
【AIあんの】~ポストモーテム大公開~ 障害の裏側、知見と反省点を共有します #安野たかひろ

本記事は「AIあんの」のサービス障害の理由や改善案などを纏めている、
多くの技術的用語を含む、ソフトウェアエンジニア向けの側面が多い記事となっております。
この選挙期間中、Youtubeでライブ配信を続けていた「AIあんの」はもうお試しになったでしょうか?
6月21日の19時から投票日前日まで、できる限り深夜でも絶え間なく安野たかひろの政策について答えるように作られた「AIあんの」でしたが、すべての時間で視聴者の皆様の質問に答えられたわけではありませんでした。

0%のタイミングではおおよそ何かしらのトラブルが起きていた…
障害の要因は多岐にわたるので、今回は得られた知見の多かった数回の障害について、あえてその裏側、要因、得られた知見を公開しようと思います。ソフトウェアエンジニア向けの言葉を用いて言うのであれば、これは都知事選史上初であると思われるポストモーテム記事です。実際に起きた事例のタイムラインを整理し、うまく行った点、上手くいかなかった点、そして最後に得られた知見をまとめて紹介していきます。
はじめに
私が「AIあんの」ライブ配信に協力し始めたのはリリースされる6/21の3日前の6/18でした。自分はAIやMLの部分はあまり分からないので、AIあんのを動かすUnityの部分を担当しました。参加した際には既に基本的に動く部分は出来ていたのですが、質問への回答の生成をシリアルに待機していたり、質問への回答待ちになっているかどうかがわからず、いつ回答されるかもわからないユーザ体験を改善すべくUI上の細かな変更を行いました。
通常の製品環境では、時間をかけてテスト、検証をして動作に自信を持ってから投入したいものですが、そのような時間もなかった今回の「AIあんの」ならではの障害もあり、どこまで参考になるかは不明ですがこの知見をどうぞご活用ください。
教訓1: 本番環境にはあらかじめ目を通しておくべき
一つ目のポストモーテムは、リリース初日にリリースが遅れたことに関してです。元々19時公開の予定が20時公開になりました。この間、何があったのか見ていきます。
「AIあんの」のライブ配信はWindows上で動くUnityで描画をしており、Unity内でPythonで書かれたサーバを呼び出しています。詳細は伊藤さんの記事(下記)がとても詳しいのでこちらをご参照ください。
タイムライン
私が実際の配信を行う安野たかひろの事務所のPCを最初に見たのはリリース予定30分前の18時半のことでした。Unity側の設定をすまし、OBSの設定も確認し、あとはPythonサーバだけうまく稼働すれば配信が開始できる状況ではありましたが、ここにきて依存関係が上手くインストールできないことに気が付きます。

配信用に利用しようとしていたPythonサーバが上手く起動しない
AI/ML 周りの開発を行っていた方はMac環境、私もWindows上でWSL経由で Pythonサーバを動かしていました。しかし、安野PCにインストールされていたPythonはWindows上に直接インストールされていたもので、一部の依存関係が互換性が無く正常に動作しなかったのです。
WSLを有効にして環境のセットアップをしても、せいぜいリリース予定より少しだけの遅延で公開できる見込みでした。しかし、WSLを有効にしようとした際に開発チームは「誰もこのPCの管理者パスワードを知らない」事に気が付きます。
リリース時間を1時間後ろ倒しにする決断をした後、仕方がないので開発チームの一人のPC上でPythonサーバを動かし、ngrokというプロキシ経由でUnity側からサーバにアクセスすることにし、無事1時間遅れで20時に「AIあんの」生配信をスタートすることができました。
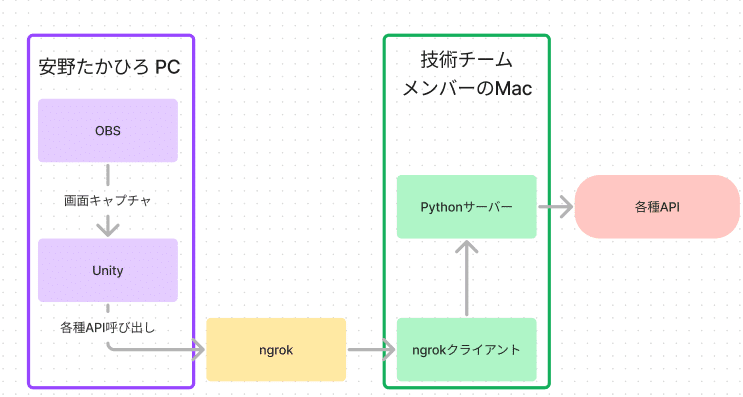
この影響により、技術チームの一人のPC上でPythonサーバを稼働させ続けなければならず、止まった場合に再開させることが一人を除いて難しくなることを考慮しこの日の配信は24時で一度停止し、翌日10時から開始する運びとなりました。この日のうちにPythonサーバをAzure上のVMで稼働させることが可能になり、翌日以降はPythonサーバを稼働させるために誰かのPCを占有する必要はなくなりました。
上手くいったこと・上手くいかなかったこと
咄嗟の判断でngrokを経由してサービスを稼働させることに成功したことは幸運でした。また、WSLをインストールするために管理者パスワードが分からなかったことも、結果的にはこれが起因でPythonサーバをAzure上で動かす方針となったので全体としてみたらうまくいったことであったと思います。
チームの能力が高く、ngrokで解決しようと決断した後はとても対応が高速でした。19時20分ほどにはngrok経由での配信が可能となっていましたが、既に20時スタートとアナウンスしてしまった後だったため、20時にリリースしました。リリース前から待機してくださっていた視聴者様もいる中で、もう少し早く準備に取り掛かっていたらngrokでの回避まで含めてリリースは予定時間に行えたかもしれない点は反省点でした。
得られた知見(まとめ)
実際に稼働させる本番環境を事前に確認するべき。
最悪の時に必要かもしれない管理者パスワードのようなものを、リリースメンバー全員が知らないという事態を防ぐべき。
教訓2:クラウドのリソースには間違えにくい名前をつけるべき
タイムライン
教訓1の対応終了後から、Azureへの移行を行うため、技術チームのメンバーのうち数人にAzureのアカウントを発行しました。22日の朝、無事「AIあんの」生配信をAzure上のVMで稼働するPythonサーバを用いて可能にしてから、念のためAzure上に存在していたVMの説明等が技術チーム内のビデオ会議で行われていました。
その中で、aituberという接頭辞のVMが2台存在し、「あれ、こっちのVMは何に使ってるんでしたっけ?」、「これはテスト用に使っていたやつですね」というやり取りの後、未使用のリソースとしてVMを削除しました。
2日ほど経過して、こんな連絡が来ることになります。

