
note でエクスポートしたXMLをPythonで読みやすくしたい(その5)

さてさてさて。
こちらの続きです。
ほとんどデバッグの実況中継の様相を呈してきました(笑)。
(1)XMLファイルを読み込む
(2)読み込んだデータを木構造でアクセスする
(3)木構造の1Elementを1行で表示する
(4)noteのエクスポートファイルでテスト
(5)タグを置換
item → details
title → summary
その他 → li
前回やったのはここまで。
しかし。
出力されたhtmlファイルでは、
rss<br>が
rss<br>に変換されてしまう。
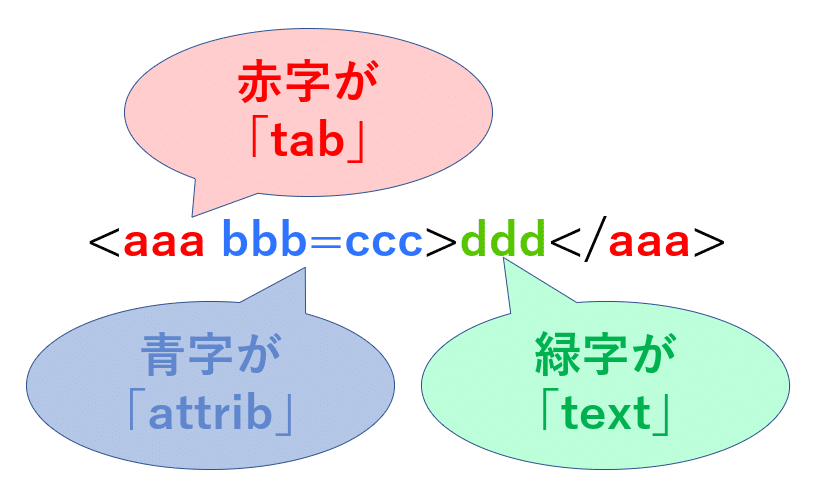
改めて「Element」を確認してみる。
「Element」は
tag
attrib
text
で構成されている。
それぞれをXMLから次のように読み込むようだ。
XMLとhtmlにとって、「<」や「>」という文字は重要だ。それを「tag」として認識しなければならない。だから「text」の中に「<」や「>」が出てくると困る。「a<b」のような数式が出てきたりなんかしたら、
「<b」はタグの始まりなのか?
などと悩まなければならなくなる。
なので、htmlの文章中に「<」や「>」を書きたければ「&lt;」や「&gt;」というおまじないにする。
そうしておけば、htmlがこのおまじないを
「<」を「<」に
「>」を「>」に置き換えて表示してくれる。
「Element」は、ご丁寧にも
「<」を「<」に
「>」を「>」に変換してhtmlファイルに出力してくれるわけだ。
rss<br>を
rss<br>には変換せずにそのまま出力してほしいのだけど、そんなことができるのか。
「text」内にタグは書けない。
だとするとどうするか。
「text」を「Element」に格上げしていまえばいいんじゃね?
そうそう、こんな関数があった。
xml.etree.ElementTree.XML(text, parser=None)
文字列定数で与えられた XML 断片を解析します。
文字列を入れるとXMLフォーマットで解析してくれるんじゃないか。
これを通してみよう。
sub_tree = ET.XML(el.text)怒られた。
xml.etree.ElementTree.ParseError: not well-formed (invalid token): line 1, column 3「invalid token」?
怒られたときの「text」はコレ。
rss<br>うーん。
修飾なしの文字列はダメかしら。
次のように変更してみる。
変更前
el.text = el.tag + '<br>' + el.text変更後
el.text = '<p>' + el.tag + '</p>' + el.text<br>ではなく、<p></p>にした。
結果は・・・。
<p>rss</p>
<p>channel</p>
<p>link</p>https://note.com/ayumi_kat
xml.etree.ElementTree.ParseError: not well-formed (invalid token): line 1, column 17あ。
ちょっと進んだ。
<p>link</p>https://note.com/ayumi_katこの行の「https://~」以降がダメのもよう。
さらに変更。
変更後
el.text = '<p>' + el.tag + '</p>' + '<p>' + el.text + '</p>'textも、<p></p>で挟んでみた。
<p>rss</p>
<p>channel</p>
<p>link</p><p>https://note.com/ayumi_kat</p>
xml.etree.ElementTree.ParseError: junk after document element: line 1, column 11え?
怒られるん?
タグ「<p>」を並べたらダメだっけ?
これならどうだ。
el.text = '<p>' + el.tag + '<br>' + el.text + '</p>'<p></p><p></p> でなく、
<p><br></p> にする。
<p>rss</p>
<p>channel</p>
<p>link<br>https://note.com/ayumi_kat</p>
xml.etree.ElementTree.ParseError: mismatched tag: line 1, column 39えーー。
これでもアカンのん?
うーん。
頭痛い。
とりあえず、先送りする(後で考える)。
el.text = '<p>' + el.tag + ' ' + el.text + '</p>'<p>~<br>~</p> を
<p>~ ~</p> にする。
先に進むには進んだが。
「noteの記事」で怒られるなぁ。
<p>{http://purl.org/rss/1.0/modules/content/}encoded <figure name="19f67ea2-e11d-4fdb-bd3b-a4902475b209"><img src="/assets/ne014d60a70d2_d818061a5bdc5d8c91375d88fa0d57f4.png"><figcaption></figcaption></figure><p name="fbf1a8d8-835a-4671-a74f-89214b9b82e8" id="fbf1a8d8-835a-4671-a74f-89214b9b82e8">こちらの 課題回答です。</p>
xml.etree.ElementTree.ParseError: mismatched tag: line 1, column 205記事を丸ごとタグ「<p>」で括っちゃったもんなぁ。
その弊害かなぁ。
それにしても「column 205」ってどこよ。
10カラムずつ区切ってみる。
<p>{http:/
/purl.org/
rss/1.0/mo
dules/cont
ent/}encoded <fig
ure name="
19f67ea2-e
11d-4fdb-b
d3b-a4902475b209"><i
mg src="/a
ssets/ne01
4d60a70d2_
d818061a5bdc5d8c9137
5d88fa0d57
f4.png"><f
igcaption>
</figcaption></figur
↑
このあたり<p>
{http://purl.org/rss/1.0/modules/content/}encoded
<figure name="19f67ea2-e11d-4fdb-bd3b-a4902475b209">
<img src="/assets/ne014d60a70d2_d818061a5bdc5d8c91375d88fa0d57f4.png">
<figcaption></figcaption>
</figure>ここの最後にある
</figure>
にあたるらしい。
ここが
「mismatched tag」
であると。
う~ん。
やな予感するけど。
タグって、もしかして、
<tag></tag>
のようにセットじゃないとイカンと言ってたりする?
ここのケースでは、
<img>
に対する
</img>
はないんだけどね。
試してみる。
XMLファイルで下記の「</img>」を追加した。
<img src="/assets/ne014d60a70d2_d818061a5bdc5d8c91375 d88fa0d57f4.png"></img>しかる後に実行すると・・・。
xml.etree.ElementTree.ParseError: mismatched tag: line 1, column 920さっきは
「column 205」
でエラーになっていたのが、今度は
「column 920」
になった。
先ほどの
「column 205」
のエラーは解決したことになる。
ということは
<img>
に対する
</img>
が必要である、ということか。
う~ん。
XMLでは無理かなぁ。
はてさて、どうするか。
(つづく)