
Python,Tweepy,AWS,Googleスプレッドシートを使って、自動フォロワーログを作成してみた ~創価企業Twitter社の言論弾圧に対抗する~

■イントロ
こんにちは。びりぶです。
この世の悪の根源が創価学会と暴かれてから、創価関連企業が言論弾圧を力づくで行っています。
例1:創価企業のGoogle検索で創価の悪事が検索できない
Googleが創価企業と分かったので、改めてGoogleで「池田大作」と検索。
— 時計仕掛けのオレンジ (@9n7eWQtutsamatw) July 10, 2020
一方、今話題のDuckDuckGoでも「池田大作」と検索。
その結果を見れば、どちらがより正確な情報を提供してくれるか、一目瞭然である。
google→池田大作は偉大。現在も生存。
DuckDuckGo→池田大作は韓国人。既に死亡。 https://t.co/Sny24zeWfk pic.twitter.com/LsbKsirZhG
「池田大作」や「創価学会 犯罪」をGoogleとDuckDuckGoで検索した結果を比較すると、全然違う内容が出てきます。明らかに、Google検索では創価学会に関する検索が制限、誤誘導されるようになっているようです。
例2:wikipediaで創価学会の情報が削除される
Wikipediaに記載されていた創価学会USAの主要子会社情報が消されている。
— god_bless_you_ (@god_bless_you_) October 1, 2020
Twitter 20%
オラクル 12.7%
Wikipediaも創価。https://t.co/4gZbisqjJX
イルミナティにとって都合の悪い情報を隠そうと試みるも、悪事は必ず白日の元に晒される。#Twitterは創価企業 https://t.co/ETEs9t4fUX pic.twitter.com/gv1EVII97Z
wikipediaも創価学会の関連という事が暴かれています。創価に都合の悪い情報を次々を削除しているようです。
例3:Twitter社によるフォロワー減らし
悪徳創価企業Twitterが、今日もまた私のフォロワー数を7197人から、7190人に減らしました。
— 時計仕掛けのオレンジ (@9n7eWQtutsamatw) September 12, 2020
しかも、ほんの三時間ぐらいの間です。
もはや嫌がらせのレベルに入りました。
だから、私も嫌がらせで、これからはこのハッシュタグで拡散しようと思います。#Twitterは創価企業 https://t.co/2OrO02bfKJ pic.twitter.com/XRfO6njDSB
時計仕掛けのオレンジ氏は、創価学会の悪事を暴くなど、精力的に活動されています。創価企業のTwitter社にとって、その存在が目障りなのか、フォロワー数を減らす力づくで言論弾圧を行っています。
これらの創価学会関連企業の言論弾圧に対抗するため、自動でフォロワーログ機能を作ってみたので、コードを載せておきます。
--◇この記事を読むとできること
①AWS Lambdaによる定期イベント実行
②Tweepyによるフォロワ数取得
③Googleスプレッドシートによるログ保存
--◇環境
・python 3.7
・windows 10
・tweepy 3.8.0
・google-auth-oauthlib 0.4.1
・gspread 3.6.0
・AWS
・Googleスプレッドシート
--◇この記事を書いた人
・pythonは触ったことがあり、基本構文はわかる
・AWS、Googleスプレッドシートは初めてトライ
■全体構成と手順
全体の流れです。

