
ML on SageMaker

jun-fu@bitengineers です。
盆栽は今月も成長著しく、芽が芽吹き、花も咲きました。第一陣は既に花びらが散り始め第二陣が開き始めてます。盆栽始めて3年目の春ですが、新しい気づきが多く楽しいですね。


この時期取れるデータは貴重だと思います。何かに使えるデータだといいんでけどね。。。ということでデータの解析まわりを書いていきます。
AWS SageMaker を使った Machine Learning 環境の構築を書いてます。今回は大まかな流れを中心にしてます。
AWS SageMaker
以前に AWS Edukit のチュートリアルを試した時に SageMaker を使用しました。あれから半年以上経ちましたが、仕切り直します。今回は Document を読むところから進めます。
Overview
一般に普及・充実している Machine Learning 用の library が使える事に加え、AWS を使うとクラウドの利点を活かしオンデマンドに処理可能で、 Training/Test データの分散化、モデル作成、デプロイ、後のスケーリングなどと開発〜運用まで一環した恩恵を得られるようになるようです。
エンジニア以外の人にも ML インフラストラクチャーを提供してくれるようです。
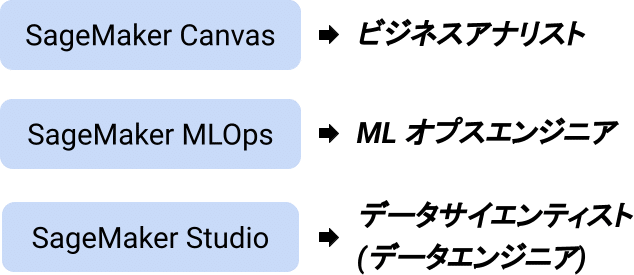
一見すると機能が多くてどれを使えば良いのかわからない印象でしたが、上記のように対象としている人を分けるとわかりやすいです。
ユースケースに応じたビルド済みモデルを使用するソリューション(JumpStart という機能) を数クリックで行えたり、自前のデータを使って独自のモデル作成するマネージド Jupyter Notebook の提供など、システム開発の上流から下流まで使えるツールを一挙にまとめた感があります。
ビルド済みモデル列挙
以上、SageMaker のぱっと見わかる特徴を掻い摘んで取り上げました。
モデル作成後の改善などの運用まわりは経験していないのでわかりませんが、一度 SageMaker の提供する Workflow を経験しておくといいのかも?
次からもう少し詳細へ入って行きます。
ML Framework
Python ML Framework が pytorch, tensorflow, scikit-learn, …etc から選択できます。
SageMaker Abstraction
複数の ML Framework をラップしているのでより上位層に新しい抽象化を導入しています。
Estimators
training をカプセル化したもの
Models
build されたML modelsをカプセル化したもの
Predictors
Endpoint に対して python のデータ型を使ったリアルタイム推論と変換を提供する
Session
SageMaker リソースを扱う際の処理集を提供
Transformers
SageMaker 上での推論のためのバッチ変換処理のカプセル化
Processors
SageMaker 上でのデータ処理のための処理実行のカプセル化
これらの抽象化したコンポーネントを組むことで ML が SageMaker 上に実現されます。
Local Mode
Local Mode もあるので開発時は課金を気にせず使える(?)ようです。こちらは AWS の Instance の代わりに Docker で動作します。
SageMaker の使い方
開発環境
私はエンジニア枠なので AWSサービスの想定では SageMaker Studio が該当する機能になりますが、裏で何をしているかいまいちわからなかったので今回は Local 環境に Notebook を立ち上げて進めます。
sagemaker 上に Notebook Instance を立ち上げる場合はこちら。
Local 環境の Notebook で開発したコードを後に SageMaker Notebook Instance 上で使いたくなった場合も Repository を追加することで同じように動作させられます。(sdk 作りでもそうですけど、ファイルなどはlocal 環境に依存しないようにs3 などを利用することを前提としてます)
SageMaker PyTorch
次に、 PyTorch を使った場合について。
ドキュメントが初見では情報が多すぎてわからないですが、流れとしては
training script を用意する
Estimator に training script を指定しインスタンス化。Estimator.fit を実行
training された estimator を deploy。preditor が返される。
predictor.predict を実行することで推論結果を得る
となります。
分かりづらい点として Estimator.fit を呼び出すと AWS では training_job が実行され、deploy を実行すると endpoint が作成されます。課金は注意したほうがいいかもしれないですね。
以下 Python コードレベルで。
session & role
実行権限や [Local] Session まわりで Error が起こったので以下のようにハンドリングしています。"ml.m5.large" は安めのものを選択した例です。
import boto3
import sagemaker
from sagemaker import get_execution_role
from sagemaker.local import LocalSession
LOCAL = False
if LOCAL:
session = LocalSession()
session.config = {'local': {'local_code': True}}
instance_type = "local"
else:
session = sagemaker.Session()
instance_type = "ml.m5.large"
try:
role = get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='AmazonSageMaker-ExecutionRole-***********')['Role']['Arn']session や role は節々に使用することになります。
training script
training script が実行されることで、model 定義からtraining済みの model file が作られます。この実行環境は隠蔽されておりどの環境でも同じように実行されるように引数が決めらている/られるようです。
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--model-dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
parser.add_argument("--train", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
parser.add_argument("--test", type=str, default=os.environ.get("SM_CHANNEL_TEST"))
parser.add_argument("--train-file", type=str, default="s3://be-bonsai/train/train.csv")
parser.add_argument("--test-file", type=str, default="s3://be-bonsai/train/test.csv")
args, _ = parser.parse_known_args()
...
train(args)のように引数をパースして受け取る処理を記述します。training 後 model をファイルに保存します。
# ... train `model`, then save it to `model_dir`
with open(os.path.join(args.model_dir, 'model.pth'), 'wb') as f:
torch.save(model.state_dict(), f)model_dir は引数で渡ってくるものを使うようです。
この training script は estimator から実行されます。
estimator
trainig script を "model.py" だとすると
from sagemaker.pytorch import PyTorch
estimator = PyTorch(
entry_point = "model.py",
role=role,
framework_version="1.7.1",
py_version="py3",
instance_count=1,
instance_type=instance_type,
)
estimator.fit({
"train": "s3://any_bucket/train.csv",
"test": "s3://any_bucket/test.csv",
})と作成し fit を呼び出します。trainig script が実行され保存された model file が tar.gz に固められ s3 の所定の場所に配置されます。
処理後、deploy をして predictor を取得します。
predictor
predictor = estimator.deploy(initial_instance_count=1, instance_type=instance_type)ここで estimator.fit で model file が正しく配置されていないと deploy は404 Not Found で失敗します。
session.upload_data で任意の場所に配置できますがしっかり理解しないうちはハマるので止めた方がいいでしょう。(ドハマりしましたw)
predictor.predict(data)で endpoint に引数と共に呼び出しが行われ推論結果が得られます。
おわりに
今回はここまでです。ここまで来るのに苦戦してしまい思った以上の時間を費やしてしまいました。ここで書いたのは数ある利用方法の一つです。
自分で training した model file をendpointに使用する、やGPUインスタンス上で(elastic inference)使う場合、などドキュメントを読めばもっと有力な情報が載ってます。
私はMachine Learningについては経験浅いので、自前のデータを使って推論を行う前に、何が推論結果として導きたいのか、どんなデータがあれば良いのか、再考する必要性を感じました。
実行基盤としては何かしら構築できそうなのでこれからつめていきたいと思います。