この時Azureのプロジェクトには「AIあんの」生配信と電話版「AIあんの」それぞれでVMを立てており、気が付かないうちに電話版「AIあんの」のサーバを技術チーム複数人が画面共有を見ている中消してしまい、電話版「AIあんの」に2日近いダウンタイムを作ってしまうことになりました。
「AIあんの」はもともとYoutube配信版しかなく、aituberというプロジェクト名で作成されていました。派生した電話版もyoutubeは関係ないにもかかわらず、「aituber」という単語が接頭辞に付加されており、配信版を開発していたチームの管理しているVMであり、おそらく昔作った何かであろうというように考えてしまい、間違えて消してしまうことに至ってしまったのです。
上手くいったこと・上手くいかなかったこと
消してしまった後、チームが優秀で1日もせずに「AIあんの」電話版は復旧できたことには安心しました。
一方、Azureのプロジェクトが分かれていなかった点、接頭辞が他のプロジェクトの管理しているVMと勘違いさせてしまう可能性のある点はこの問題の発生の可能性を増やしてしまった要因でした。また削除するときにも監査ログ等からどのユーザが作成したリソースであるか確認し、削除するとしてもディスクのスナップショット等を取得後に行うべきである点は反省点でした。
得られた知見(まとめ)
名前の混同は一歩間違えれば障害を引き起こしてしまう
(特にリソースが共存しうるクラウドのプロジェクト)削除は最終手段。まずは停止したりスナップショットを取って万が一必要だった際にすぐに戻せるようにするべき。
教訓3: 長期運用するサービスではある程度動かしたらメトリクスを一度眺めるべき
タイムライン
リリースから数日すると比較的安定しているといえる時間が増えてきました。しかし、十数時間すると突然「AIあんの」がダンマリしてしまう時が起きてしまいます。
Unity側で複数のリクエストを並列に処理している部分がかなり複雑になっており、デッドロックになってしまう部分があるのではないかと当初は疑っていました。「AIあんの」がダンマリしてしまった際には、毎回Unity側の再起動、Pythonサーバ側の再起動を1日に一回は行っている状況でした。

「AIあんの」が黙ってしまうタイミングでゼロになるタイミングがあるのが見て取れた
当初、「こういうこともあるかな」とあまり気に留めていなかったのですが、障害復旧時にPythonサーバにSSHしようとすると、SSH先のターミナル画面が表示されるまでが少し遅い気がしていたのです。
実は、サーバ側のメモリリークによってスワップ領域が使われるようになり、サーバがとても遅くなりリクエストがタイムアウトしていたというのが原因でした。
実際、リリース以降のVM上の利用可能メモリ量のグラフを確認すると、単調に減っている部分があるのがわかります。