①AWS LambdaのCloudWatch Events機能により定期イベントトリガ発生
②AWS Lambda内で作成した関数(pythonコード)を実行
③pythonコード内でTweepyを起動し、フォロワー数取得
④pythonコード内でGoogleスプレッドシートを呼び出し、取得したフォロワー数を追記記録
*)本当は、AWS Lambdaで定期イベント、AWS Lambdaでコード実行、AWSのE3に記録保存、をしたかったのですが、S3のところの書き込み設定がうまくいかなかったこと、S3は使用料が多少発生することから、記録だけGoogleスプレッドシートにする方法にしました。(AWSだけでクローズしたいい実例があれば、教えてください^^;)
**)AWS Lambda の無料利用枠には、1 か月ごとに 100 万件の無料リクエスト、および 40 万 GB-秒のコンピューティング時間が含まれているので、実質無料で使用できます。(2020/10/11現在)
例えば、128MBのメモリを使用し、1時間に1回フォロワー数を記録する機能を使った場合、
128MB×24回/日×30日×10秒=約950GB
となり、40万GBまでだいぶ余裕があります。
https://aws.amazon.com/jp/lambda/pricing/
■コードの説明
--①AWS LambdaのCloudWatch Events機能により定期イベントトリガ発生
基本的には、以下のページを参考に作成しています。
https://qiita.com/macaroni10y/items/373f5451c93b824b30fe
1.AWS登録(省略)
2.Lambda関数作成

関数を1から作成にして、「関数の作成」を押します。関数名は任意でつけてください。ランタイムはpython3.7にしました。
3.トリガーの追加・設定
関数が作成されたら以下の画面になるので、トリガーを追加します。

ここでトリガーの設定を行います。
EventBridege(CloudWatch Events)というのがあるので、それを選択し、新規ルールの作成、適当なルール名を付けて以下のような設定にします。
今回、ルールタイプはスケジュール方式とし、rate(1day)としています。もっと細かい間隔、曜日指定もできるようです。
rateの細かい設定方法:https://www.suzu6.net/posts/136-lambda-cron-rate/
動作確認できるまでは、トリガーの有効化は一旦チェックを外しておいたほうがいいかもしれません。最後に、追加ボタンを押してトリガーの設定は完了です。
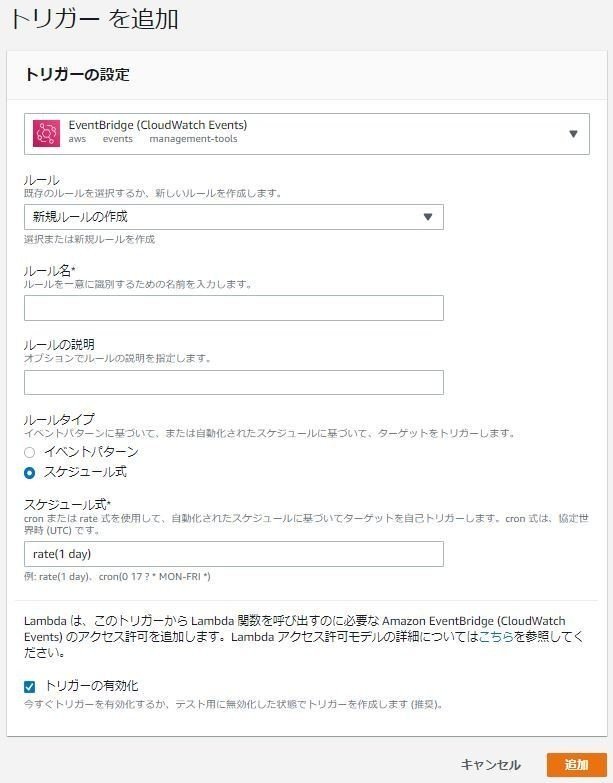
デザイナーの画面でトリガーが追加されていることを確認します。

--②AWS Lambda内で作成した関数(pythonコード)を実行
Lambda内でpythonコードを実行するにあたって、少し癖がありますので、注意してください。
・基本設定
・モジュール設定(Layers)
・pythonプログラム、JSONファイルのアップロード
・基本設定
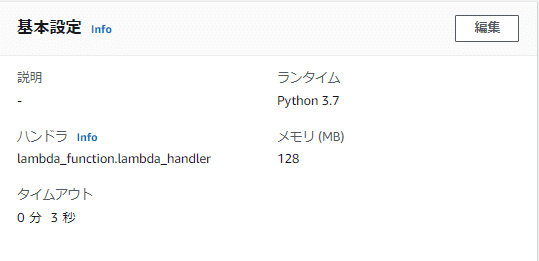
Lambdaの下のほうを見てみると、基本設定があるので、編集ボタンを押して編集します。
基本的には、何も変更せず、基本設定のままでOKです。ただし、ハンドラ名と実行するpythonファイルの名前は同じにして下さい。あとはオプションですが、Googleスプレッドシートとのやり取りに時間がかかるので、タイムアウトは10秒以上に設定することをお勧めします。

