()
running_loss += loss.item()
logger.info(f"[{epoch+1}] loss: {running_loss}: {loss.item()}")
logger.info("Finished Training")
return model
m = train()
print(f"weight = {m.l1.weight}, bias = {m.l1.bias}")訓練がおわり、出来た Model を評価する。という段階でよくわからない状況に直面し未解決です。
def test_model(elapsedtime, temp, humidity, light):
inputs = torch.tensor(pd.Series([r.timestamp_diff, r.env_temperature, r.env_humidity, r.env_light]).values.astype(np.float32))
outputs = m.forward(inputs.data.flatten())
return outputs.data.flatten()[0]
for col, r in test_df.iterrows():
print(f"inference value = {test_model(r.timestamp_diff, r.env_temperature, r.env_humidity, r.env_light)}, expected={r.weight_gram}")
# 以下出力
inference value = 14.700004577636719, expected=13.76254
inference value = 14.700004577636719, expected=10.302340000000015
inference value = 14.700004577636719, expected=29.660239999999988
inference value = 14.700004577636719, expected=3.322900000000004
inference value = 14.700004577636719, expected=18.04164000000003
inference value = 14.700004577636719, expected=14.20622000000003
inference value = 14.700004577636719, expected=15.288159999999976
inference value = 14.700004577636719, expected=16.399209999999982
inference value = 14.700004577636719, expected=5.043090000000007
...推論値が出力されましたが、以降 Model への入力値を変えてもずっと同じ出力、という状態です。
最初の呼び出しはそこそこ期待させる値が出るんですけどね、、、無念。
今回はここまでです。
おわりに
毎度同じく今回も、うまく行かないと投稿が遅れてしまう、ということになりました。
"PreProcess" が思った以上に大変でした。気づきも多々あり、記述できてないですが、温度によってロードセルの値が変わっていそうなんですよね。水やりしていないのに weight_gram が上がってたりするので、精度には影響ありそうです。途中で気づいてしまいましたが今回は目をつぶりましたw
Dataset が用意されているチュートリアルなどはやったことがありますが、自作データから ML へというのは初めてだったので勉強になりました。
次回リベンジします。
5/9 追記
未解決とは
上記のうまく行かなかった Model 作成ですが、多少改善しました。
まず、未解決としていた理由は以下の二つの事象が見られたからです。
BonsaiNN の self.l1, self.l2 の重み付け weight と バイアス bias の訓練前後で値が変化していなかった or 変化がほぼ無かった。(訓練効果がない?)
訓練済み Model が出力した推論値がどんな入力値でも一定。
この二つの事象より、訓練効果がない?訓練できないとこういう結果?と状況を把握できず、未解決としていました。
原因を知る
訓練データのサンプル数が少なかったため、訓練効果がない可能性がある
訓練データの centering がされていないので訓練データとして適していなかった
さらには
訓練済み Model のテストコードでの誤り
という凡ミスも重なっていた。(<= これは恥ずかしい… orz)
Chainer のこの記事を参考としました。Chainer の Tutorial は日本語でも質が良いですね。とても分かりやすいです。(まだ全ての内容を理解するには至っていないですが)
改善した
サンプル数は 136本あった weight_gram の下り傾向のデータを分解し切り出し、サンプル数を増やすことに成功。136 -> 8994
(これでも少ないですが。。。)
次に、centering するために、train_data 各種値から列毎の平均値を引いた。
ただし timestamp_diff としていたデータ取得間の秒数は centering とは相性が悪いようなので、重さの変化を1秒間での変化とした。
わかりづらいので改めると以下です。
気温T, 湿度H, 環境光 L 下における、1 秒経過する毎の weight_gram の変化量 => Centering
となります。以下データ。
Centering 前
len = 8994
data = weight_gram env_temperature env_humidity env_light
0 0.001795 24.387161 34.203862 270.5
1 0.003533 24.401848 34.017700 274.0
2 -0.003561 24.584763 35.152208 276.5
3 0.007910 24.726288 35.676355 276.0
4 0.002418 24.451248 36.952772 277.5
... ... ... ... ...
8989 -0.001587 24.329746 46.346988 0.0
8990 0.003056 23.739601 50.853741 0.0
8991 0.001406 23.704887 52.680247 0.0
8992 0.001130 23.499275 51.452660 0.0
8993 -0.001169 23.288322 50.849165 0.0
[8994 rows x 4 columns]Centering 後
train_df_tmp: weight_gram env_temperature env_humidity env_light
0 0.001476 2.495317 -10.111614 -291.206916
1 0.003215 2.510004 -10.297776 -287.706916
2 -0.003879 2.692919 -9.163268 -285.206916
3 0.007591 2.834444 -8.639120 -285.706916
4 0.002100 2.559405 -7.362703 -284.206916
... ... ... ... ...
8989 -0.001905 2.437903 2.031513 -561.706916
8990 0.002738 1.847758 6.538265 -561.706916
8991 0.001087 1.813044 8.364771 -561.706916
8992 0.000812 1.607431 7.137184 -561.706916
8993 -0.001487 1.396479 6.533689 -561.706916weight_gram は1秒間に 0.001476[g] 減る、という内容になってます。
このデータを使って訓練するBonsaiNN Model は入力は 4 (timestamp_diff, temperature, humidity, light) としていましたが 3 (temperature, humidity, light) と変更になりました。
(Chainer の記事にもあるような bias の重みとして 1 を入力に追加する、という手法を取った方が良いのか、判断付かず。一旦 入力データは 3 としてます。)
ここまでで epoch や lr などを調整しつつ、訓練し、出力されるデータはどうなったのか? 正解と推論の誤差で色をつけています。
正解

に対して推論値は
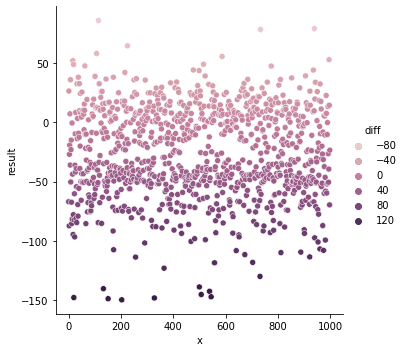
全然ですね。。精度を出すのは難しい。
一歩進めたので良しとします。
次回は
どう進めるか?
候補(仮)としては
今回の Dataset や Model を SageMaker 上へ移行させる
PreProcess をどこで行う? Processing Job? IoT Analytics は?
SageMaker での運用に乗せてみたい
試験的な使用の 温度湿度センサー、環境光センサーの実用化
など、次に進めたいと思います。