
ベクトル?をシュッと理解する

LLM 楽しいですよね。
OpenAI + LangChain でシュッとアプリ作れる。
ちょっと慣れてくると llamaIndex とかを使ってデータを先に保存しておいてそれを検索できるようにもなる。
そう、Vector DB。
キャッキャ(*´▽`*)
なんかわからんけど動く、、、動くぞ、、、
でも?
どういう仕組みかはわからん。
なんか動いとる。
という方も結構いらっしゃる印象。
勤務先でもとりわけエンジニア以外の職種の人とかはそんな感じが多いかしら。
世の中に情報はたくさんあって調べればわかるのだけれど、時間ないので触りだけシュッと理解したい方向けの記事はそんなない気がしたので書いてみようかなと。
※先にエクスキューズ
自分は Deep Learning をお勉強初めて2週間くらいの雑魚なので変なこと言ってたらごめんなさい。。。
と、保険を掛けたうえでシュッと書いていきます。
ChatGPT4 + Wolfram に助けられながらやっていく。
簡潔に言おう
要するに無理やり?すべての物を数値座標に変換したものである。
そも、ベクトルとは?
ベクトルは、方向と大きさを持つ量を表現するための数学的なツール。
物理学では、速度や力などを表現するためによく使われる。
しかし、ベクトルは物理的な現象だけでなく、様々な特徴を持つ物事を表現するためにも使うことができるのだ。
ふむ。つまり?
ChatGPT 先生に分かりやすい例を作ってもらったよ
全てはスムージー
「果物のベクトル」を考えてみましょう。
まず、りんごとバナナを考えてみましょう。これらの果物は色々な特徴を持っています。例えば、甘さ、酸っぱさ、硬さなどです。これらの特徴を数値で表現すると、りんごとバナナはそれぞれ異なるベクトルを持つことになります。
りんごのベクトルを りんご=[4,3,2]りんご=[4,3,2] とし、バナナのベクトルを バナナ=[5,1,4]バナナ=[5,1,4] としましょう。ここで、各成分はそれぞれ甘さ、酸っぱさ、硬さを表しています。
これらのベクトルを足し合わせると、新しい果物の特徴を表すベクトルを作ることができます。例えば、りんごとバナナを混ぜ合わせたスムージーの特徴は、りんごとバナナのベクトルを足し合わせることで表現することができます。
スムージー=りんご+バナナ=[4,3,2]+[5,1,4]=[9,4,6]
このように、ベクトルを使って物事の特徴を表現し、それらを足し引きすることで新しい特徴を作り出すことができます。これは、ベクトルが持つ最も強力な特性の一つです。
以下の図は、りんご、バナナ、そしてそれらを混ぜ合わせたスムージーの特徴をベクトルで表現したものです。ベクトルの始点は原点(0,0)で、終点は各果物の特徴を表す点です。りんご、バナナ、スムージーのベクトルはそれぞれ異なる方向と長さを持ち、これが各果物の特徴を表しています。
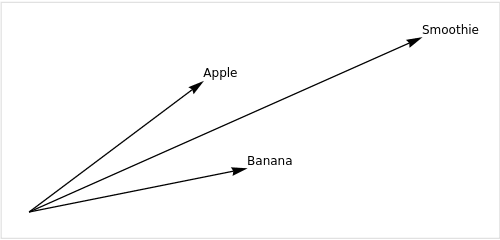
なんてわかりやすいんだ、、、
ありがとう ChatGPT 先生。
とりあえず簡単な理解はここまででいい気がします。
ここからは特に読まなくていいかな?
スムージーでイメージついたと思うのですが、いや、どうやって特徴を数値表現するねん?ってなる人いますよね。
はい。そうですね。
ベクトルは方向と大きさを持つため、物事の特徴を表現するのに適しているので、量的な特性を持つ物事を表現するのはいいけど、質的な特性を持つ物事を表現するのは難しい。
つまり?
ChatGPT 先生頼む。
例えば、色を考えてみましょう。色は質的な特性ですが、RGB(赤、緑、青)の3つの成分に分けることで量的に表現することができます。赤、緑、青の各成分は0から255の値を取り、これにより16,777,216色を表現することができます。このように、色をRGBの3つの成分に分けることで、色を3次元のベクトルで表現することができます。
わかりやすい。
質的な特性をベクトルで表現するためにカテゴリーに分け、それぞれのカテゴリーに数値を割り当てることを「エンコーディング」と呼びます。
なるほど。
また、自然言語処理の分野では、単語や文章をベクトルで表現する手法が開発されています。これらの手法は「ワードエンベッディング (Word Embedding)」や「文書エンベッディング Document Embedding」と呼ばれ、単語や文章の意味を多次元のベクトルで表現します。これにより、単語や文章の間の類似性を計算したり、単語や文章を足し引きすることで新しい意味を作り出すことが可能になります。
Embedding、、、どこかで聞いたことありますよね?
これすなわち
単語や文章を多次元のベクトル空間にマッピングする手法
要するに言葉も無理やり?数値に変換することで単語や文章の意味的な類似性を計算したり、単語や文章を足し引きすることで新しい意味を作り出すことが可能になるわけですね。
イエス、スムージー。
ベクトル表現しにくい奴もあるのよ
順序情報: ベクトルは単語や文章の順序情報を直接的には捉えられません。たとえば、"cat chases dog"と"dog chases cat"は全く異なる意味を持ちますが、単純なワードエンベッディングではこれらの違いを表現するのは難しいです。
文法情報: 単数形と複数形、現在形と過去形みたいなやつ
文化的・社会的な情報: スラングやイディオム、比喩などはみたいなやつ
曖昧性: "bank"は「銀行」または「川岸」を意味する、、、みたいなやつ
じゃあどうするのよ?
これらの問題を解決するために、より高度な自然言語処理の手法が開発されています。たとえば、リカレントニューラルネットワーク(RNN)やトランスフォーマー(Transformer)などのモデルは、順序情報や文法情報を捉えることができます。また、大規模なコーパスを学習することで、文化的・社会的な情報や曖昧性をある程度捉えることが可能になってきています。
トランスフォーマー!!
(喋るロボットの話ではないです)
そこはかとなく聞いたことある単語ですよね?
今回は解説しませんが、こういうので諸々を頑張って意味を持たせつつ数値に情報を変換してる。
そういうこと。
Attention Is All You Need !!
今回はシュッと理解するのが目的なのでこれでおしまい。
気になる人はネット上に優良コンテンツがころがってるので調べてね。
個人的には AIcia さんの動画が超超超超わかりやすかったのでおすすめ。
では、ごきげんよう。