・モジュール設定(Layers)
Layersボタンを押して、pythonプログラムで使用するモジュールの設定を行います。


レイヤーの追加を押すと以下の画面になるので、
AWSレイヤー ⇒ AWSLambda-python37...
を追加します。
これでpandasやnumpyが使えるようになるはずです。(今回は未使用ですが)


Layersが1つ追加されていることがわかります。
次に、同様に、その他のモジュールをLayersに追加します。
今回は、gspread、oauth2client、tweepyを追加します。手順は同じなのでgspreadで説明します。
まず、自分のPC上で「python」というディレクトリを作り、そこにモジュールを(targetで)インストールします。なぜか「python」というディレクトリでないとうまくいかなかったので、pythonディレクトリを作成しています。最後に、7-ZIPなどでzip化します。
以下を参照。
https://www.suzu6.net/posts/83-lambda-zip/
https://gawatari.com/lambda-paramiko/
$ cd [実行ファイルのディレクトリ]
$ pip install gspread -t ./pythonその後、zipファイルをLambdaにアップロードします。
左上の3本マークを押すと「レイヤー」が出てくるので、レイヤーの作成ボタンを押します。

レイヤーの作成画面では、名前(例. gspread など)、説明、ランタイム(python3.7)などを適当に入力します。「zipファイルをアップロード」のボタンを押し、先ほど作成したpython.zipをアップロードします。

そうすると、Layersの追加画面の「カスタムレイヤー」で新しく追加したレイヤーが選択できるようになるので、それを追加します。
同様の手順で、google-auth-oauthlib、tweepyも追加し、レイヤー(モジュール)の設定は完了です。
AWSレイヤーも含め、追加されたレイヤーは4つになっているはずです。

・pythonプログラム、JSONファイルのアップロード
pythonプログラムとJSONファイルのアップロードは、関数コード⇒アクション⇒zipファイルのアップロードで行えます。
ただし、初期設定で出来ているlambda_function.pyをコピペで、直接書き換えても、差支えありません。
また、
pythonファイル名と、基本設定のハンドラ名の前半
コード本文の関数名と、基本設定のハンドラ名の後半
は同じにしないといけないことに注意して下さい。
コード実行時は、def lambda_handlerの部分が実行されることになります。