0まで落ちてしまったタイミングがいくつかあるのが分かる
Pythonサーバ側も突然の再起動は特に問題ないように設計されており、Unity側もサーバが応答できなくなってもバックオフリトライを行うように設計されていました。そのため、コンテナ等でメモリ制限等をしていればOOMでプロセスがキルされても自動的に復活するはずでした。
今回のVMにはスワップが設定されており、コンテナ化等せず単にPythonファイルを実行するという形で起動していただけでメモリ制限の限界に達してもサーバは不安定のまま動作し続け自動回復することができなかったのです。
その後、Azure上でアラートを「閾値以上メモリを使ったとき」、「ネットワーク使用量が指定期間指定量を下回ったとき」設定し、技術チームにSMS経由で飛ばすように構成しました。コンテナ化なども行いたかった点ではありますが投票日まで日数が少ないこと、メモリ利用量だけ気を付けて適宜再起動させれば安定していることからこのままの運用としました。
上手くいったこと・上手くいかなかったこと
アラートが十分に構成されていない中で、比較的見ているタイミングで障害が発生していたので即座に対応ができた点はうまく行っていた。教訓1の問題のおかげでAzure上にVMを構築してモニタリングできる環境が副次的に整っていたのはとてもうまく行った点であった。
よくわからないが何らかのバグがありそう、しかし再起動すれば治るから放置という状態のまま、サーバ側の基本的なメトリクスを確認しなかったのは問題の把握に時間がかかった要因であった。
得られた知見(まとめ)
しばらく運用するVMなどは、ひとまずメトリクスをながめてみると案外気が付いていない時間経過で障害に発生する問題に気が付ける可能性がある
ローカル環境で稼働させ続けることができるアプリケーションだとしても、とりあえずクラウドに移せば可観測性が確保でき、アラート等の設定もできて便利。
その他全体的な反省点
以下はその他の点の反省点の雑多なリストです。
上手くいったこと
リリース直前にUnity側のエラーハンドリングを改善していたのはとても良かった。すべてのAPIの呼び出し部分でリトライが実装されていたので、サーバの更新を裏側でやっても、ユーザ側に見えることなく更新ができた。終盤では様々な設定をUnityからサーバ側に移行していて、これによりユーザにダウンタイムが見えずに更新ができるようになっていた。
上手くいかなかったこと、考えられる改善点
Unity側のログの可観測性がとても低かった。配信PC側でファイル等に書き出し、fluentbit等でクラウドに送る運用等を想定出来たら様々な問題の解決が早かったと思える。
Unity周りの更新にはどうしても配信のダウンタイムが生じてしまい、自分がOBS周りに慣れていなかったこともあり、これを最小限にするため複数の変更をまとめて更新していた。このため、UIがズレていたり、音量の差が大きい等UXに直結する問題でも解決には時間がかかった。
音声合成タスクのキューの処理時間や、コメントの数など様々なメトリクスを集計したかったが、一部Unity側に閉じていた部分があり障害時に参考にすることができなかった。Prometheus等をホストしておいて気軽にメトリクスを書き込める場があれば、手軽に可観測性は増やせたと思われる。
VMよりも、早めにアプリケーションをコンテナ化してコンテナ用のマネージドサービスを使った方が管理はかなり簡略化できて、デプロイは簡素になりアラート等も設定が楽になったと思えた。
回線やマシン自体のとても長い連続稼働時間により、配信環境が安野たかひろ個人PCというのが不安な要素であり続けた。Azure上で配信環境を作ろうとしたが、直近に作られたアカウントであったためかGPUのクォータを増やせず結局断念した。選挙でクラウドサービスを使う場合には、クラウドのアカウント等を作って本番まで短い時間に投入されがちであると思われるが、選挙期間よりも前からクラウドを利用してGPUが必要な場合にはあらかじめリクエストしておいた方がよい。
おわりに
いかがでしょうか。
システム障害はできる限り起こってほしくないものですが、起こった反省は次に生かしてより安定したサービスを実現することができるようになっていきます。
社会がより一層デジタルに依存することを避けられない中で、リーダーが発生した問題を理解できない事は今後より一層大きなリスクになっていくのではないかと考えています。
様々なセンシティブな情報が都のシステムで管理されており、これからも一層増えることでしょう。残念ながら、大なり小なりインシデントは長期的に見れば絶対に発生する問題です。そんなとき、原因をしっかり理解して、自分の言葉で再発防止策を説明できる、そんなデジタルに明るい都知事には安心を感じませんか?
#安野たかひろ を都知事に
最新情報は、本人・事務所の公式X(Twitter)アカウントをフォローしてご覧ください!
安野たかひろ事務所(@annotakahiro24)
安野たかひろ本人(@takahiroanno)
また、活動資金として献金のご協力も引き続き賜っております。いただいたご献金は大切に使わせていただきます。
▼ご献金はこちら