また、関数ディレクトリ直下にtmpディレクトリを作成する必要があることにも注意して下さい。
今回、Googleスプレッドシートにフォロワー数の情報を記録しますが、その際、Googleスプレッドシートにアクセスするためのサービスアカウントキー(JSONファイル)を読み込む必要があります。そのJSONファイルを読み込めるようにするため、tmpディレクトリ直下(ディレクトリ名は必ず、tmp)にJSONファイルを置きました。なぜか、Lambdaでは、tmpディレクトリ直下のファイルしか読み込むことができない仕様になっているようなので。
以下参照
https://rioner2525.hatenablog.com/entry/2019/07/25/185907
ここで、JSONファイルをzipでアップロードすると、作成したlambda_function.pyもtmpディレクトリも消えてしまうので、手順としては以下のように行うといいと思います。
1.JSONファイルのアップロード
2.tmpディレクトリ作成
3.tmpディレクトリにJSONファイルを移動
4.lambda_function.pyを作成、編集
以下の絵のようになっていればOKです。
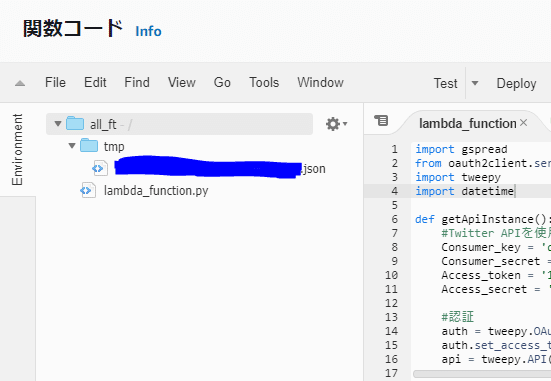
(注意:セキュリティの観点からすると、AWS上にサービスアカウントキーを置くのはどうなの?という意見もあると思いますので、各自の責任の上、実施して下さい。)
--③pythonコード内でTweepyを起動し、フォロワー数取得、④pythonコード内でGoogleスプレッドシートを呼び出し、取得したフォロワー数を追記記録
ここでは、Lambdaにアップしたpythonコードについて、説明します。
コードは大きく
1.Tweepy認証
2.フォロワー数取得
3.Googleスプレッドへ記録
4.lambda実行本文
から構成されています。
1.Tweepy認証
def getApiInstance():
Consumer_key = '**取得したキーを入力*'
Consumer_secret = '**取得したキーを入力*'
Access_token = '**取得したキーを入力*'
Access_secret = '**取得したキーを入力*'
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth ,wait_on_rate_limit = True, wait_on_rate_limit_notify=True)
return apiTweepyのアカウント取得及び、認証の方法に関しては、以下の記事に記載しているので参考にして下さい。
https://note.com/believe2023/n/n7144b091d04c?magazine_key=m3feef596c05b#PCNfr
2.フォロワー数取得
def tweet_follower():
api = getApiInstance()
screen_name1 = "フォロワモニタしたいアカウント1のscreen_name"
screen_name2 = "フォロワモニタしたいアカウント2のscreen_name"
screen_name3 = "フォロワモニタしたいアカウント3のscreen_name"
screen_name4 = "フォロワモニタしたいアカウント4のscreen_name"
screen_name5 = "フォロワモニタしたいアカウント5のscreen_name"
names = [screen_name1,screen_name2,screen_name3,screen_name4,screen_name5]
flist=[]
dt_now = datetime.datetime.now() + datetime.timedelta(hours=9)
tt=dt_now.strftime('%Y-%m-%d %H:%M:%S')
flist.append(tt)
for name in names:
user = api.get_user(screen_name=name)
flist.append(user.followers_count)
return flistapi = getApiInstance()でTweepyの認証を行っています。
screen_name1~namesで、フォロワ数をモニタしたいアカウントのscreen_nameを定義しています。今回5人まで、モニタ出来るようにしています。
dt_now~flist.append(tt)で、実行した時刻を取得して空のflistの配列(1列目)に追加しています。
for name in names:で各アカウント名ごとに、フォロワ数を取得しています。user.followers_countで、特定ユーザのフォロワ数を取得することができます。appendでflistの配列(2~6列目)に追加しています。
APIの使い方は以下を参照。
https://kurozumi.github.io/tweepy/api.html
最後に、作成したflistの配列を戻しています。
3.Googleスプレッドシートへ記録
def gc_update(flist):
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('tmp/'+'**jsonファイル名*.json', scope)
gc = gspread.authorize(credentials)
wks = gc.open('log_test').sheet1
values1=wks.get_all_values()
lastrow1 = len(values1)
update_range='A'+str(lastrow1+1)+':'+'F'+str(lastrow1+1)
cell_list = wks.range(update_range)
for m, cell in enumerate(cell_list, 0):
cell.value = flist[m]
wks.update_cells(cell_list)Googleスプレッドシートの作成、設定方法の大きな流れは以下の通りです。
以下を参照下さい。
https://qiita.com/akabei/items/0eac37cb852ad476c6b9
[1]Googleアカウント作成
[2]プロジェクトの作成
[3]Google Drive APIを有効
[4]Google Sheets APIを有効
[5]サービスアカウントキー作成(JSONファイルで)
[6]スプレッドシート作成・共有
(ユーザのメアドは、JSONファイルの「client_email」の値を貼り付け)
コードについて説明します。
scopeを設定します。以下参照のように、いろいろあるようですが、feedsとdriveを設定しました。
https://developers.google.com/identity/protocols/oauth2/scopes
credentials~:tmpディレクトリに保存したJSONファイルを読み込みます。
wks = gc.open('log_test').sheet1で、作成したlog_testというファイルのsheet1を開いています。
values1=wks.get_all_values()でシートのすべての情報を読み込み、lastrow1 = len(values1)で最終行数を取得しています。
update_range='A'+str(lastrow1+1)+':'+'F'+str(lastrow1+1)で、最終行のA~F列をアップデートする範囲として選択。
for文内のcell.value = flist[m]で、取得したフォロワ数の配列(1列目:時刻、2~6列目:各アカウントのふぉろふぁすう)を、セルの値として入力。
wks.update_cells(cell_list)で、そのセルを書き込んで完了。
4.lambda実行本文
def lambda_handler(event, context):
flist = tweet_follower()
gc_update(flist)lambdaで実行するコードの本体部分です。lambdaでは、def lambda_handlerの部分が実行されます。
flist = tweet_follower()で、フォロワ数を取得。
gc_update(flist)で、Googleスプレッドシートに書き込んでいます。
--コード全体
import gspread
from oauth2client.service_account import ServiceAccountCredentials
import tweepy
import datetime
def getApiInstance():
Consumer_key = '**取得したキーを入力*'
Consumer_secret = '**取得したキーを入力*'
Access_token = '**取得したキーを入力*'
Access_secret = '**取得したキーを入力*'
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth ,wait_on_rate_limit = True, wait_on_rate_limit_notify=True)
return api
def gc_update(flist):
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('tmp/'+'**jsonファイル名*.json', scope)
gc = gspread.authorize(credentials)
wks = gc.open('log_test').sheet1
values1=wks.get_all_values()
lastrow1 = len(values1)
update_range='A'+str(lastrow1+1)+':'+'F'+str(lastrow1+1)
cell_list = wks.range(update_range)
for m, cell in enumerate(cell_list, 0):
cell.value = flist[m]
wks.update_cells(cell_list)
def tweet_follower():
api = getApiInstance()
screen_name1 = "フォロワモニタしたいアカウント1のscreen_name"
screen_name2 = "フォロワモニタしたいアカウント2のscreen_name"
screen_name3 = "フォロワモニタしたいアカウント3のscreen_name"
screen_name4 = "フォロワモニタしたいアカウント4のscreen_name"
screen_name5 = "フォロワモニタしたいアカウント5のscreen_name"
names = [screen_name1,screen_name2,screen_name3,screen_name4,screen_name5]
flist=[]
dt_now = datetime.datetime.now() + datetime.timedelta(hours=9)
tt=dt_now.strftime('%Y-%m-%d %H:%M:%S')
flist.append(tt)
for name in names:
user = api.get_user(screen_name=name)
flist.append(user.followers_count)
return flist
def lambda_handler(event, context):
flist = tweet_follower()
gc_update(flist)■実行結果
・動作確認
動作確認を行います。Lambda関数トップ画面の右上にテストボタンがあるので押します。最初はテストイベントの設定画面が開かれますが、最初から入っている{key1:value1,key2:value2,key3:value3}を実行すれば、動作します。
動作後エラーがなければ、以下の画面のように「実行結果:成功」と表示されます。実際に、Googleスプレッドシートを確認すると最終行に1行追加されていればOKです。
最後に、イベントトリガーを有効にして完了です。


・実行結果
以下に、1時間に1回のイベントトリガで実施した結果を示します。

1列目に時刻、2~6列目に各アカウントのフォロワー数が保存されています。
Googleスプレッドシート上またはコピペして表計算ソフトなどでグラフを表示させれば、時系列の変化がわかります。
■活用結果
この機能を運用し始めてすぐに、活用する機会がありました。
「時計仕掛けのオレンジ」氏は、ラプト理論を精力的に拡散されている方です。創価企業のTwitter社は、ラプト理論が拡散されないよう、創価学会の悪事が拡散されないよう、真実が広がらないよう、オレンジ氏のフォロワー数を定期的に減らす言論弾圧を行っています。
その悪事を明らかにするために、今回試作した機能を使い、オレンジ氏のフォロワー数をモニタリングしました。
実際にこのコードで記録した結果が以下になります。

そして、以下がそれに対する指摘ツイートです。
悪徳創価企業Twitter社のフォロワ減らしがひどい。
— びりぶ (@believe2023) September 13, 2020
オレンジ氏の創価に関する核心ツイートの度に
フォロワ数を減少。
しかも、バレないよう深夜に減らすのが多い様子。
トレンドで核心がわかります。
墓穴ですね。
最後は、減らす数より増数のほうが多い。
やはり悪は滅びる。#Twitterは創価企業 https://t.co/OqmzsAQDkL pic.twitter.com/kQRTEJ68eB
オレンジ氏が創価企業に対する核心ツイートを行う度に、フォロワー数を減らしていることがわかります。しかも、バレないよう深夜に減らすことが多い様子。最後は、減る数よりも増える数のほうが多く、オレンジ氏のフォロワー減らしに対する指摘に対し、慌ててフォロワー数を回復させている様子です。
このように、この機能を使うことで、隙があれば言論弾圧をしてくる創価企業に、少しだけ対抗できるようになりました。
■最後に
Python,Tweepy,AWS,Googleを活用して、自動フォロワーログ機能を試作してみました。少し回りくどいやり方ですが、それぞれの機能を使ういい練習になりました。この機能を応用すれば、BOT運用などいろいろ活用できそうです。
この世は多くのウソと間違った常識であふれています。だから、こんなにも混沌としているのです。
「コロナはウソ」
「原発・原爆・放射能はウソ」
「ガンはウソ」
「拉致問題はウソ」
「LGBTは気持ち悪い」
「天皇は悪魔崇拝」
「この世を統治する悪徳企業は創価学会と繋がっている」
などなど、他にもたくさんあります。
まずは、ウソをウソと知ることができるだけでも、不安や心配や悩みがなくなり、平穏の中で生きていけるようになります。
ラプト理論を知れば、ウソと真実がわかり、希望をもって生きていくことができるようになります。
ラプト理論を知って、真実の世界を覗いてみませんか?
昨今の、コロナのウソ(もうバレバレすぎて笑えるレベルですが)により、多くの人が真実を知り、ラプト理論にたどり着いています、真実にたどり着いています。
今ならまだ間に合います。一緒に真実を知りませんか?
ラプト理論を知れば、真実が見えてきます。世の中の真実だけでなく、何のために産まれたのか、幸せとは何なのか、という人生の答えも見えてきます。
この記事を読んで頂いた多くの人が、ラプト理論に導かれることを祈っています。
最後まで、お読み頂きありがとうございました。
■おすすめサイト
・RAPTブログ
http://rapt-neo.com/?page_id=1815
・KAWATAのブログ
http://kawata2018.com/
・RAPT氏インスタ
https://www.instagram.com/rapt_neo/?hl=ja
・KAWATAさんインスタ
https://www.instagram.com/kawata02/?hl=ja
・NANAさんインスタ
https://www.instagram.com/nana2012227/?hl=ja
・時計仕掛けのオレンジ氏Twitter
https://twitter.com/9n7eWQtutsamatw